判断请求是否成功
assert response.status_code == 200
url 编码
https://www.baidu.com/s?wd=%E7%BC%96%E7%A8%8B%E8%AF%AD%E8%A8%80
字符串格式化的另一种方式
"学习{}编程语言".format("python")
requests模块发送带headers的请求和带参数的请求
发送简单的请求
需求:通过requests向百度首页发送请求,获取百度首页的数据
response = requests.get(url)
response的常用方法:
- response.text
- response.content
- response.status_code
- response.request.headers
- response.headers
In [1]: import requests
In [2]: response = requests.get("http://www.baidu.com")
In [3]: response.status_code
Out[3]: 200
In [4]: assert response.status_code == 200
In [5]: assert response.status_code == 300
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-5-245507ec34d1> in <module>
----> 1 assert response.status_code == 300
AssertionError:
In [6]: response.headers
Out[6]: {'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'Keep-Alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sun, 07 Jul 2019 03:07:48 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:28:23 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
In [7]: response.request.url
Out[7]: 'http://www.baidu.com/'
In [8]: response.url
Out[8]: 'http://www.baidu.com/'
In [9]: response.request.headers
Out[9]: {'User-Agent': 'python-requests/2.22.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
#由于我们的User-Agent不是浏览器,所有返回的内容很少
In [10]: response.content.decode()
Out[10]: '<!DOCTYPE html>\r\n<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn"></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=http://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴 吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write(\'<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=\'+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ \'" name="tj_login" class="lb">登 录</a>\');</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;"> 更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a href=http://ir.baidu.com>About Baidu</a> </p> <p id=cp>©2017 Baidu <a href=http://www.baidu.com/duty/>使用百度前必读</a> <a href=http://jianyi.baidu.com/ class=cp-feedback>意见反馈</a> 京ICP证030173号 <img src=//www.baidu.com/img/gs.gif> </p> </div> </div> </div> </body> </html>\r\n'
In [11]: headers = {"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKi
...: t/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Mobile Safari/537.36"}
#模拟浏览器发送请求
In [13]: response = requests.get("http://www.baidu.com",headers=headers)
In [14]: response.content.decode()
Out[14]: '\ufeff<!DOCTYPE html>\n<html class=""><!--STATUS OK--><head><meta name="referrer" content="always" /><meta charset=\'utf-8\' /><meta name="viewport" content="width=device-width,minimum-scale=1.0,maximum-scale=1.0,user-scalable=no"/><meta http-equiv="x-dns-prefetch-control" content="on"><link rel="dns-prefetch" href="//m.baidu.com"/><script>try {var oldInterval = window.setInterval;window.setInterval = function () {var cb = arguments[0].toString();if (/checkAndRemoveInvalidData|blockBaiduFixed|\\.remove|\\.baidu\\.com/ig.test(cb)) {return;}return oldInterval.apply(window, arguments);};}catch (error) {console.log(error);}</script><link rel="shortcut icon" href="https://gss0.bdstatic.com/5bd1bjqh_Q23odCf/static/wiseindex/img/favicon64.ico" type="image/x-icon"><link rel="apple-touch-icon-precomposed" href="https://gss0.bdstatic.com/5bd1bjqh_Q23odCf/static/wiseindex/img/screen_icon_new.png"/><meta name="format-detection" content="telepho。。。
发送带header的请求
为什么请求需要带上header?
模拟浏览器,欺骗服务器,获取和浏览器一致的内容
header的形式:字典
headers = {“user-agent”: “Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1”}
用法:requests.get(url, headers=headers)
发送带参数的请求
什么叫做请求参数
例一:https://mp.csdn.net/mdeditor/94970791
例二:https://www.baidu.com/s?wd=C&c=b
- 参数的形式:字典
- kw = {‘wd’ : ‘长城’}
- 用法:requests.get(url,params=kw)
01_try_params.py
# coding=utf-8
import requests
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"}
# params = {"wd":"编程语言"}
# url_temp = "https://www.baidu.com/s?"
# #问号结尾可有可无
# #url_temp = "https://www.baidu.com/s"
#
# r = requests.get(url_temp,headers=headers,params=params)
# print(r.status_code)
# print(r.request.url)
url_temp = "https://www.baidu.com/s?wd={}".format("爬虫学习")
url = requests.get(url_temp,headers=headers)
print(url.status_code)
print(url.request.url)
结果
200
https://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB%E5%AD%A6%E4%B9%A0
Process finished with exit code 0
requests请求发送带POST的请求
Request深入
一、送POST请求
哪些地方我们会用到POST请求:
-
登录注册(POST比GET更安全)
-
需要传输大文本内容的时候(POST请求对数据长度没有要求)
所以同样的,我们的爬虫也需要在这两个地方回去模拟浏览器发送post请求用法: response = requests.post("http://www.baidu.com/", data= data, headers= headers) data的形式:字典
二、使用代理ip
-
准备一堆的ip地址,组成ip池,随机选择一个ip来使用
如何随机选择代理ip
{“ip” : ip, “time” : 0}
[{}, {}, {}, {}, {}, {}],对这个ip列表进行排序,按照使用次数进行排序
选择使用次数较少的10个ip,从中随机选择一个 -
检测ip的可用性
可以使用requests添加超时参数,判断ip地址的质量
在线代理ip质量检测的网站
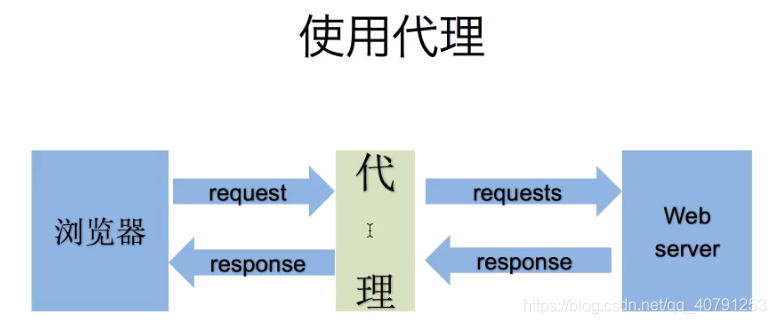
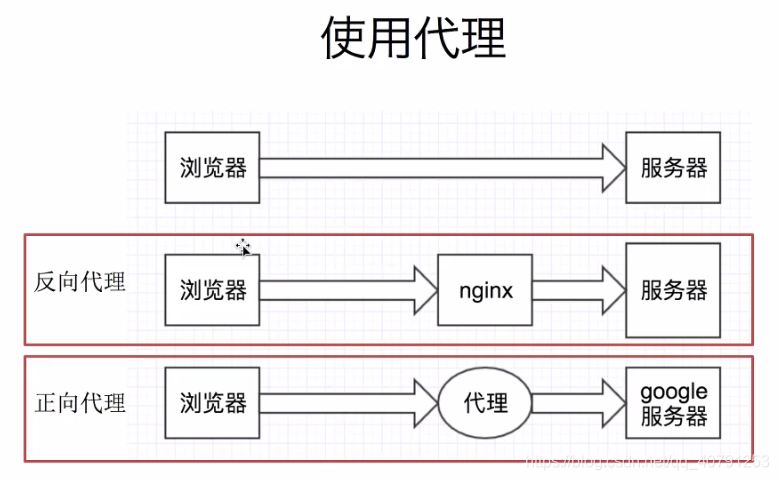
-
用法:
requests.get("http://www.baidu.com", proxies = proxies)
proxies的形式:字典proxies = { "http":"http://12.34.56.79:8080", "https":"http://12.34.56.79:443", } -
为什么爬虫需要使用代理?
- 让服务器以为不是同一个客户端在请求
- 防止我们的真实地址被泄露,防止被追究
三、携带cookie请求
携带一堆cookie进行请求,把cookie组成cookie池
- cookie和session区别:
- cookie数据存放在客户的浏览器上,session数据放在服务器上。
- cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗。
- session会在一定时间内保存在服务器上。当访问增多,会比较占用你的服务器的性能。
- 单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
- 爬虫处理cookie和session
- 带上cookie、session的好处:
- 能够请求到登录之后的页面
- 带上cookie、session的弊端:
- 一套cookie、session往往和一个用户对应
- 请求太快,请求次数太多,容易被服务器识别为爬虫
不需要cookie的时候尽量不去使用cookie
但是为了获取登录之后的页面,我们必须发送带有cookies的请求
- 处理cookies、session请求
requests提供一个叫做session类,来实现客户端和服务端的会话保持
使用方法:
1)==实例化==一个session对象
2)让session发送==get==或者==post==请求
session = requests.session()
response = session.get(url, headers)
使用requests提供的session类来请求登录之后的网站的思路
- 实例后Session
- 先使用session发送请求,登录网站,把cookie保存在session中
- 再使用session请求登陆之后才能访问的网站,session能够自动的携带登录成功时保存在其中的cookie,进行请求
