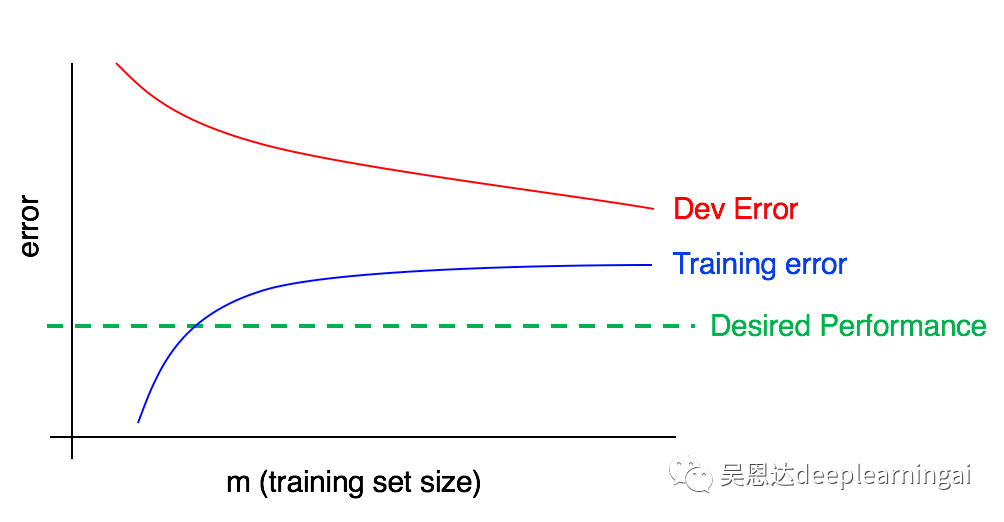
31.解读学习曲线:其他情况
下图反映了高方差,通过增加数据集可以改善。

下图反映了高偏差和高方差,需要找到一种方法来同时减少方差和偏差。
32.绘制学习曲线
情况:当数据集非常小时,比如只有100个样本,这时绘制出来的学习曲线可能噪声非常大。
解决方法:
(1)与其只使用10个样本训练单个模型,不如从你原来的100个样本中进行随机有放回抽样,选择几批(比如3-10)不同的10个样本进行组合。在这些数据上训练不同的模型,并计算每个模型的训练和开发错误,最终计算和绘制平均训练集误差和平均开发集误差。
(2)如果你的训练集偏向于一个类,或许它有许多类,那么选择一个“平衡”子集,而不是从100个样本中随机抽取10个训练样本。例如,你可以确保这些样本中的2/10是正样本,8/10是负样本。更常见的做法是,确保每个类的样本比例尽可能的接近原始训练集的总体比例。
33.为何与人类表现水平进行对比
对于人类擅长的事情,例如图像识别,语音识别等。
(1)易于从认为标签中获取数据。
(2)基于人类直接进行误差分析。
(3)使用人类表现水平来估计最优错误率,并设置可达到的“期望错误率”。
对于人类也不擅长的事情,例如推进书籍电影,股票市场预测。
(1)获取标签数据很难。
(2)人类的直觉难以依靠。
(3)最优错误率和合理的期望错误率难以估计。
34.如何定义人类表现水平
应该用人类的最高水平去衡量人类的水平(即期望误差率)。举例:医学图像疾病诊断,普通人错误率20%,医生10%,专家5%,专家讨论小左2%,此时人类水平应该为2%。
35.超越人类表现水平
举例:语音识别人类错误率是10%,而你的算法错误率是8%,此时已经超越人类,但这时某个子集(即某些方面,如转录语音很快时)人类仍然优于算法,在这些方面仍然可以用前面提到的一些技术进行提升。在语音转录上,仍然可以(1)从输出质量比你的算法高的人那儿获取转录数据。(2)你可以利用人类的直觉来理解,为什么你的系统没能欧识别这些数据,而人类做到了。(3)你可以使用该子集上的人类表现作为期望表现目标。