爬取课程信息,可自定义查找范围
首先声明,不是爬取课程视频内容,只是爬取标题和章节信息
当前(截止于2019/10/15)慕课网免费课程编号总共就只到了1189,在这之后的都会返回404,所以第一个输入填0,第二个输入填1189即可
直接上完整代码,看着可能很复杂,但仔细剖析就能明白,复制过去的代码可能运行失败,原因多半是因为我在改文章内容时缩进混用了tab和4个空格,自行按提示修正即可
from urllib import request
from bs4 import BeautifulSoup
import time
import sys
import re
import os
def mkdir(path):
# 去除首位空格
path=path.strip()
# 去除尾部 \ 符号
path=path.rstrip("\\")
# 路径是否存在
isExists=os.path.exists(path)
if not isExists:
# 不存在则创建目录
os.makedirs(path)
print('创建成功:',path)
return True
else:
print ('目录已存在:',path)
return False
#将文件名非法字符转换为空格
#对每个文件名执行这段代码,因为获取到的文件名非法会报OSError
#如课程343
def validateTitle(title):
#新增\t\n,1166号课程末尾带\t会中断程序
rstr = r"[\/\\\:\*\?\"\<\>\|\t\n]" # '/ \ : * ? " < > |'
# 替换为空格
new_title = re.sub(rstr, " ", title)
return new_title
#爬取出现未考虑到的异常将中断程序,用a方式写入保证处理完异常下次运行
#不覆盖原有数据
def get_not_found_list(nflist):
f = open("不存在的课程.txt",'a')
for l in nflist:
f.write(l)
f.write("\n")
f.write("---------------------------------------------------------\n")
f.close()
def get_not_available_list(nalist):
f = open("已下架的课程.txt",'a')
for l in nalist:
f.write(l)
f.write("\n")
f.write("---------------------------------------------------------\n")
f.close()
def get_available_list(alist):
f = open("可以正常学习的课程.txt",'a')
for l in alist:
f.write(l)
f.write("\n")
f.write("---------------------------------------------------------\n")
f.close()
#构造请求头,不构造的话默认的User-Agent是pyspider,等于自己告诉服务器我是爬虫在爬你的网站
#如果访问不成功是因为headers没有传完需要的所有参数
#审查元素/f12,或者利用抓包工具查看你爬取的页面需要哪些信息,这个例子中不需要所以不列举
def get_headers():
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0'}
return headers
def spider_active(begin, end,alist):
headers = get_headers()
for i in range(begin, end):
i += 1
lesson_id = str(i)
url = basic_url + lesson_id + "/"
print("正在查找:",url)
req = request.Request(url=url, headers=headers)
try:
#获取到的内容
content = request.urlopen(url)
except Exception as e:
print(e)
#urlopen可能出现httperror,如404等
not_found_list.append(lesson_id)
time.sleep(1)
continue
encode_html = content.read()
html = encode_html.decode("utf-8")
soup = BeautifulSoup(html,"html.parser")
tip = soup.find_all("div","tip")
#如果课程已下架
if len(tip) != 0:
not_available_list.append(lesson_id)
print("该课程已下架")
time.sleep(1)
continue
title = soup.find_all('h2','l')
t = title[0].get_text()
#将当前存在的课程加入alist列表
alist.append(lesson_id + t)
#encoding="utf-8" 用于避免一个编码error(如不加课程30将报错)
#zfill(5)用于给课程前面编号补0
#让获取到的文件在文件夹查看时看上去更有序
#validateTitle替换文件名非法字符为空格
#在课程编号和课程名称之间加一个空格,避免课程名称开始是数字的情况造成混淆
#如课程693, 707
f = open("lessons\\" + lesson_id.zfill(5) + " "
+ validateTitle(t) +".txt",'w',encoding="utf-8")
f.write(url)
f.write("\n\n")
charpters = soup.find_all("a","J-media-item")
for c in charpters:
f.write(c.get_text().replace(' ','').replace("开始学习",'').replace('\n',''))
f.write("\n")
f.close()
print("写入完成")
#休眠1秒
time.sleep(1)
if __name__ == "__main__":
#没有找到的课程的列表
not_found_list = []
#已下架课程的列表
not_available_list = []
#当前正常访问的课程的列表
available_list = []
basic_url = "https://www.imooc.com/learn/"
#爬取课程编号从begin+1到end之间的课程信息
#爬取开始点
begin = input("请输入爬取开始点课程编号(要求是一个整数):")
begin = int(begin)
#爬取结束点
end = input("请输入爬取结束点课程编号(要求是一个整数):")
end = int(end)
if begin < 0:
begin = 0
if begin > end:
print("开始值必须小于等于结束值")
sys.exit(0)
# 定义要创建的目录
mkpath="lessons"
# 创建该目录
try:
mkdir(mkpath)
except Exception as e:
print(e)
print("请检查路径是否出现以下问题:")
print("1.路径含中括号内非法字符:[\/\\\:\*\?\"\<\>\|]")
print("2.绝对路径长度超过了255个字符")
print("3.此情况概率极低:超过了当前文件系统能拥有的文件夹数量上限")
try:
spider_active(begin, end, available_list)
except Exception as e:
print(e)
#如果出现异常则向列表写入数据后退出程序,不包括用户主动退出
#解决bug后可以手动调整begin的值从上次异常中断点继续爬取
get_not_found_list(not_found_list)
get_not_available_list(not_available_list)
get_available_list(available_list)
sys.exit(1)
#正常爬取完也写入各个列表
get_not_found_list(not_found_list)
get_not_available_list(not_available_list)
get_available_list(available_list)
上面代码已是完整代码。接下来将代码按功能分开解释其功能便于理解
#创建文件夹的方法,不属于文章重点,请看代码注释
def mkdir(path):
for循环爬取网页部分的代码
#基础路径
basic_url = "https://www.imooc.com/learn/"
i += 1
lesson_id = str(i)
#拼接路径
url = basic_url + lesson_id + "/"
#发送请求
req = request.Request(url=url, headers=headers)
#获取网页内容
content = request.urlopen(url)
encode_html = content.read()
html = encode_html.decode("utf-8")
使用bs4解析网页内容
soup = BeautifulSoup(html,"html.parser")
#找到所有div标签中class为tip的标签对,如果课程已下架则会出现该标签
tip = soup.find_all("div","tip")
#tip长度不为0表示该课程已下架
if len(tip) != 0:
not_available_list.append(lesson_id)
print("该课程已下架")
time.sleep(1)
#跳过这次循环
continue
当课程不存在时,会返回httperror,这时也选择跳过本次循环
try:
content = request.urlopen(url)
except Exception as e:
print(e)
continue
如果课程存在且未下架,则将获取到的网页内容写入文件
title = soup.find_all('h2','l')
t = title[0].get_text()
#将当前存在的课程加入alist列表
alist.append(t)
#encoding="utf-8" 用于避免一个编码error(如不加课程30将报错)
#zfill(5)用于给课程前面编号补0
#让获取到的文件在文件夹查看时看上去更有序
#validateTitle替换文件名非法字符为空格
#在课程编号和课程名称之间加一个空格,避免课程名称开始是数字的情况造成混淆
#如课程693, 707
f = open("lessons\\" + lesson_id.zfill(5) + " "
+ validateTitle(t) +".txt",'w',encoding="utf-8")
f.write(url)
f.write("\n\n")
#类别为J-media-item的a标签包含了课程章节名称
charpters = soup.find_all("a","J-media-item")
for c in charpters:
#去除空格和开始学习等字符
f.write(c.get_text().replace(' ','').replace("开始学习",'').replace('\n',''))
f.write("\n")
f.close()
使用validateTitle()除去课程名称中的非法字符,否则如爬取到343号课程会报错
validateTitle(t)
其它的都是细节问题,慢慢看注释就能明白,看注释也不明白请看以前的文章(一)
慕课网仅爬取章节信息并没有爬虫检测机制(截止2019/10/15测试依然没有检测机制),所以不伪造headers和sleep也行,但也请考虑服务器的负担,本程序的目的在于方便大家快速查看所有免费课程的信息以快速找到自己想学但搜索可能不显示的课程,而不用挨个搜索课程是否存在,是否是自己想看的
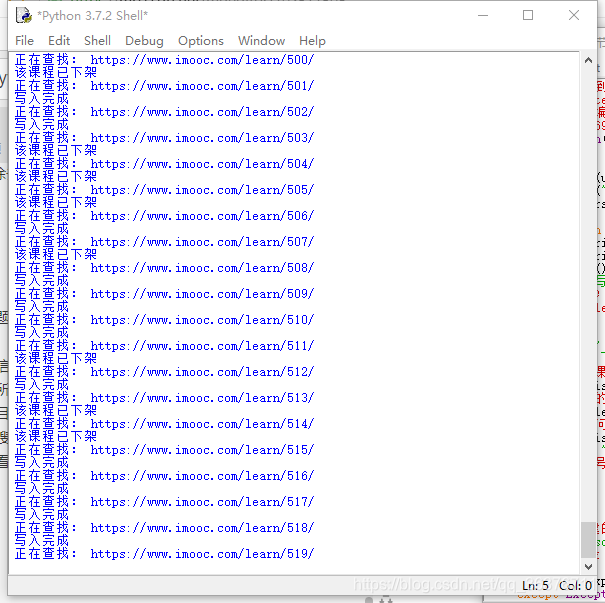
运行效果如下:
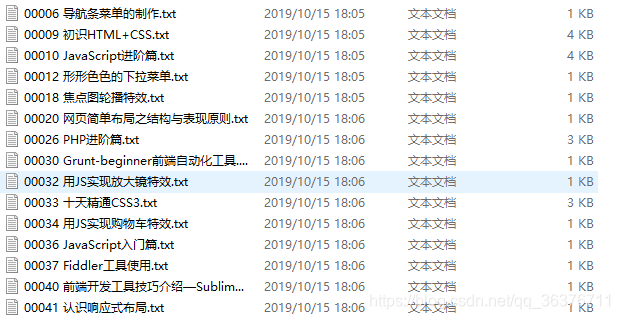
打开txt文件查看详细章节信息
