❝本文详细介绍了在上游使用处理时间语义的 flink 任务出现故障后,重启消费大量积压在上游的数据并产出至下游数据乱序特别严重时,下游 flink 任务使用事件时间语义时遇到的大量丢数问题以及相关的解决方案。❞
本文分为以下几个部分:
-
「1.本次踩坑的应用场景」
-
「2.应用场景中发生的丢数故障分析」
-
「3.待修复的故障点」
-
「4.丢数故障解决方案及原理」
-
「5.总结」
应用场景
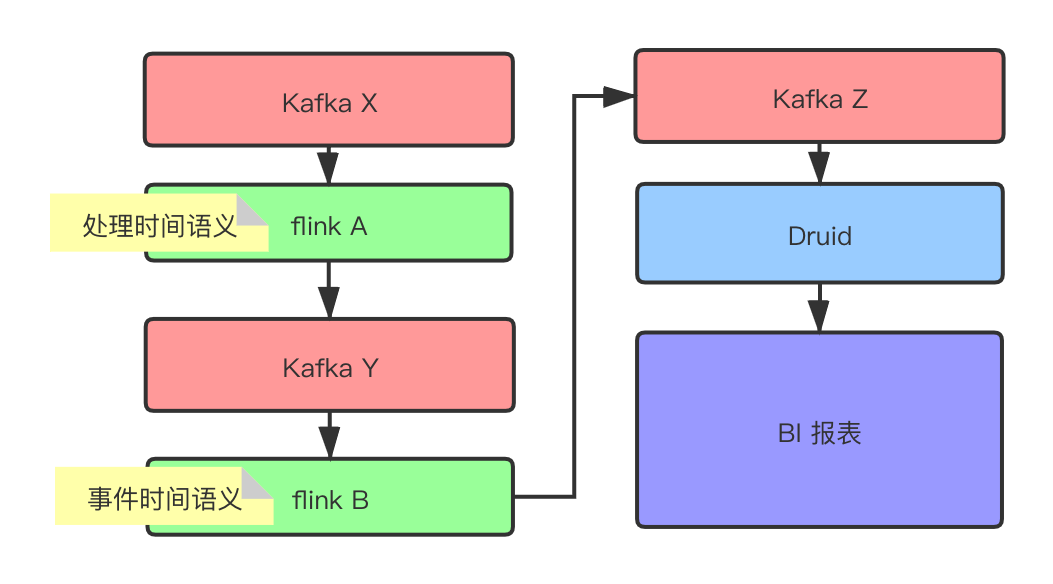
应用场景如下:
-
「flink 任务 A」 以「处理时间」语义做过滤产出新增 xx 明细数据至 「Kafka Y」
-
「flink 任务 B」 以「事件时间」语义消费 「Kafka Y」 做窗口聚合操作产出分钟级别聚合指标至 「Kafka Z」
-
「Kafka Z」 实时导入至 「Druid」 以做即时 OLAP 分析,并且展示在 BI 应用看板
丢数故障分析
简要介绍下这次生产中故障场景。整条故障追踪链路如下:
故障一:
-
收到报警反馈 「flink 任务 A」 入口流量为 0
-
定位 「flink 任务 A」 中某个算子的故障导致整个 job 卡住
-
导致此 「flink 任务 A」 上游 「kafka X」 积压了大量数据
-
重启 「flink 任务 A」后,消费大量积压在上游 「kafka X」 数据完成,任务恢复正常
故障一从而引发下游的故障二:
-
由于 「flink 任务 A」 使用了「处理时间」语义处理数据,并且有过滤和 keyBy 分桶窗口逻辑,在重启后消费大量积压在上游的数据时,导致 sink rebalance 后产出到下游 「kafka Y」 各个分区数据中的 server_timestamp 是乱序的
-
下游 「flink 任务 B」 在消费 「Kafka Y」 时使用了「事件时间」语义处理数据,并且使用了数据中的 server_timestamp 作为「事件时间」时间戳
-
「flink 任务 B」 消费了乱序很严重的数据之后,导致在窗口聚合计算时丢失了大量数据
-
最终展示在 BI 应用中的报表有丢失数据的情况

待修复的故障点
-
1.「flink 任务 A」 的稳定性故障,这部分解决方案暂不在本文中介绍
-
2.「flink 任务 B」 消费上游乱序丢数故障,解决方案在下文介绍
解决方案以及原理
丢数故障解决方案
解决方案是以下游 「flink 任务 B」 作为切入点,直接给出 「flink 任务 B」 的 sql 代码解决方案,java code 也可以按照这个方案实现,其本质原理相同。下文进行原理解释。
SELECT
to_unix_timestamp(server_timestamp / bucket) AS timestamp, -- format 成原有的事件时间戳
count(id) as id_cnt,
sum(duration) as duration_sum
FROM
source_table
GROUP BY
TUMBLE(proctime, INTERVAL '1' MINUTE),
server_timestamp / bucket -- 根据事件时间分桶计算,将相同范围(比如 1 分钟)事件时间的数据分到一个桶内
复制代码解决方案原理
首先明确一个无法避免的问题,在不考虑 watermark 允许延迟设置特别大的情况下,只要上游使用到了处理时间语义,下游使用事件时间语义,一旦上游发生故障重启并在短时间内消费大量数据,就不可避免的会出现上述错误以及故障。
在下游消费方仍然需要将对应事件时间戳的数据展示在 BI 平台报表中、并且全链路时间语义都为处理时间保障不丢数的前提下。解决方案就是在聚合并最终产出对应事件时间戳的数据。
最后的方案如下: 整条链路全部为处理时间语义,窗口计算也使用处理时间,但是产出数据中的时间戳全部为事件时间戳。 在出现故障的场景下,一分钟的窗口内的数据的事件时间戳可能相差几个小时,但在最终窗口聚合时可以根据事件时间戳划分到对应的事件时间窗口内,下游 BI 应用展示时使用此事件时间戳即可。
❝注意:sql 中的 bucket 需要根据具体使用场景进行设置,如果设置过于小,比如非故障场景下按照处理时间开 1 分钟的窗口,bucket 设为 60000(1 分钟),那么极有可能,这个时间窗口中所有数据的 server_timestamp 都集中在某两分钟内,那么这些数据就会被分到两个桶(bucket)内,则会导致严重的数据倾斜。
❞
输入数据样例
模拟上述故障,「flink B」 的任务某一个窗口内的数据输入如下。
| server_timestamp | id | duration |
|---|---|---|
| 2020/9/01 21:14:38 | 1 | 300 |
| 2020/9/01 21:14:50 | 1 | 500 |
| 2020/9/01 21:25:38 | 2 | 600 |
| 2020/9/01 21:25:38 | 3 | 900 |
| 2020/9/01 21:25:38 | 2 | 800 |
输出数据样例
按照上述解决方案中的 sql 处理过后,输出数据如下,则可以解决此类型丢数故障。
| timestamp | id_cnt | duration_sum |
|---|---|---|
| 2020/9/01 21:14:00 | 2 | 900 |
| 2020/9/01 21:25:00 | 3 | 2300 |
总结
本文分析了在 flink 应用中:
-
「上游使用处理时间语义的 flink 任务出现故障、重启消费大量积压数据并产出至下游数据乱序特别严重时,下游使用事件时间语义时遇到的大量丢数问题」
-
「以整条链路为处理时间语义的前提下,产出的数据时间戳为事件时间戳解决上述问题」
-
「以 sql 代码给出了丢数故障解决方案样例」