pandas高级篇
一、向量化函数操作
向量化函数应用 -map(变换数据和创造新变量)
map是作用在 Series 上,是元素级别操作
Series.map(arg,na_action=None)
arg可以是一个函数,对元素做函数变换
也可以是一个dict、series 对元素做数据映射
向量化函数应用 -applymap
applymap 是作用在 dataframe 上,用于对row、column 计算是元素级别的操作
DataFrame.applymap(func,axis=0): func只能是一个函数
func为聚合函数时,对行列进行聚合处理
func为普通函数时,和applymap效果一样
二、pandas 数据运算 / 文件IO
pandas数据运算——一元运算
使用 map、applymap pandas数据运算——汇总运算 mean(axis=None,skipna=None,level=None) skipna:是否跳过NAN值 level: 对于多层索引有效pandas 文件读取/存储(IO)
pd.read_csv(filepath_or_buffer="./train_data.txt") 将数据储存到csv:to_csv

三、多层索引
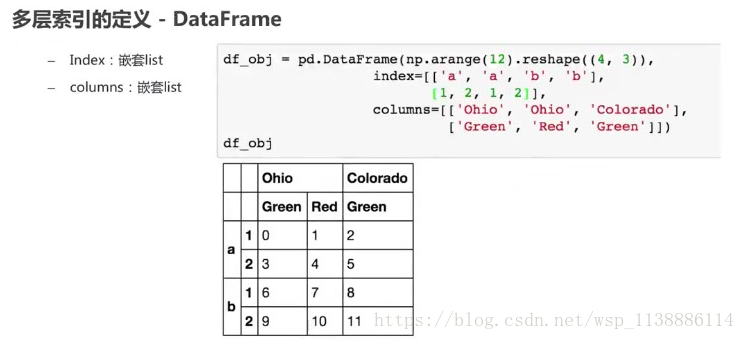
多层索引的定义
-series -index参数为嵌套list
-DataFrame - index:嵌套list - column:嵌套list
-将已有列设为多层索引 set_index(keys,drop=True,append=False,inplace=False) - 是否保留原来索引 - Drop 是否指定为索引的列删除多层索引的操作
- 交换分层 swaplevel(i=-2,j=-1,axis=0) i,j 需要被交换索引名称或者位置(从0开始) 指定某个分层进行索引排序 sort_index(axis=0,level=None,ascending=True,inplace=False,sort_remaining=True) 数据选择 df.loc[([],[]),([],[],[])] 通过内嵌的list 元组,定位到访问数据 常用函数 -sum sum(axis=None,skipna=None,level=None) 指定level后,会在此level的基础上进行聚合

四、pandas数据变形–分组与聚合
agg(func)
agg实现了apply+combine
func取内置聚合函数(如max,min)
func取自定义函数
func取函数列表
func取key为列名、value为函数的dict
结果
行索引为groupby 的by值
列名:
当func为一个函数时,列名为原始列名
当func有多个函数时,多层索引(外层为原始列名,内层为函数列表)
func取自定义函数:
默认传入参数为分组后的dataframe对象的一列,一列列处理。
groupby函数
groupby(by=None)
groupby实现了split过程
df.groupby("key1").mean() #指定列分组,Na值行丢掉
五、pandas数据变形-连接与关联
关联几种方式:
轴关联:
pd.concat 沿轴方向将多个对象合并到一起 Append: pd1.append(df2,ignore_index=False,verify_integrity=False) concat简化版本,axis=0,join="outer"轴关联 -concat series
Axis=0 :将不同对象行连接,用列名关联,可以使用 ignore_index。inner、outer的效果一致 Axis=1 :将不同对象列连接,用行索引关联,行索引不会重复。inner、outer的效果不一样轴关联 -concat series
Axis=0 :将不同对象行连接,用列名做join 进行关联 pd.concat([df_obj1,df_obj2],axis=0,join="outer") pd.concat([df_obj1,df_obj2],axis=0,join="inner")列关联 -merge (合并)
merge() 根据单个或者多列进行join 关联,将不同的 Dtaframe 的行连接起来 how 取 outer 保留两边所有的行 right_index 与 left_index 的使用 right_on 与 left_on 的使用 suffixes 的使用


六、pandas-数据重塑(行列旋转)
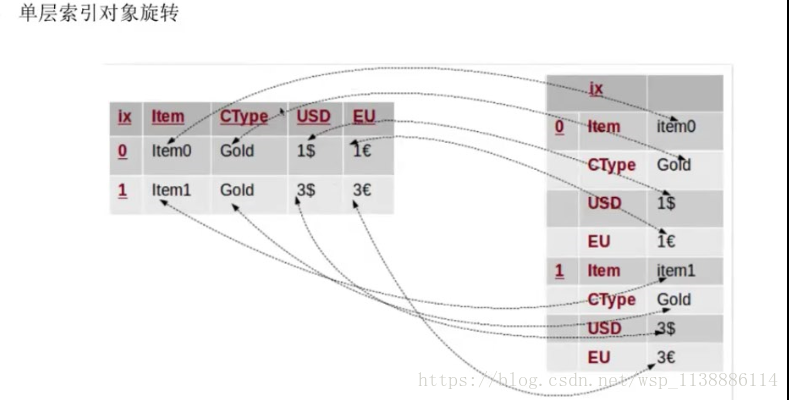
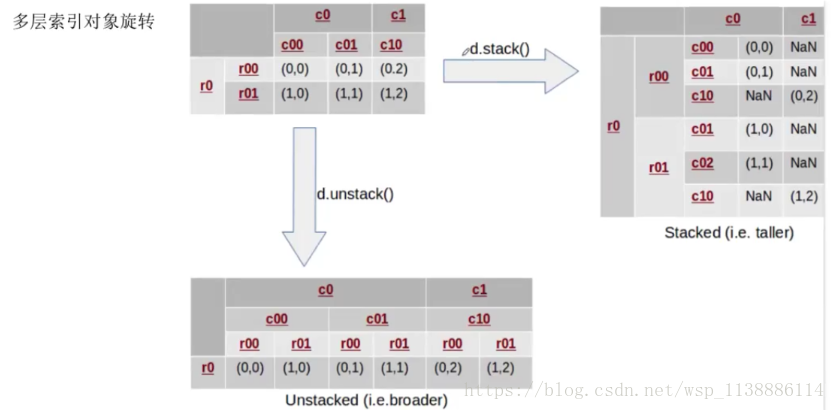
6.1 轴向旋转:stack、unstack
stack(level=-1,dropna=True) 将数据的列旋转为行 level:指定旋转索引等级,默认最里层索引进行旋转 unstack(level=-1,fill_value=None) 将数据的行旋转为列 level:指定旋转索引等级,默认最里层索引进行旋转单层索引对象旋转:
多层索引对象旋转:
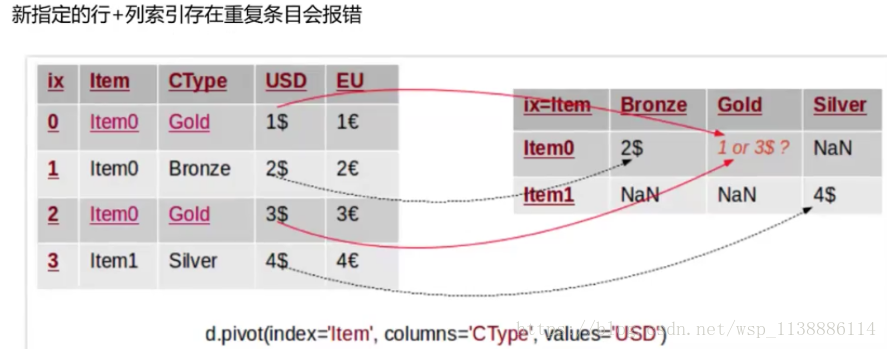
6.2 行旋转为列:pivot
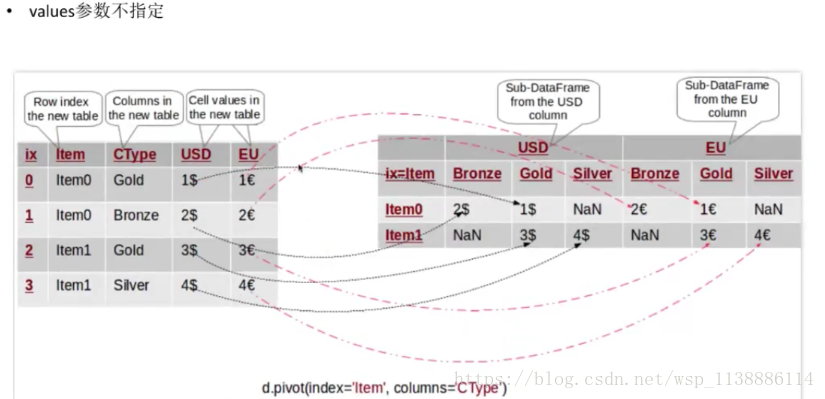
需要以某列为主视角观察数据 pivot(index=None,column=None,values=None) index:新对象行索引,指定原对象的某一列,不填默认为原来的index column:新对象列索引,指定原对象的某一列 values:新对象值,如果没有指定剩余列都默认为新对象的值, 并与 column 指定的列生成多层索引

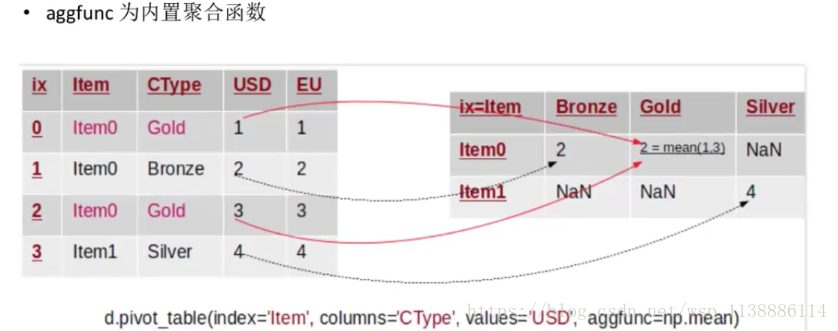
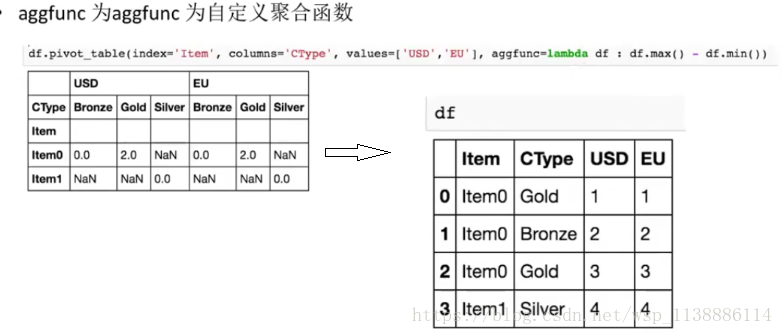
6.3 行旋转为列并聚合:pivot_table
pivot_table(index=None,column=None,values=None,aggfunc="mean",fill_value=None,dropna=True,margins_name="All") index:新对象行索引 指定原对象的某一列,或者多列 也可以是一个新的列表或者新的嵌套列表,也可以为一组值组成的list column:新对象列索引 指定原对象的某一列,或者多列 也可以是一个新的列表或者新的嵌套列表,也可以为一组值组成的list values:新对象值,如果没有指定剩余列都默认为新对象的值,并与 column 指定的列生成多层索引 aggfunc values 值的汇总函数,默认为mean,始终做聚合操作 aggfunc: 取内置聚合函数(max,min) 取自定义函数 取函数列表 取key为列名、value为函数的dict margins_name