目录
一. 目标检测简介
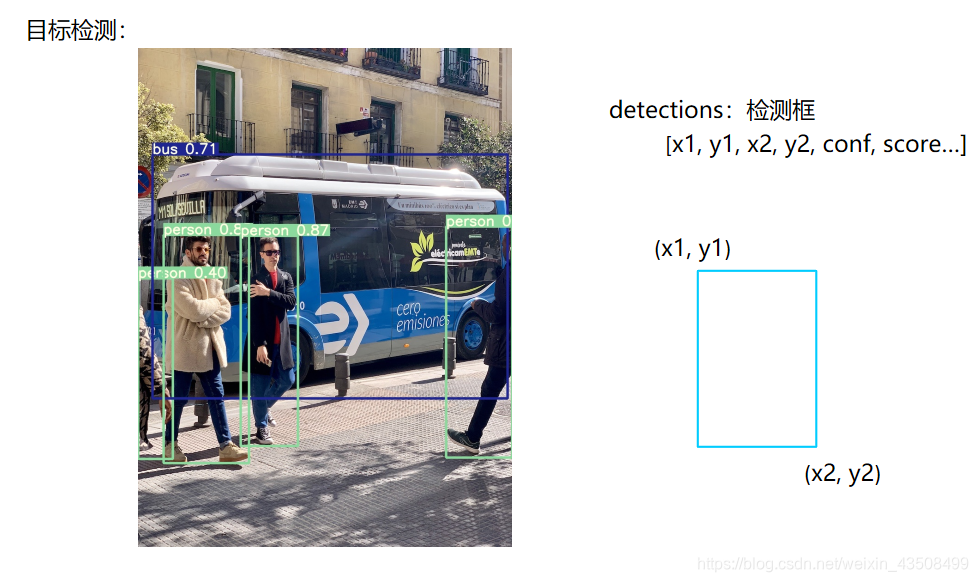
1.1 目标检测
给定一张图像,找出我们需要的类别位置,并给定一个检测框,检测框一般包含位置坐标,检测框置信度,每个类别的分数。
1.2 IOU指标
IOU指标就是Intersection Over Union,也叫交并比。
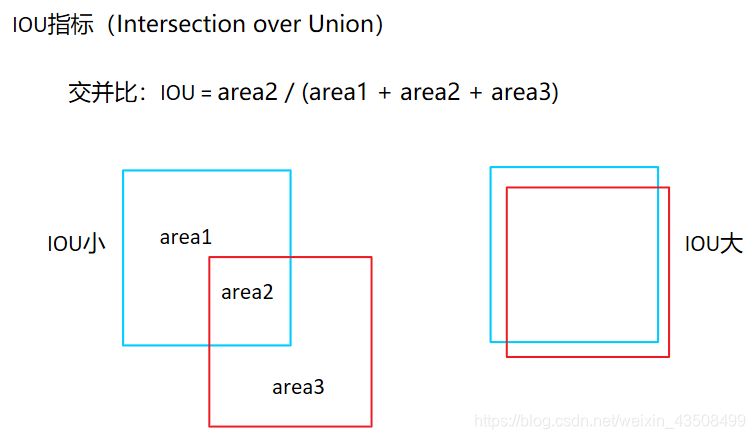
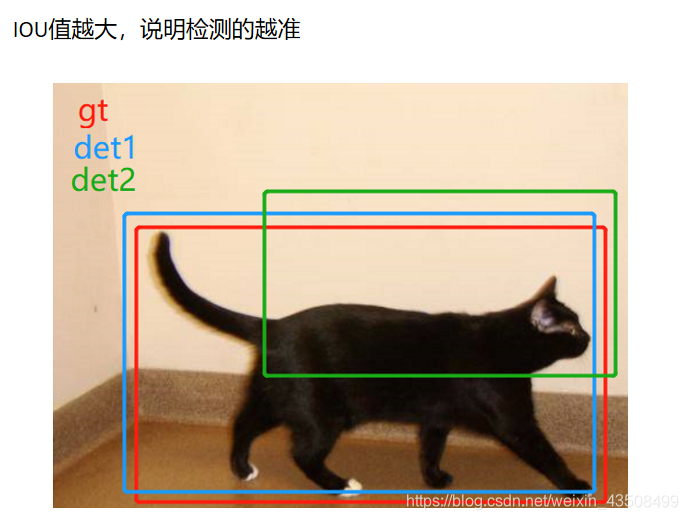
如上图所示,红色框表示groundTruth,蓝色框和绿色框是两个检测框,可以看到蓝色框跟红色框的IOU值更大,检测效果更好。
二. 目标跟踪简介
下图是一个目标跟踪的例子。(图片来源:戳这)
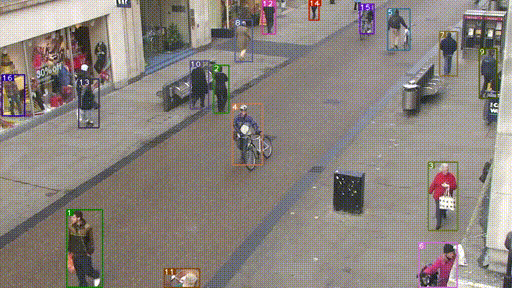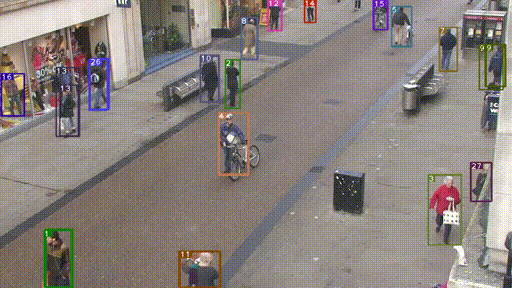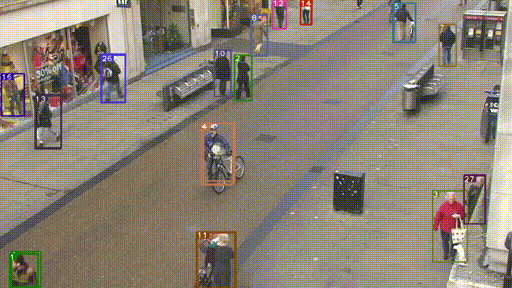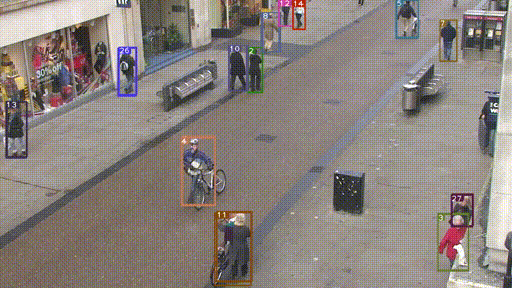
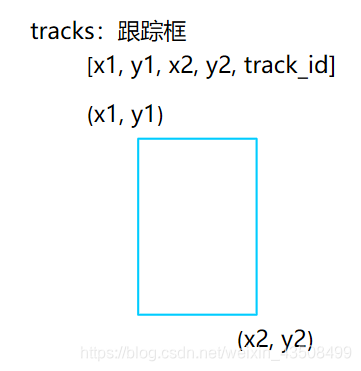
- 目标跟踪,会利用上一时刻(帧)的跟踪框和当前时刻(帧)的检测框,来更新得到当前时刻的跟踪框。
- old_tracks + new_detections ——> new_tracks
- 跟踪框会包含跟踪目标的位置坐标和id。
三. 卡尔曼滤波器
思考一个问题:如何利用上一时刻(帧)的跟踪框和当前时刻(帧)的检测框,来更新得到当前时刻的跟踪框?——利用卡尔曼滤波器。
3.1 什么是卡尔曼滤波器
卡尔曼滤波(Kalman filtering)是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。由于观测数据中包括系统中的噪声和干扰的影响,所以最优估计也可看作是滤波过程。(百度百科)
(光看概念是不是感觉 不知道在说啥???)

3.2 具体计算过程

(看完公式,头更大了?)

3.3 换个角度看
没关系,我们换个角度理解卡尔曼滤波。
先看几个例子:(参考来源:戳这)
- 假设你有两个传感器,测量同一个信号,可是每次的读数都不一样,怎么办?—— 取平均
- 假设其中一个传感器准一些,另外一个差一些,有比取平均更好的办法吗?——— 加权平均
- 假设你只有一个传感器,还有一个数学模型,模型可以帮你算出一个值,但是也不是那么准,怎么办?——把模型算出来的值,和传感器算出来的值,取加权平均。
卡尔曼滤波相当于上面的第三种情况,换成另外一种公式表达,如下所示:
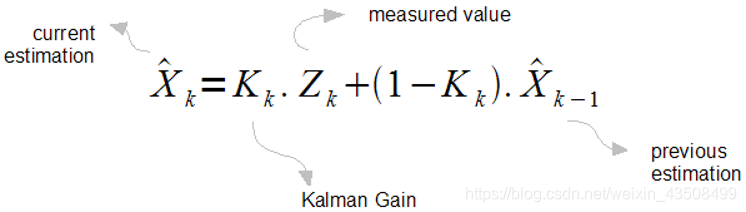
可以看到,其实就是一种加权求和。(简而言之)
卡尔曼滤波器与目标跟踪,对应上述第三种情况,有着如下的对应关系:
- 模型对应着卡尔曼滤波器
- 传感器对应着常用的检测模型(如SSD、YOLO等)
- 传感器算出来的值对应着检测框detections(当前时刻的观测值)
- 模型算出来的值相当于跟踪框tracks(上一时刻的预测值)
总结:
- 卡尔曼滤波器是利用上一时刻系统的预测状态x_k-1,和当前时刻的观测状态Z_k,来更新当前时刻的状态x_k。在把x_k当作下一时刻的x_k-1,重复更新。
- 卡尔曼滤波是一个不断predict——update——predict——update的过程。
四. 匈牙利算法
(这里匈牙利算法跟KM算法不作区分了)
如下图所示:红色框表示检测框,蓝色框和绿色框代表跟踪框,
这里再思考一个问题,如何让绿色跟踪框跟左侧检测框匹配,如何让蓝色跟踪框跟右边检测框匹配?——利用匈牙利算法。

匈牙利算法一般用于二分图的最大匹配。
下面举几个例子说明匈牙利算法是如何工作的。
例子一:男女生匹配问题(参考来源:戳这)
- 有两个集合Boys和Girls
- boy和girl的连线表示两人互有好感
- 现在要满足一夫一妻制,找出最大的匹配
首先给B1匹配:
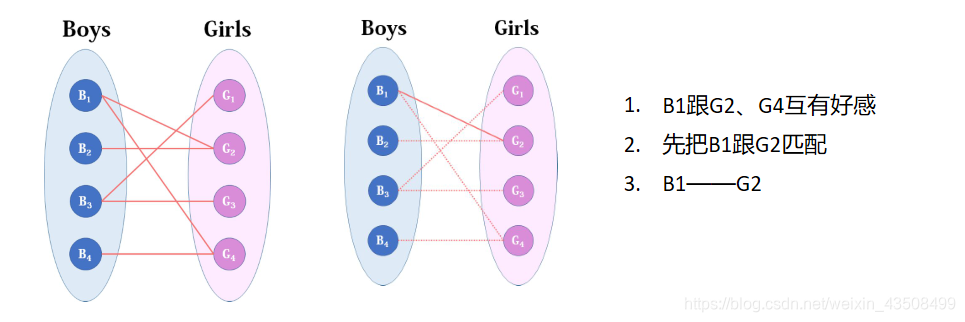
给B2匹配:

给B3匹配:
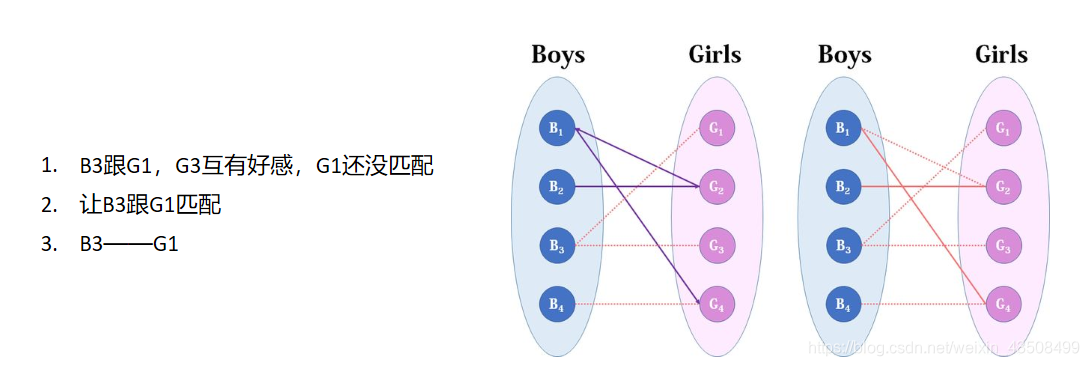
最后的B4无人跟他匹配了。
例子二:工人获得最小金钱的问题。
- 现在有两个集合:工人和工作
- 已知每个工人对应做每种工作花费的时间
- 要求工人和工作最大匹配,且保证总的时间最少
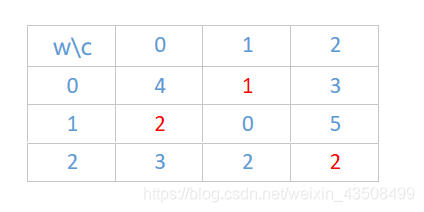
可以算出,选择红色数字,可以使总的时间最少。
例子三:Hungarian Algorithm在目标跟踪中的应用
- 已知两个集合,跟踪框tracks和检测框detections
- 已知每个track和detection的IOU值
- 要求track和detection的最大匹配,且保证IOU值最大
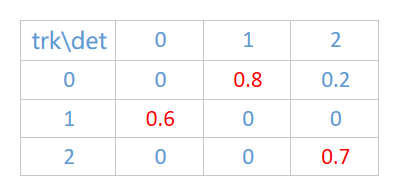
可以看到,选择红色数字,可以保证IOU最大。
总结:
- 到这里,对于匈牙利算法在目标跟踪里的作用应该有个大概的了解了把。
五. SORT
上面的模块都是SORT算法的组成部分。
SORT,即Simple Online and Realtime Tracking,是一种多目标跟踪算法。(不是排序的sort -_-||)
首先看整个框架的流程图:
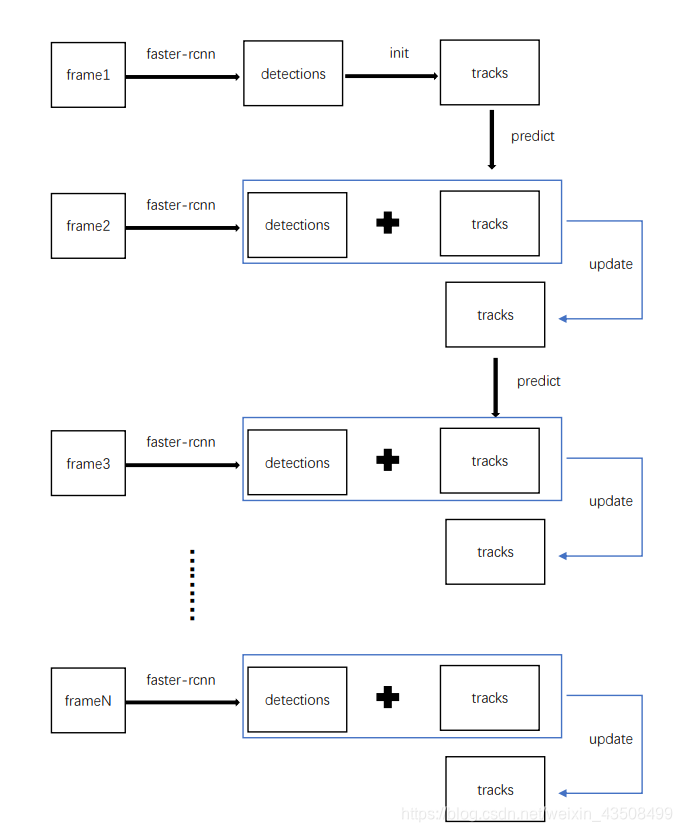
下面看一下每一步都做了哪些操作:
- 第一帧
- frame1经过检测模型得到检测框detections,将detections初始化为跟踪框tracks
- 第二帧
-
frame2经过检测模型得到检测框detections
-
上一帧的tracks通过卡尔曼滤波器的predict更新状态得到tracks’
-
detections和track’通过匈牙利算法进行匹配判定,得到三个输出:
1)不匹配的跟踪框unmatch_tracks,判断是否需要删除,删除后得到tracks_left2)不匹配的检测框unmatch_detections,初始化为新的跟踪框tracks_new
3)匹配的跟踪框match_tracks和匹配的跟踪框match_detections,利用match_detections去更新(update)match_tracks,得到tracks_update。tracks_update里如果满足return的条件,就返回显示。
-
tracks_left + tracks_new + tracks_update = tracks,合并得到tracks,用于下一时刻的更新。
-
整个过程的操作如下图所示:
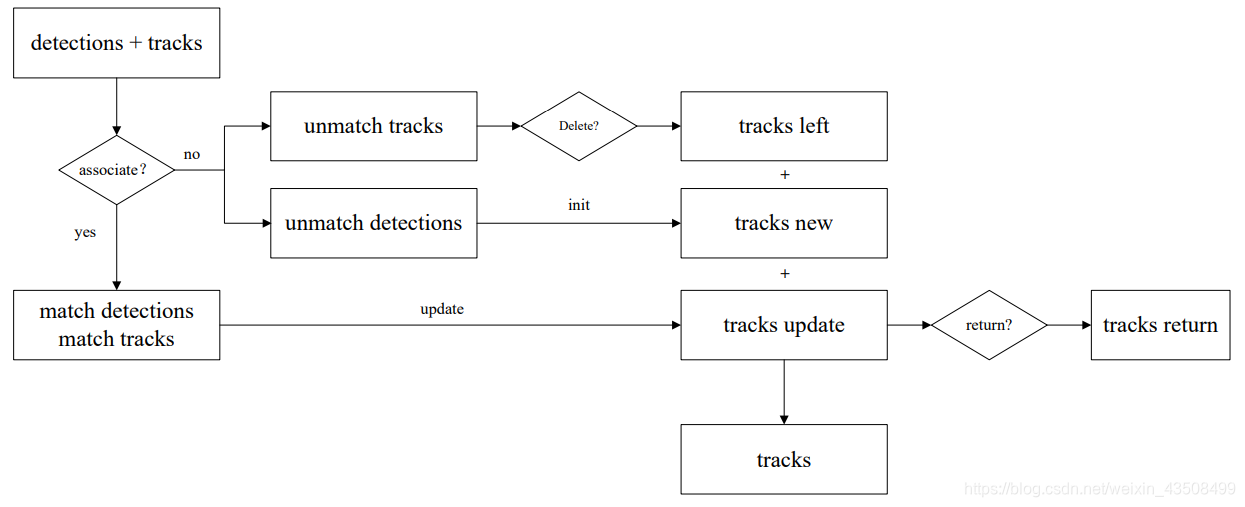
-
后面帧
重复第二帧的操作。
关于上图中的delete和return判断:(这部分主要结合代码分析)
- 全局参数:
- max_age:每个track可以存活的帧数
- min_hits:最小击中帧数
- frame_count:总的帧数,也就是第几帧
- sort算法对于每个track,会分配一个kalman filter(kf),kf有两个关键:
- time_since_update:最后一次update之后的值,predict会+1, update会清0
- hits_streak:连续命中的帧数
-
如何判断delete?
对于unmatch_tracks,如果time_since_update>max_age,则删除(说明你活了太久,但是没匹配到detection) -
如何判断return?
首要条件,必须是经过update的(说明track匹配到了detection);
然后,如果是前min_hits帧的,返回显示;如果不是前min_hits帧的,则连续命中帧数hits_streak必须大于等于min_hits才能返回显示。
到此,整个SORT算法就介绍完了。
六. DeepSORT
(这部分先简单记录,回头再详细补充——2021.4.16)
- DeepSORT只是针对行人进行跟踪,而SORT不限制类别
- DeepSORT利用行人重识别数据集,训练了一个模型,用于提取行人目标的特征,所以它的跟踪框和检测框多了一个features参数,例如 [x1, y1, x2, y2, id, features]
- Predict过程:
- kalman filter 执行predict,age += 1, time_since_update += 1
- state判断:
1)如果state == tentative,那么track的state标为待删除
2)如果time_since_update > max_age,那么track的state标为待删除
3)如果state==confirm, 不作改变
- Update过程:
- 首先把tracks分为confirmed_tracks和unconfirmed_tracks
- 传入confirmed_tracks和detections进行第一次match:
1)求confirmed_tracks的feature和detections的feature的代价矩阵cost_matrix(1 - cos)
2)利用马氏距离更新cost_matrix
3)求最大匹配,得到matches_a, unmatched_tracks_a, unmatched_detections_a- 把unmatched_tracks_a再分为:unmatched_tracks_0和unmatched_tracks_1
- iou_track_candidates = unconfirmed_tracks + unmatched_tracks_1
- 利用iou_track_candidates和unmatched_detections_a在进行匹配,求代价矩阵(1- iou),求最大匹配后,得到matches_b, unmatched_tracks_b, unmatched_detections_b
- 合并:
1)matches = matches_a + matches_b
2)unmatched_tracks = unmatched_tracks_a + unmatched_tracks_b
3)unmatched_detections = unmatched_detections_b
(下面的三个步骤,跟SORT一样) - 对于matches,利用matched_detection去更新(卡尔曼滤波起的update)matched_tracks
- 对于unmatched_tracks,判断是否需要删除
- 对于unmatched_detections,初始化为新的tracks
(未完,待续。。。)