1、时间的重要性,弄明白为什么需要有序?
当iot设备上传的轨迹数据是乱序时,那业务在处理时就会有误,如计算超速就不准确。在直播带货中,每小时计算销售金额,并给主播按时结算报酬,如果时间乱了,把19:00的算到20:00了,那就是问题了。
对于流计算中的乱序,应该怎么排序呢?
在flink中,流计算的数据是事件,每个事件都会有自己的产生时间(如:每个gps点都会有自己的时间),所以流计算中的排序是按时间维度,Flink也是按时间排序来实现的。
2、Flink时间类型

1)事件产生的时间(Event Time)
2) 事件进入Flink时间(Ingestion Time)
3) 事件处理时间(Processing Time)
提供最简单的时间,有极佳的性能,在分布式环境中确定性不高。
对于上面3种时间,Ingestion Time和Processing Time都是业务进入Flink后产生的,不会有乱序的影响。Event Time是在外部产生的,当事件进入Flink的时间顺序与产生的时间顺序不一样,那就是乱序问题。
3、其它乱序产生
1)业务产生的乱序:
比如对于Kafka,同一个设备的数据,分布在不同的分区中,同时flink对不同的分区处理速度不一样,就导致乱序了。
业务分区规则和进入flink进行业务统计的分组规则不一致的乱序。(业务按日期分区,flink按类型分组统计)
2)程序误用的乱序

1、数据source是有序的
2、在通过rebalance(随机)转移动不同的map
3、map后面直接sink到db,那业务数据顺序就乱了
对于如上的算子乱序,怎么解决呢?
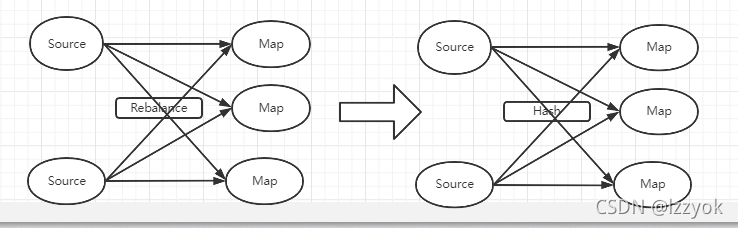
ds.setParallelism(3).keyBy(...).map(...).setParallelism(3)通过keyBy算子,按业务属性进行分组,以达到顺序的目的。
总结:在Flink中,只要shuffle的机制是rebalance,就会有乱序的问题。而对于乱序对业务是否有影响,需要根据场景考虑。