一,ResNet V1
2015 ILSVRC 第一


论文指出归一化包括BN,权重初始化已经很大程度解决了梯度消失和爆炸的问题,所以单纯一层一层叠加的深层网络效果不好是由于网络退化的原因造成的,增加了short cut能够能够让梯度直接回传,并且不需要额外的参数和复杂度。

二,ResNet V2
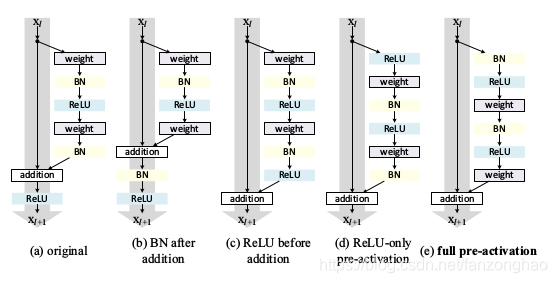
v2是为了证明short cut上是干净的,对于传播更加容易。
对于(b) 来说,BN改变了short cut上的信号传输,抑制信息的流通。

对于(c)负半轴的信息无法进入网络,影响resdiual分支,进而影响网络的表达能力。

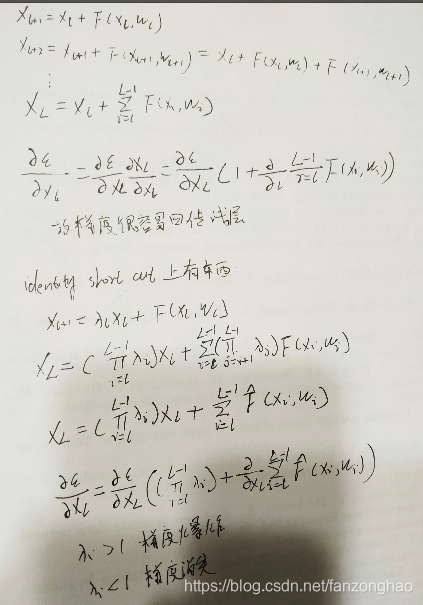
三,ResNeXt
2016 ILSVRC 第二
引入了新的维度,即 Cardinality。


四,DenseNet
传统的网络有L层就有L个连接,但是DenseNet却有L*(L+1)/2个。
其有三大优点:1,解决梯度弥散问题;2,增强特征传递;3,t特征得以复用,减少参数量。
从而使得信息流通更通畅。

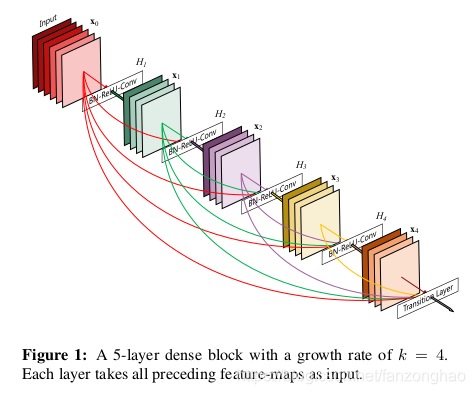
short cut并不是像ResNet那样进行相加,而是concate。

由于不需要重新学习大量的特征,并且实际上很多特征都是没什么用的,DenseNet设计了每层只有12个滤波器。

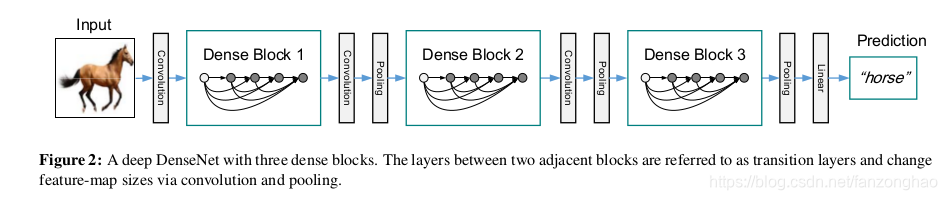
网络结构如下:
其中Dense Block 用于特征提取,transition layers用于改变feature map size。
与ResNet公式区别:
对于ResNet而言,l层的输出是l-1层的输出加上对l-1层输出的非线性变换
![]()
[x0,x1,…,xl-1]表示将0到l-1层的输出feature map做concatenation。concatenation是做通道的合并,就像Inception那样。而前面resnet是做值的相加,通道数是不变的。
![]()
Growth rate K用来控制每一层的channel个数

不用数据增强也没问题,具有防止过拟合作用,也许是参数少的原因。

201层的DenseNet参数只有20M比40M的101-ResNet还要少。
