经过预处理后的源文件,褪去一切包装,注释被删除,预处理命令也基本上被处理掉,剩下的就是 C 代码了。接下来的第二步,就进入到编译阶段。编译阶段主要分为两步:第一步,编译器调用一系列解析工具分析这些 C 代码,将 C 源文件编译为汇编文件;第二步,通过汇编器将汇编文件汇编成可重定位的目标文件。
从 C 文件到汇编文件
一个汇编文件是以段为单位来组织程序的:代码段、数据段、BSS 段等,各个段之间相互独立,并且其和二进制目标文件的组织结构已经很接近了,因为汇编指令是二进制指令的助记符,只不过汇编语言的程序结构需要使用各种伪操作来组织,汇编文件经过汇编器汇编后,处理掉各种伪操作命令,就是二进制目标文件了。
从 C 源文件到汇编文件的转换,起始就是将 C 文件中的程序代码块、函数转换为汇编程序中的代码段,将 C 程序中的全局变量、静态变量、常量转换为汇编程序中的数据段、只读数据段。总体来讲,编译过程可以分为以下 6 步:
- 词法分析
- 语法分析
- 语义分析
- 中间代码生成
- 汇编代码生成
- 目标代码生成
词法分析
主要用来解析 C 程序语句。词法分析一般会通过词法扫描器从左到右,一个字符一个字符地读入源程序,通过有限状态机解析并识别这些字符流,将源程序分解为一系列不能再分解的记号单元 —— token。
token 是字符流解析过程中有意义的最小记号单元,常见的 token 如下:
- C 语言的各种关键字:int、float、for、while、break 等。
- 用户定义的各种标识符:函数名、变量名、标号等。
- 字面量:数字、字符串等。
- 运算符:C 语言标准定义的 40 多个运算符。
- 分隔符:程序结束符分号、for循环中的逗号等。
语法分析
语法分析是对前一阶段产生的 token 序列进行解析,看是否能构建成一个语法上正确的语法短语(程序、语句、表达式等)。语法短语用语法树表示,是一种树型结构,不再是线性序列。语法分析工具在对 token 序列分析过程中,如果发现不能构建语法上正确的语句或表达式,就会报语法错误。
语义分析
语法分析仅仅对程序做语法检查,对程序、语句的真正意义不了解,而语义分析主要对语法分析输出的各种表达式、语句进行检查,看看有没有错误。如果你传递给函数的实参与函数声明的形参类型不匹配,或者你使用了一个未声明的变量,或者除数为零了,break 在循环语句或 switch 语句之外出现了,或者在循环语句之外发现了 continue 语句,一般都会报语义上的错误或警告。
生成中间代码
在语法分析阶段输出的表达式或程序语句,还是以语法树的形式存储,我们需要将其转换为中间代码。中间代码是编译过程中的一种临时代码,常见的有三地址码、P-代码。
中间代码和语法树相比,有很多优点:中间代码是一维线性结构,类型伪代码,编译器很容易将中间代码翻译成目标代码。
jiaming@jiaming-pc:~/Documents/CSDN_Project$ cat main2.c
int main(void)
{
int sum = 0;
int a = 2;
int b = 1;
int c = 1;
sum = a + b / c;
return 0;
}
jiaming@jiaming-pc:~/Documents/CSDN_Project$ arm-linux-gnueabi-gcc -fdump-tree-gimple main2.c
jiaming@jiaming-pc:~/Documents/CSDN_Project$ cat main2.c.005t.gimple # 自动生成同名文件
main ()
{
int D.4205;
{
int sum;
int a;
int b;
int c;
sum = 0;
a = 2;
b = 1;
c = 1;
_1 = b / c;
sum = a + _1;
D.4205 = 0;
return D.4205;
}
D.4205 = 0;
return D.4205;
}
C 程序语句 sum=a+b/c; 编译为三地址码后,就变成了上面所示的类似伪代码的语句。中间码一般和平台是无关的,如果你想将 C 程序编译为 X平台下的可执行文件,那么最后一步就是根据 X86 指令集,将中间代码翻译为 X86 汇编程序;如果你想编译成 ARM 平台上运行的可执行文件,那么就要参考 ARM 指令集,根据 ATPCS 规则分配寄存器,将中间代码翻译成 ARM 汇编程序。
jiaming@jiaming-pc:~/Documents/CSDN_Project$ arm-linux-gnueabi-gcc -S main2.c
jiaming@jiaming-pc:~/Documents/CSDN_Project$ cat main2.s # 自动生成该后缀文件
.arch armv5t
.eabi_attribute 20, 1
.eabi_attribute 21, 1
.eabi_attribute 23, 3
.eabi_attribute 24, 1
.eabi_attribute 25, 1
.eabi_attribute 26, 2
.eabi_attribute 30, 6
.eabi_attribute 34, 0
.eabi_attribute 18, 4
.file "main2.c"
.text
.global __aeabi_idiv
.align 2
.global main
.syntax unified
.arm
.fpu softvfp
.type main, %function
main:
@ args = 0, pretend = 0, frame = 16
@ frame_needed = 1, uses_anonymous_args = 0
push {
fp, lr}
add fp, sp, #4
sub sp, sp, #16
mov r3, #0
str r3, [fp, #-20]
mov r3, #2
str r3, [fp, #-16]
mov r3, #1
str r3, [fp, #-12]
mov r3, #1
str r3, [fp, #-8]
ldr r1, [fp, #-8]
ldr r0, [fp, #-12]
bl __aeabi_idiv
mov r3, r0
mov r2, r3
ldr r3, [fp, #-16]
add r3, r3, r2
str r3, [fp, #-20]
mov r3, #0
mov r0, r3
sub sp, fp, #4
@ sp needed
pop {
fp, pc}
.size main, .-main
.ident "GCC: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0"
.section .note.GNU-stack,"",%progbits
汇编过程
汇编过程是使用汇编器将前一阶段生成的汇编文件翻译成目标文件。汇编器的主要工作就是参考 ISA 指令集,将汇编代码翻译成对应的二进制指令,同时生成一些必要的信息,以 section 的形式组装到目标文件中,后面的链接过程会用到这些信息,汇编的流程主要包括词法分析、语法分析、指令生成等过程。
编译器在编译一个项目时,是以 C 源文件为单位进行编译的,每一个源文件经过编译,生成一个对应的目标文件(main.c --> main.o)。 main.o 目标文件是不可执行的,属于可重定位的目标文件,要经过链接器重定位、链接后才能组装成一个可执行的目标文件 a.out。
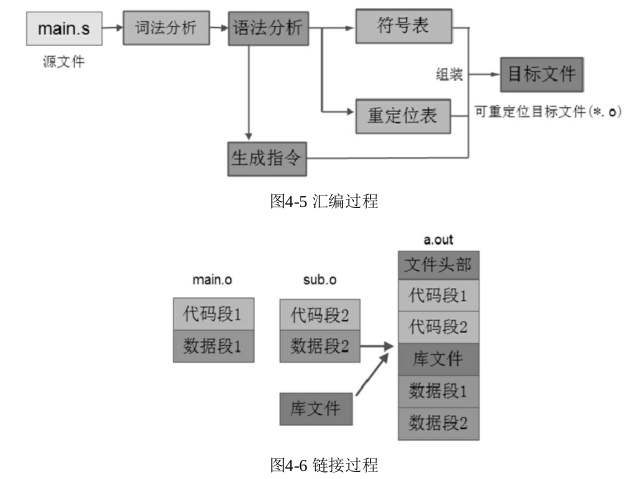
通过编译生成的可重定位目标文件,都是以零地址为链接起始地址进行链接的。编译器在将源文件翻译成可重定位目标文件的过程中,将不同的函数编译成二进制指令后,是从零地址开始依次将每一个函数的指令序列存放到代码段中,每个函数的入口地址也就从零地址开始依次往后偏移。
仅仅汇编的命令:arm-linux-gnueabi-gcc -c main.c。
使用 readelf 命令查看 main.o 目标文件:
jiaming@jiaming-pc:~/Documents/CSDN_Project$ readelf -S main.o
There are 12 section headers, starting at offset 0x354:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 00000000 000034 00005c 00 AX 0 0 4
[ 2] .rel.text REL 00000000 0002c0 000030 08 I 9 1 4
[ 3] .data PROGBITS 00000000 000090 000008 00 WA 0 0 4
[ 4] .bss NOBITS 00000000 000098 000004 00 WA 0 0 4
[ 5] .rodata PROGBITS 00000000 000098 000010 00 A 0 0 4
[ 6] .comment PROGBITS 00000000 0000a8 00002c 01 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 00000000 0000d4 000000 00 0 0 1
[ 8] .ARM.attributes ARM_ATTRIBUTES 00000000 0000d4 00002a 00 0 0 1
[ 9] .symtab SYMTAB 00000000 000100 000160 10 10 16 4
[10] .strtab STRTAB 00000000 000260 00005d 00 0 0 1
[11] .shstrtab STRTAB 00000000 0002f0 000061 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
y (purecode), p (processor specific)
main.o 目标文件在编译时,都是以零地址为基地址进行代码段的组装。在每个可重定位目标文件中,函数或变量的地址起始就是它们在文件中相对于零地址的偏移。在后面的链接过程中,链接器在将各个目标文件组装在一起时,各个目标文件的参考地址就发生了变化,那么这个目标文件内的函数或变量的地址也要随之更新,否则就无法通过函数名去引用函数,无法通过变量名去引用变量。
链接器将各个目标文件组装在一起后,需要重新修改各个目标文件中的变量或函数的地址,这个过程一般称为重定位。将需要重定位的符号(函数名/变量名)收集生成重定位表,以 section 的形式保存到每个可重定位目标文件中就可以了。
main.o 中的 main 函数引用了 sub.o 中的 add 和 sub 函数。在链接器组装的过程中,add 和 sub 函数的地址发生了变化;在链接器组装之后,需要重新计算和更新 add 和 sub 函数的新地址,这个过程就是重定位。
符号表与重定位表
符号表和重定位表是非常重要的两个表,这两个表为链接过程提供各种必要的信息。
符号表
在汇编阶段,汇编器会分析汇编语言中各个 section 的信息,收集各种符号,生成符号表,将各个符号在 section 内的偏移地址也填充到符号表内。符号表主要用来保存源程序中的各种符号的信息,包括符号的地址、类型、占用空间的大小等。这些信息一方面可以辅助编译器作语义检查,看源程序是否有语义错误;另一方面也可以辅助编译器编译代码的生成,包括地址与空间的分配、符号决议、重定位等。
查看符号表:
jiaming@jiaming-pc:~/Documents/CSDN_Project$ readelf -s main.o
Symbol table '.symtab' contains 22 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 00000000 0 NOTYPE LOCAL DEFAULT UND
1: 00000000 0 FILE LOCAL DEFAULT ABS main.c
2: 00000000 0 SECTION LOCAL DEFAULT 1
3: 00000000 0 SECTION LOCAL DEFAULT 3
4: 00000000 0 SECTION LOCAL DEFAULT 4
5: 00000000 0 NOTYPE LOCAL DEFAULT 3 $d
6: 00000000 0 SECTION LOCAL DEFAULT 5
7: 00000000 0 NOTYPE LOCAL DEFAULT 5 $d
8: 00000000 0 NOTYPE LOCAL DEFAULT 1 $a
9: 00000054 0 NOTYPE LOCAL DEFAULT 1 $d
10: 00000000 4 OBJECT LOCAL DEFAULT 4 uninit_local_val.4612
11: 00000000 0 NOTYPE LOCAL DEFAULT 4 $d
12: 00000004 4 OBJECT LOCAL DEFAULT 3 local_val.4611
13: 00000000 0 SECTION LOCAL DEFAULT 7
14: 00000000 0 SECTION LOCAL DEFAULT 6
15: 00000000 0 SECTION LOCAL DEFAULT 8
16: 00000000 4 OBJECT GLOBAL DEFAULT 3 global_val
17: 00000004 4 OBJECT GLOBAL DEFAULT COM uninit_val
18: 00000000 92 FUNC GLOBAL DEFAULT 1 main
19: 00000000 0 NOTYPE GLOBAL DEFAULT UND add
20: 00000000 0 NOTYPE GLOBAL DEFAULT UND sub
21: 00000000 0 NOTYPE GLOBAL DEFAULT UND printf
符号表中的每一个符号,都有符号值和类型。符号值本质上是一个地址,可以是绝对地址,一般出现在可执行目标文件中;也可以是一个相对地址,一般出现在可重定位目标文件中。符号的类型主要有以下几种:
- OBJECT:对象类型,一般用来表示我们在程序中定义的变量。
- FUNC:关联的是函数名或其他可引用的可执行代码。
- FILE:该符号关联的是当前目标文件的名称。
- SECTION:表明该符号关联的是一个 section,主要用来重定位。
- COMMON:表明该符号是一个公用块数据对象,是一个全局弱符号,在当前文件中未分配空间。
- TLS:表明该符号对应的变量存储在线程局部存储中。
- NOTYPE:未指定类型,或者目前还不知道该符号类型。
如果在一个 C 源文件中,我们引用了在其他文件中定义的函数或全局变量,编译器也不会报错,只需要在调用之前声明即可,编译器就会认为你引用的这个全局变量或函数可能在其他文件、库中定义,在编译阶段暂时不会报错。在后面的链接过程中,链接器会尝试在其他文件或库中查找你引用的这个符号的定义,如果真的找不到才会报错。此时的错误类型是链接错误。
重定位表
编译器在给每个目标文件生成符号表的过程中,如果在当前文件中没有找到符号的定义,也会将这些符号收集在一起并保存到一个单独的符号表中,以待后续填充,这个符号表就是重定位符号表。如在 main.o 的符号表(.symtab)中看到的:
19: 00000000 0 NOTYPE GLOBAL DEFAULT UND add
20: 00000000 0 NOTYPE GLOBAL DEFAULT UND sub
21: 00000000 0 NOTYPE GLOBAL DEFAULT UND printf
add 和 sub 这两个符号的信息处于未定义状态(NOTYPE),需要后续填充。在 main.o 中会使用一个重定位表 .rel.text 记录这些需要重定位的符号:
jiaming@jiaming-pc:~/Documents/CSDN_Project$ readelf -r main.o
Relocation section '.rel.text' at offset 0x2c0 contains 6 entries:
Offset Info Type Sym.Value Sym. Name
00000014 0000131c R_ARM_CALL 00000000 add
00000024 0000141c R_ARM_CALL 00000000 sub
00000034 0000151c R_ARM_CALL 00000000 printf
00000040 0000151c R_ARM_CALL 00000000 printf
00000054 00000602 R_ARM_ABS32 00000000 .rodata
00000058 00000602 R_ARM_ABS32 00000000 .rodata
在 .rel.text 中,我们可以看到需要重定位的符号 add、sub 以及库函数 printf,重定位表中的这些符号所关联的地址,在后面的链接过程中经过重定位,会更新为新的实际地址。