词向量与ELMo模型
https://zhuanlan.zhihu.com/p/107223119

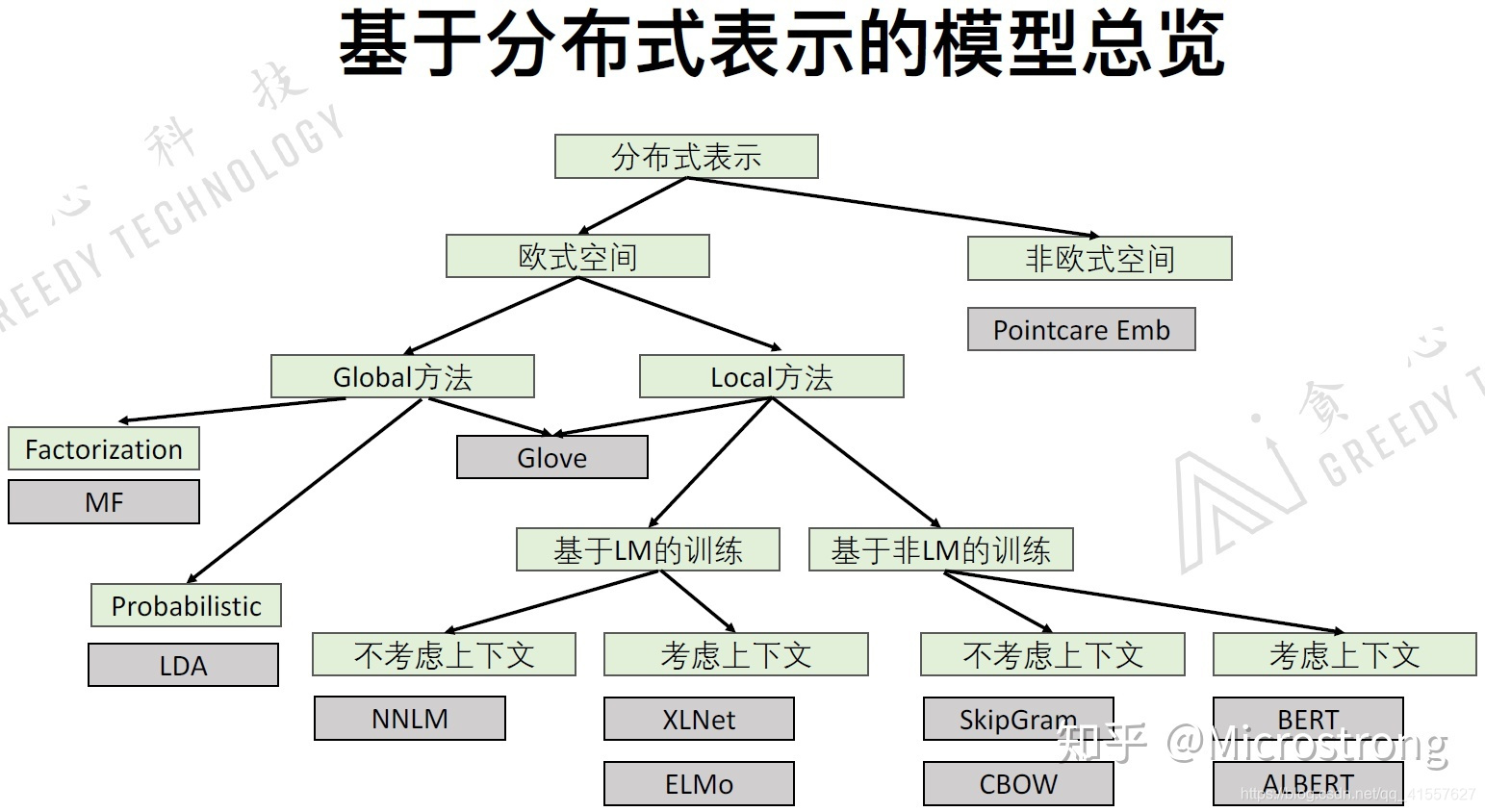
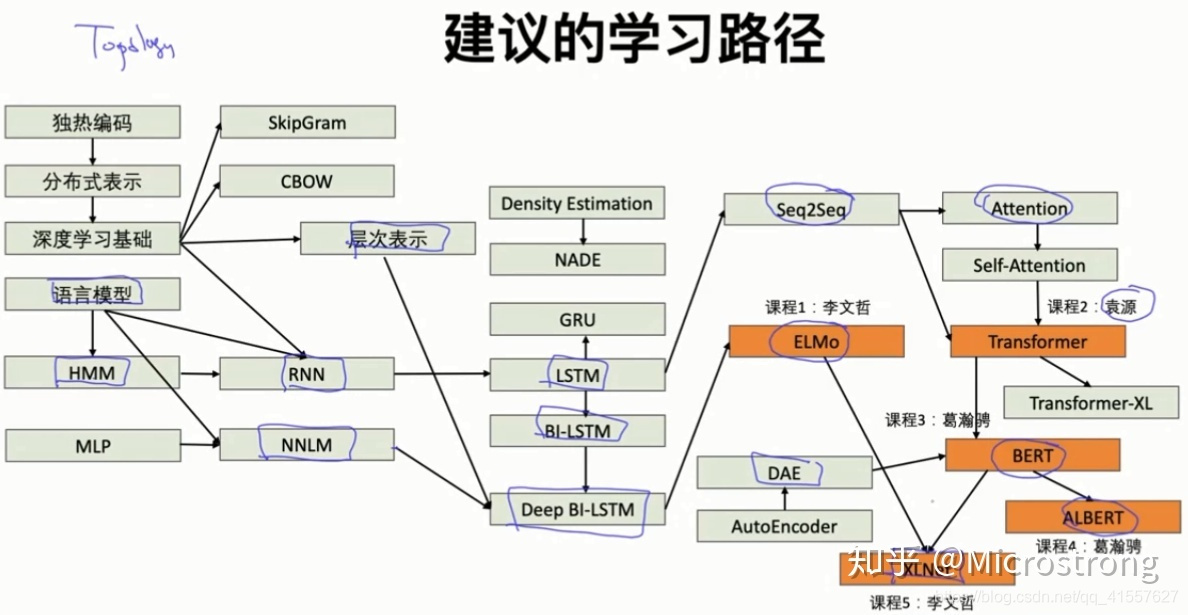
Bilstm介绍与代码实现
https://blog.csdn.net/w275840140/article/details/89503458?utm_source=app
ELMo解读(论文 + PyTorch源码)
https://blog.csdn.net/Magical_Bubble/article/details/89160032?utm_source=app
Transformer+pytorch源码
https://blog.csdn.net/lbw522/article/details/100932893?utm_source=app
bert
目前将预训练语言表征应用于下游任务存在两种策略:feature-based的策略和fine-tuning策略。
- feature-based策略(如 ELMo)使用将预训练表征作为额外特征的任务专用架构。
- fine-tuning策略(如生成预训练 Transformer (OpenAI GPT)引入了任务特定最小参数,通过简单地微调预训练参数在下游任务中进行训练。
原始的 transformer模型由encoder和decoder组成,每个都是我们称之为 transformer 架构的堆栈。这种架构是合理的,因为该模型解决了机器翻译问题——过去encoder-decoder结构解决的问题。
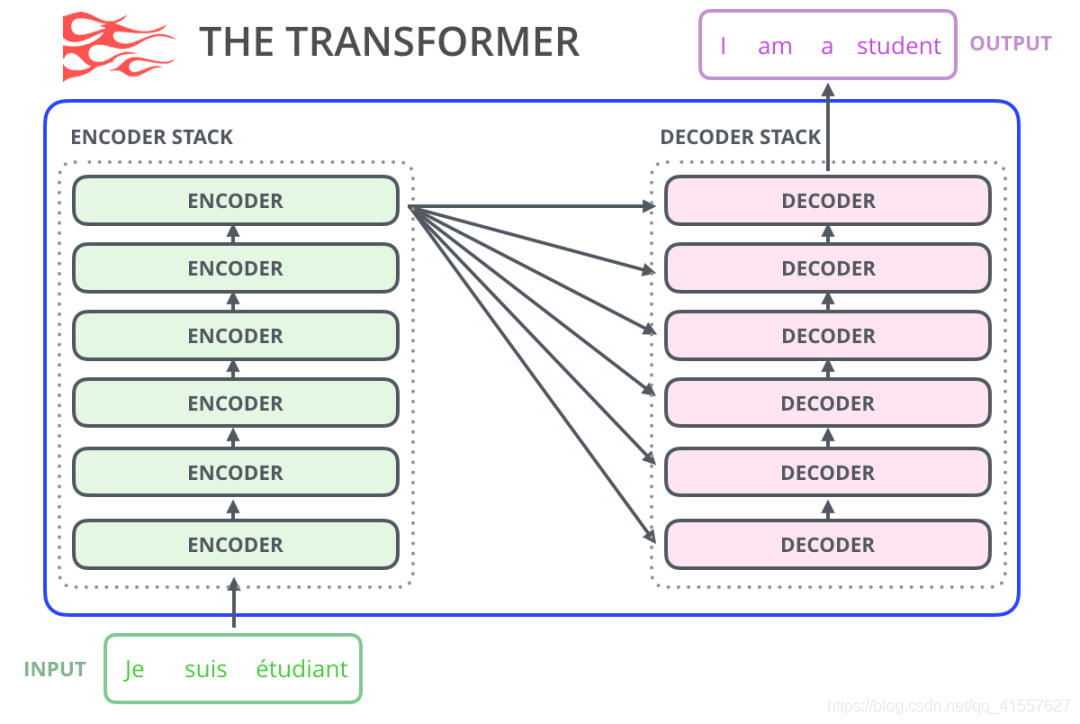 随后的许多研究工作中,这种架构要么去掉了encoder,要么去掉decoder,只使用其中一种transformer堆栈,并尽可能高地堆叠它们,为它们提供大量的训练文本,并投入大量的计算机设备,以训练其中一部分语言模型。
随后的许多研究工作中,这种架构要么去掉了encoder,要么去掉decoder,只使用其中一种transformer堆栈,并尽可能高地堆叠它们,为它们提供大量的训练文本,并投入大量的计算机设备,以训练其中一部分语言模型。
堆叠的高度是不同的GPT2模型之间大小有别的主要影响因素之一
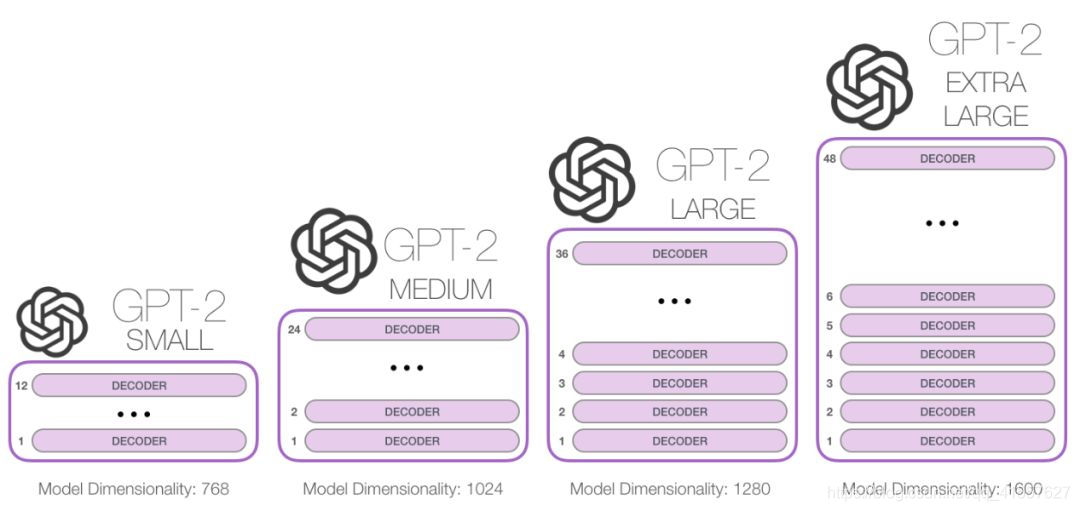
图解OpenAI的秘密武器GPT-2:可视化Transformer语言模型(链接)
OpenAI GPT使用的是从左到右的架构,其中每个token只能注意Transformer自注意力层中的先前token。这些局限对于句子层面的任务而言不是最佳选择,对于token级任务(如 SQuAD 问答)则可能是毁灭性的,因为在这种任务中,结合两个方向的语境至关重要。
BERT(Bidirectional Encoder Representations from Transformers)改进了基于微调的策略。提出一种新的预训练目标——遮蔽语言模型(masked language model,MLM),来克服上文提到的单向局限。
《The Illustrated BERT, ELMo, and co中文翻译》
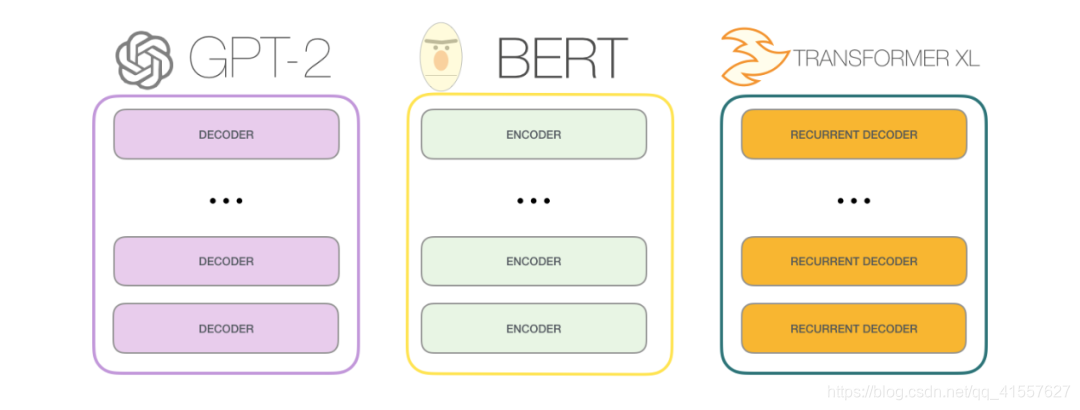
下图显示了BERT/GPT Transformer/ELMo的结构区别:
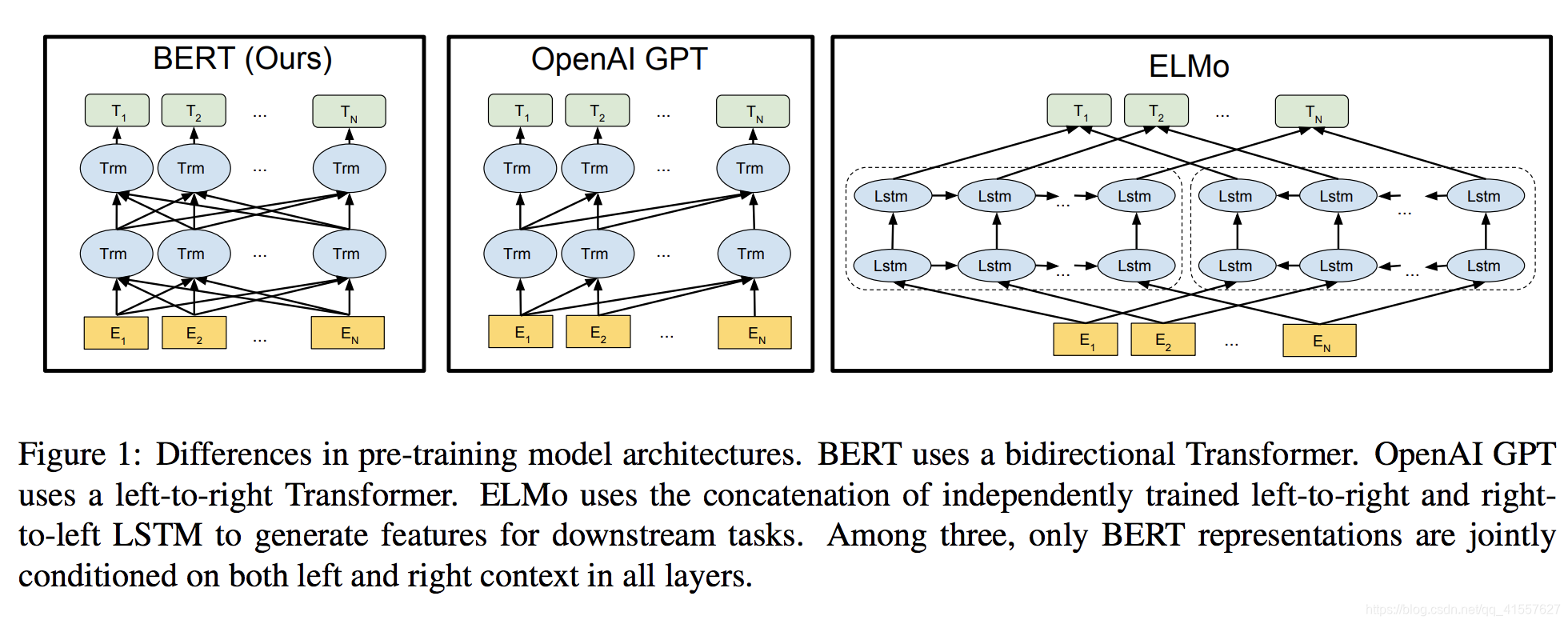
BERT 使用双向Transformer(encoder)
openAI GPT 使用从左到右的Transformer(decoder)
ELMo 使用独立训练的从左到右和从右到左LSTM的级联来生成下游任务的特征
三种模型中,只有BERT表征会基于所有层中的左右两侧语境
https://blog.csdn.net/qq_33148001/article/details/103705693?utm_source=app
《BERT详解》 https://blog.csdn.net/yangdelong/article/details/85070608?utm_source=app
Albert
《[深度学习] 自然语言处理 — ALBERT 介绍》, https://blog.csdn.net/zwqjoy/article/details/103862307?utm_source=app
从bert到albert
https://zhuanlan.zhihu.com/p/108451858
xlnet
