看这俩吧
链接: 图解机器学习 | 朴素贝叶斯算法详解
链接: 带你理解朴素贝叶斯分类算法
链接: 理解朴素贝叶斯分类的拉普拉斯平滑
引言
在众多机器学习分类算法中,本篇我们提到的朴素贝叶斯模型,和其他绝大多数分类算法都不同,也是很重要的模型之一。
在机器学习中如KNN、逻辑回归、决策树等模型都是判别方法,也就是直接学习出特征输出 和特征 之间的关系(决策函数或者条件分布 )。但朴素贝叶斯是生成方法,它直接找出特征输出 和特征 的联合分布 ,进而通过 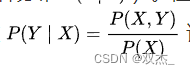
计算得出结果判定。
换个表达形式就会明朗很多,如下: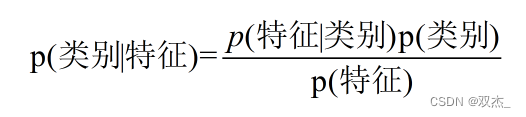
朴素贝叶斯是一个非常直观的模型,在很多领域有广泛的应用,比如早期的文本分类,很多时候会用它作为 baseline 模型,本篇内容我们对朴素贝叶斯算法原理做展开介绍。
1,朴素贝叶斯算法核心思想
其它分类算法相对来说主要求的是一个特定的分类,而朴素贝叶斯算法求的是概率。例如给出一张照片,判断是什么动物。如果使用KNN或者决策树,会得出它是一只小狗,而使用朴素贝叶斯,则会打出小狗的概率是80%。
2.拉普拉斯平滑及依据
为了解决零概率的问题,法国数学家拉普拉斯最早提出用加1的方法估计没有出现过的现象的概率,所以加法平滑也叫做拉普拉斯平滑。
假定训练样本很大时,每个分量x 的计数加 1 造成的估计概率变化可以忽略不计,但可以方便有效的避免零概率问题。
对应到文本分类的场景中,如果使用多项式朴素贝叶斯,假定特征 x 表示某个词在样本中出现的次数(当然用TF-IDF表示也可以)。拉普拉斯平滑处理后的条件概率计算公式为: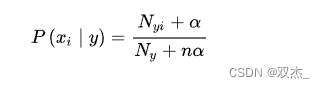
3.优缺点
优点:在数据较少的情况下仍然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据。