决策树算法简介
决策树是一种基于树状结构的分类与回归算法。它通过对数据集进行递归分割,将样本划分为多个类别或者回归值。决策树算法的核心思想是通过构建树来对数据进行划分,从而实现对未知样本的预测。
决策树的构建过程
决策树的构建过程包括以下步骤:
-
选择特征:从数据集中选择一个最优特征,使得根据该特征的取值能够将数据划分为最具有区分性的子集。
-
划分数据集:根据选定的特征将数据集分割成不同的子集,每个子集对应树中的一个分支。
-
递归构建:对每个子集递归地应用上述步骤,直到满足终止条件,如子集中的样本属于同一类别或达到预定深度。
-
决策节点:将特征选择和数据集划分过程映射到决策树中的节点。
-
叶节点:表示分类结果的节点,叶节点对应于某个类别或者回归值。
决策树的优点
决策树算法具有以下优点:
-
易于理解和解释:决策树的构建过程可以直观地表示,易于理解和解释,适用于数据探索和推断分析。
-
处理多类型数据:决策树可以处理离散型和连续型特征,适用于多类型数据。
-
能处理缺失值:在构建决策树时,可以处理含有缺失值的数据。
-
高效处理大数据:决策树算法的时间复杂度较低,对于大规模数据集也能得到较高的效率。
决策树的缺点
决策树算法也有一些缺点:
-
容易过拟合:决策树容易生成复杂的模型,导致过拟合问题,需要进行剪枝等处理。
-
不稳定性:数据的细微变化可能导致生成不同的决策树,算法不稳定。
决策树的应用场景
决策树算法在许多领域都有广泛的应用,包括但不限于:
-
分类问题:决策树用于解决分类问题,如垃圾邮件识别、疾病诊断等。
-
回归问题:对于回归问题,决策树可以预测连续性输出,如房价预测、销售量预测等。
-
特征选择:决策树可用于选择重要特征,帮助简化模型。
示例代码
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
data = load_iris()
X, y = data.data, data.target
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y)
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X_train, y_train)
# 预测
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
# 直接对比预测值和真实值
print(y_pred == y_test)
# 可视化决策树
from sklearn.tree import export_graphviz
import graphviz
dot_data = export_graphviz(clf, out_file=None,
feature_names=data.feature_names,
class_names=data.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("iris")
graph.view()
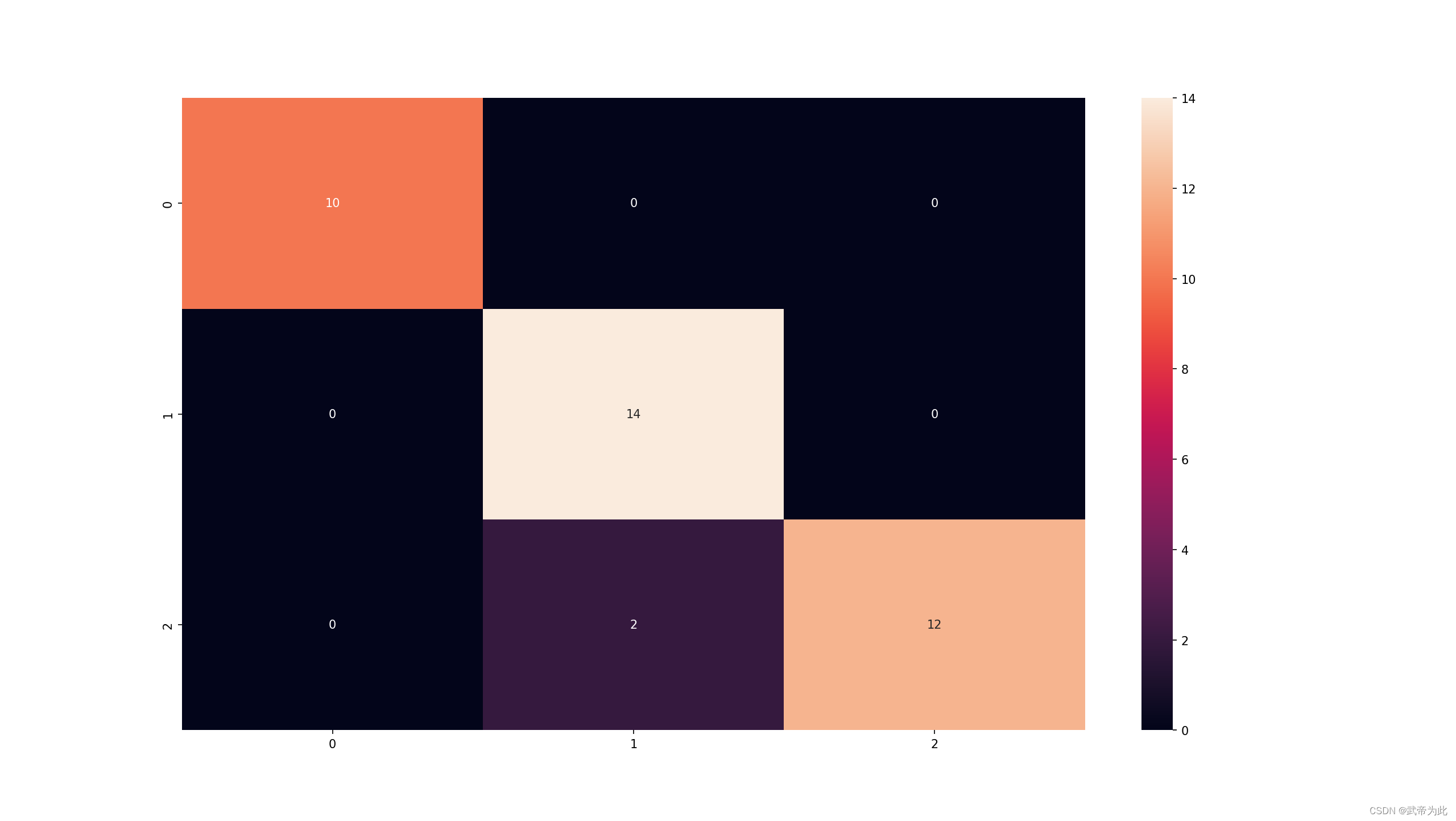
# 可视化混淆矩阵
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
# 计算混淆矩阵
cm = confusion_matrix(y_test, y_pred)
# 可视化混淆矩阵
sns.heatmap(cm, annot=True)
plt.show()
# 可视化分类报告
from sklearn.metrics import classification_report
# 计算分类报告
report = classification_report(y_test, y_pred)
# 打印分类报告
print(report)
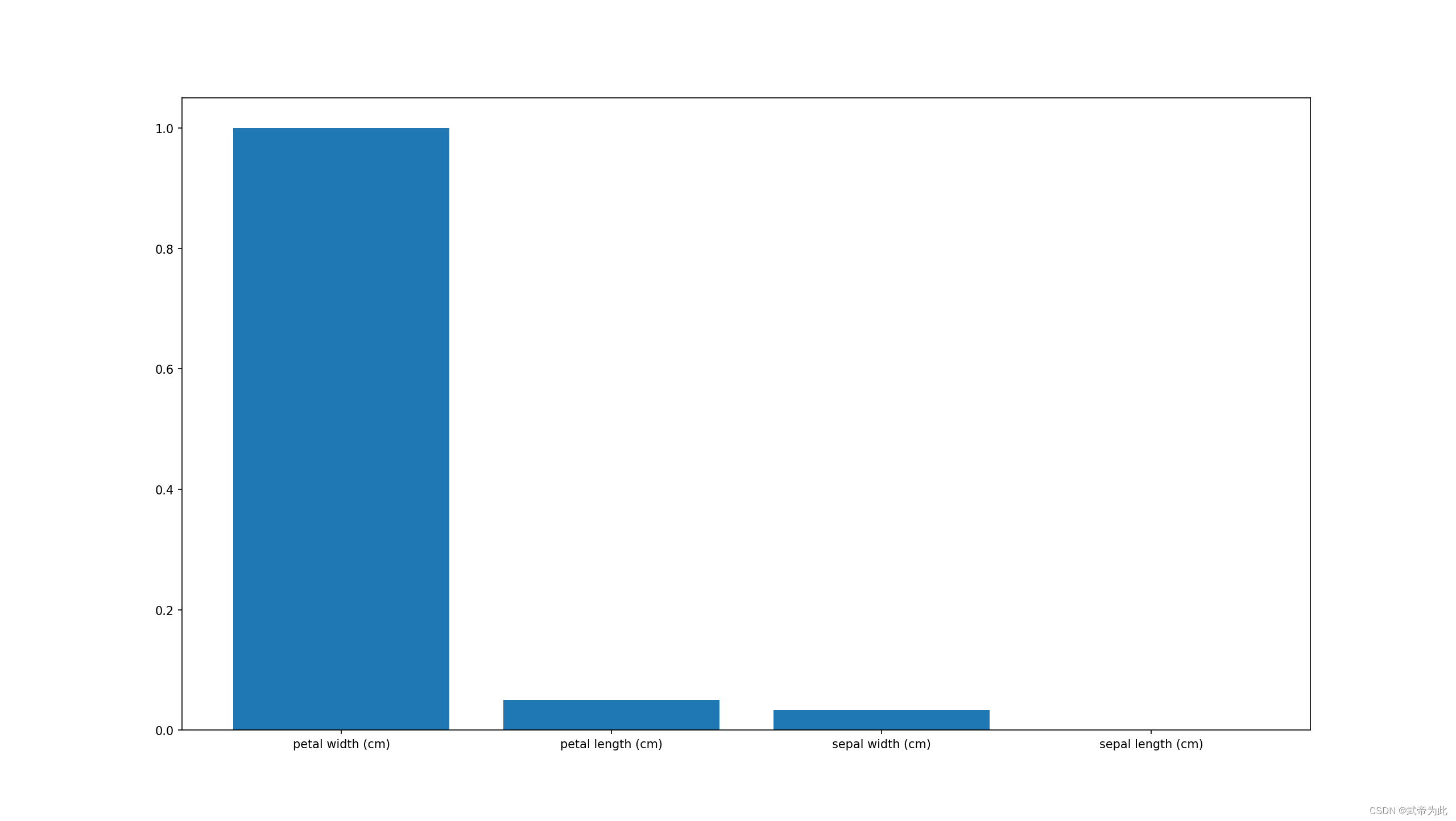
# 可视化特征重要性
import matplotlib.pyplot as plt
import numpy as np
# 获取特征重要性
importances = clf.feature_importances_
# 获取特征名称
feature_names = data.feature_names
# 将特征重要性标准化
importances = importances / np.max(importances)
# 将特征名称和特征重要性组合在一起
feature_names = np.array(feature_names)
feature_importances = np.array(importances)
feature_names_importances = np.vstack((feature_names, feature_importances))
# 将特征重要性排序
feature_names_importances = feature_names_importances[:, feature_names_importances[1, :].argsort()[::-1]]
# 绘制条形图
plt.bar(feature_names_importances[0, :], feature_names_importances[1, :].astype(float))
plt.show()

总结
决策树算法是一种强大且灵活的机器学习算法,适用于分类和回归任务。它具有易于理解、处理多类型数据以及高效处理大数据等优点。然而,需要注意过拟合和不稳定性等缺点。