一.组织病理学
使用癌症分期,分子特征或临床变量已经可以完成风险分层。然而,改善预后见解是研究的活跃领域。预后指的是患者接受标准治疗后可能发生的结果,例如患者肿瘤复发,发生远处转移或死亡的可能性。
H&E整个图像图像很大,并且组织外观也多种多样。与查找有丝分裂或分割组织类型的方法不同,病理学家无法注释组织的哪些区域与患者的预后相关-至少没有很高的确定性。肿瘤分级是衡量细胞外观的指标,但并不总是衡量预后的良好指标。病理学家对分级的观察也具有很高的观察者间差异。
其他模式如临床数据、基因组学和蛋白质组学也可用于生存模型。Vale-Silva等人训练了一个融合多种数据模式的模型,但发现与只使用临床特征的模型相比,组织学并没有改善该模型[Vale-Silva2020]。Zhong等人也研究了成像和基因表达特征[Zhong2019b]。他们发现,在基因表达的条件下,组织学特征对预后的影响有限;然而,它们的图像特征仅限于手工制作的形态学特征。
Hao等人还试验了整个图像和基因组数据的组合,发现该模型优于仅使用单一模式的模型[Hao2020]。Chen等人也得出了类似的结论[Chen2020]。他们测试了多种建模策略:基因组特征和整个图像,CNN和图表CNN模型的组织学。
目前的共识似乎是,以组织学为基础的特征可以促进使用基因组或临床变量的生存模式。然而,成功可能取决于所使用的图像特征、模型类型和数据集,以及其他因素。
Pan-Cancer建模
生存模式也同时适用于多种类型的癌症。wulczynn等人训练了10种癌症类型的生存模型,并评估了他们的模型在每种癌症类型中的预测能力[Wulczyn2020]。Vale-Silva等人训练了横跨33种癌症类型的泛癌症和多模态模型[Vale-Silva2020]。
二.模态融合
1.点乘或者直接追加
此种方式将文本和图像分别进行Embedding,之后将各自的向量进行追加或者点乘。好处是简单方便,计算成本也比较低。
2.模态交叉的方式是最近用得比较多的Transformer。
其好处是利用了Transformer架构,能够更好地进行图像特征和文本特征的表示。缺点是占用空间大,计算成本较高。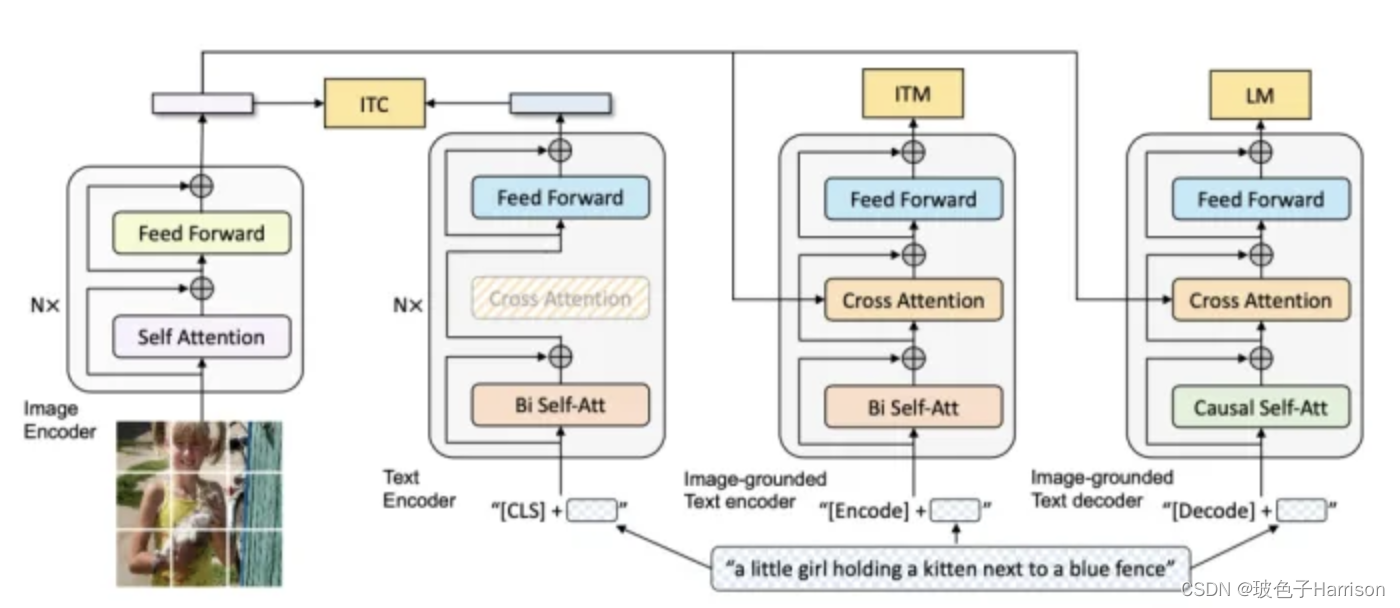
- 多模态的表示学习(multimodal representation):利用多模态的互补性和冗余的方式来表示和总结多模态数据。
- 联合表示:将不同的单模态投影到一个共享的子空间来对特征进行融合。
- 协同表示:每个模态都可以学习单独的表示,但是通过约束进行协调。约束可以通过对抗性的训练,模态编码特征的相似性约束来获取。
- 编解码:在多模态任务转换中,将一种模态映射为另一种模态的。编码器将原模态映射到中间向量,然后通过中间向量生成新模态下的表达。
- 模态映射(translation):将数据从一种模态转换到另一种模态。
- example-based:基于检索的模型是多模态翻译的最简单形式。它们在字典中找到最接近的样本,并将其作为翻译结果。检索可以在单模态空间或中间语义空间进行。
- generative :
- 基于语法的:通过使用语法来限制目标领域来简化任务。它们首先从源模态中检测高层语义,例如图像中的对象和视频中的动作。然后,这些检测结果与基于预定义语法的生成过程合并在一起,以产生目标模态。
- 编码器解码器:将源模态编码为潜在表示,然后由解码器来生成目标模态。即首先将源模态编码成矢量表示,然后使用解码器模块生成目标模态,所有这些都在一个单通道管道中完成。
- 连续生成模型:基于源模态输入流连续生成目标模态,它往往用于序列翻译,并以在线方式在每个时间步上产生输出。这些模型在将序列转换为序列(如从文本转换为语音、从语音转换为文本、从视频转换为文本)时非常有用。
- 模态对齐(alignment)
- 隐式对齐(implicit alignment):隐对齐作为另一个任务的中间(通常是潜在的)步骤,例如,基于文本描述的图像检索可以包括单词和图像区域之间的对齐步骤。
- 显式对齐(explicit alignment): 显式对齐主要通过相似性度量来实现,大多数方法依赖于测量不同形式的子组件之间的相似性作为基本的构建块。
- 多模态融合(multimodal fusion):两种分类方法
- 基于集成的融合方法(aggregation-based):基于聚集的方法通过一定的操作(如平均、连接、自注意力)将多模态子网络组合成单个网络。
- 基于对齐的融合方法(alignment-based):基于对齐的融合方法则采用了一个正则化损失来对齐所有子网络的特征嵌入,同时保持每个子网络进行单独的参数传播。
- Early:早期融合可以学习利用每个模态的低层特征之间的相关性和相互作用。例如在文献3中采用的多项式特征融合递归地将局部关联传输到全局关联来对特征进行融合。
- Late:后期融合使用单峰决策值,并使用一种融合机制进行融合,如平均、投票、基于信道噪声和信号方差的加权,或学习模型。
- Hybrid:混合融合尝试在一个共同的框架中利用上述两种方法的优点。它已成功地用于多模态说话人识别和多媒体事件检测。
- 协同学习(co-learning)协同学习有助于解决某种模态下资源匮乏型的模型训练,提取一种模态数据的信息来协助另一种模态数据的训练。针对不同的数据资源类型可以将协同学习分为以下3种。
- 并行数据(parallel-based):训练数据集中其中一种模态的观测结果直接与其他模态的观测结果相关联。即当多模态观测来自相同的实例时。
- 非平行数据(non-parallel):不要求来自不同模式的观察之间有直接联系。这些方法通常通过使用数据类别重叠来实现共同学习。
- 混合数据(hybrid):在混合数据设置中,两个非平行模态通过共享模态或数据集进行连接。

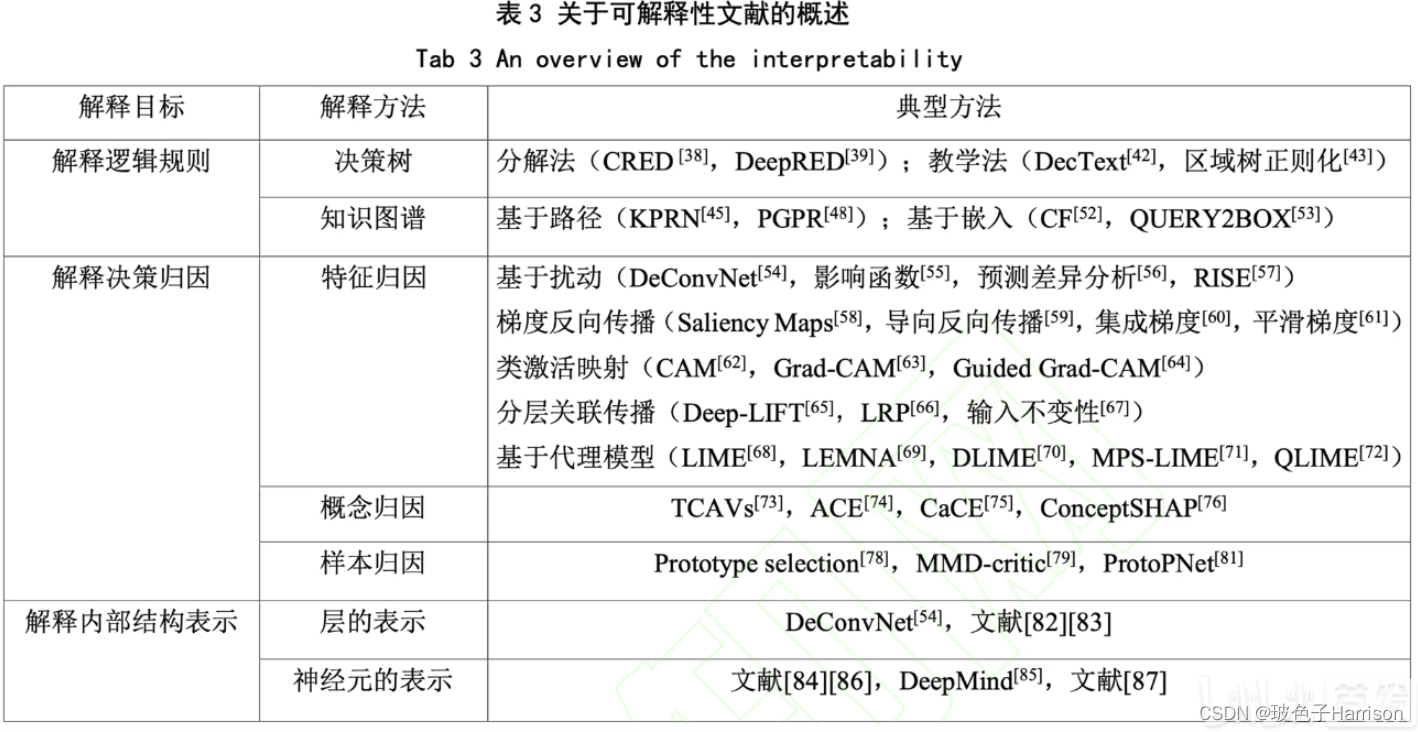
-
激活图:激活图显示输入图像的哪些区域对模型的预测最重要。它们突出显示模型在进行预测时“关注”的图像区域。这有助于解释模型做出特定预测的原因。
-
梯度加权类激活映射 (Grad-CAM):Grad-CAM 是一种生成热图以显示图像中每个像素对于特定类的重要性的技术。这有助于解释模型使用哪些特征进行预测。
-
显着性图:显着性图类似于激活图,但它们显示的输入区域对于模型在多个示例中的决策最为重要。它们可以帮助识别对模型整体预测最重要的特征。
-
LIME:Local Interpretable Model-Agnostic Explanations (LIME) 是一种通过使用更易于解释的更简单模型来近似模型来生成对模型预测的解释的技术。LIME 可以帮助解释模型如何对单个示例进行预测。
-
Integrated Gradients:Integrated Gradients 是一种通过将模型输出的梯度与输入特征相结合来为每个输入特征分配重要性分数的技术。这有助于解释特定输入特征的变化将如何影响模型的预测。
-
t-SNE可视化:t-SNE(t-distributed Stochastic Neighbor Embedding)是一种用于在低维空间中可视化高维数据的技术。它可用于可视化神经网络中不同层的激活,这有助于识别模型正在使用哪些特征进行预测。