Review of Feature Selection, Dimensionality Reduction and Classification for Chronic Disease Diagnosis-慢性病诊断的特征选择、降维和分类综述
摘要
慢性病的早期诊断在卫生保健界和生物医学领域发挥着至关重要的作用,在这些领域,有必要在疾病的初始阶段进行检测,以降低死亡率。本文研究了特征选择、降维和分类技术在慢性病预测和诊断中的应用。属性的正确选择对提高诊断系统的分类精度起着至关重要的作用。此外,降维技术有效地提高了机器学习算法的整体性能。在慢性病数据库上,分类技术通过开发智能、自适应和自动化系统提供有效的预测结果。本文还分析了并行和自适应分类技术在慢性病诊断中的应用,以促进分类过程,提高计算量和时间。这篇综述文章概述了特征选择、降维和分类技术及其固有的优缺点。
索引项
自适应分类,慢性病,降维,特征选择,并行分类。
I. INTRODUCTION
近几十年来,慢性病是人类生命的最大威胁,在降低死亡率之前,诊断和预测慢性病至关重要。主要慢性病包括帕金森病、心脏病、肺癌、肝炎、乳腺癌、慢性肾病等。在医学领域,维护临床数据库是一项关键任务,包括与慢性病相关的若干特征和诊断[1]。医学数据库中存储的数据由冗余数据和缺失值组成,因此在采用数据挖掘算法之前有必要对数据进行缩减。如果数据一致且无噪音,慢性病诊断就会变得更容易、更快。特征选择和降维是降低数据维数的有效数据预处理技术[2]。在医疗保健领域,找到与慢性病相关的危险因素非常重要。相关特征诊断有助于去除慢性病数据库中的冗余属性和无关信息,从而获得快速、准确的预测结果。诊断和分类技术利用训练数据建立模型,然后将相应的模型用于测试数据,以获得更好的预测结果。许多分类技术被用于疾病数据集,用于慢性病的早期诊断[3]。医疗数据包括与药房、医生处方、个人临床和诊断测试报告、社交媒体帖子等相关的信息。因此,开发一种简化和加速诊断过程的新型慢性病诊断分类器至关重要。慢性病诊断系统被用作控制疾病的工具,帮助医疗专业人员和临床医生提供全天候医疗服务,并有效监测患者的健康状况。
本调查文件编制如下。
第2节简要介绍了慢性病诊断中使用的数据库。
第3节介绍了慢性病诊断的特征选择和降维方法。表格研究了各种特征选择技术,包括它们的特点、优点和缺点。
第4节回顾了传统的、并行的、自适应的慢性病诊断分类技术。
第5节简要说明了慢性病诊断中使用的绩效指标。
第6节给出了调查文件的结论。
II. DATABASE AVAILABLE IN CHRONIC DISEASE DIAGNOSIS
近几十年来,慢性病是一种对人类健康有巨大影响的长期疾病。最常见的慢性病是高脂血症性关节炎、冠状动脉疾病、结肠癌、哮喘、心脏病、血友病、慢性肾病、慢性呼吸道疾病等[4]。导致慢性病的风险行为包括:;高血压(血压升高)、吸烟、胆固醇升高、不健康饮食、缺乏体育锻炼和有害饮酒。慢性病的风险行为如图1所示。
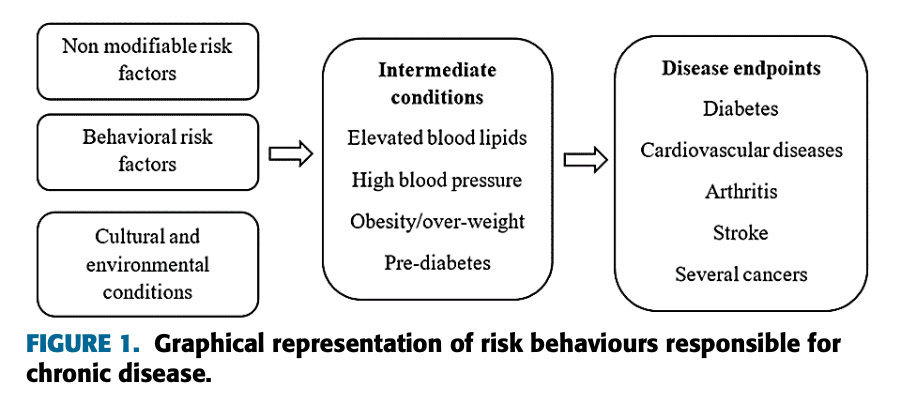
图1。慢性病风险行为的图形表示。
在医疗社区和生物医学领域,慢性病的准确诊断显著降低了死亡率。近几十年来,有几个数据库可用于慢性病诊断,其中一些流行的数据库如表1所示。数据库的选择应适当,因为意图操作(特征选择或降维和分类)取决于所选数据库。
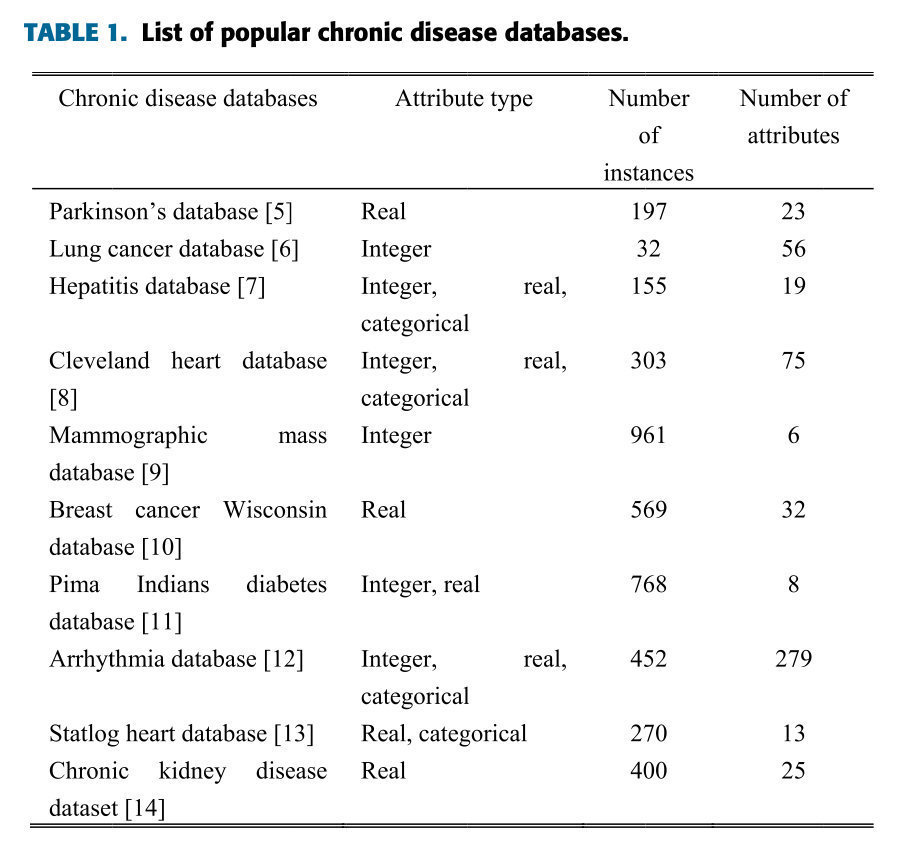
表1。流行慢性病数据库列表。
II. FEATURE SELECTION AND DIMENSIONALITY REDUCTION TECHNIQUES IN CHRONIC DISEASE DIAGNOSIS
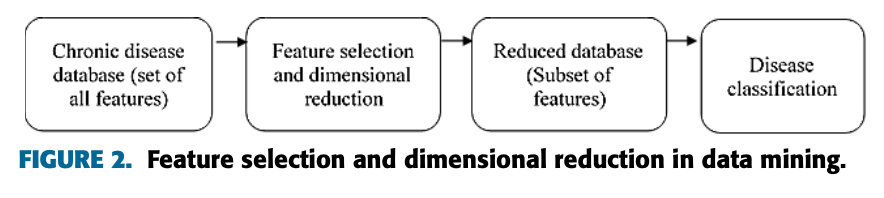
在数据挖掘中,特征选择和降维是最常用的预处理技术,通过减少数据库中不相关的属性来最小化数据。它还促进了更好的数据可视化,提高了数据的可理解性,并最大限度地减少了慢性病诊断中分类技术的训练时间。然而,慢性病诊断发生在许多情况下,如地中海贫血、糖尿病、心脏病、高血压、中风等[2]。在数据挖掘中,特征选择技术大致分为四类,如嵌入式技术、包装器技术、过滤技术和混合技术[15]。特征选择技术从原始数据库中去除重复和不相关的特征,以提高分类精度。数据挖掘中的特征选择过程如图2所示。
A. FILTERING TECHNIQUES
过滤技术独立地从数据库中选择特征。过滤是最古老的过程之一,它基于特定的评估标准对属性进行分类,因为它不依赖于分类技术。滤波技术在消除冗余、不变、重复、无关和相关特征方面效果较好。尽管如此,所选择的特征在任何机器学习技术中都会使用,因为它在计算上是廉价的。目前,有两种类型的过滤技术可用,如单变量和多变量。单变量过滤技术基于特定标准对单个特征进行排序,并在特征空间中独立地处理每个特征。最后,根据标准选择排名最高的特征。单变量技术选择冗余变量,其中不考虑在单变量技术中主要关注的特征之间的关系。
另一方面,多变量技术评估整个特征空间,能够处理冗余、重复和相关特征。Battiti[16]实现了一种基于互信息概念的特征选择技术。在本研究中,特征选择技术提取具有最大互信息的特征。此外,Bennasar等人[17]开发了两种新的非线性特征选择技术,称为联合互信息最大化(JMIM)和归一化JMIM(NJMIM),其中这两种技术利用互信息和“最小标准的最大值”从UCI存储库数据库中提取特征。
Chormunge和Jena[18]实现了一种新的基于相关性和聚类的特征选择技术,以减少数据挖掘任务中的维数问题。首先利用k均值聚类算法去除不相关特征,然后对每个聚类进行相关度量,选择非冗余特征。接下来,将naïve Bayes应用于微阵列和文本数据库的分类。Cigdem等人[19]利用基于相关性的特征选择技术对特征进行排序,并使用fisher准则选择排名靠前的特征。然后,使用不同的分类技术在三维磁共振成像上对双相情感障碍进行分类。
B. WRAPPER TECHNIQUES
包装器技术根据分类器的性能提取相关特征。它显著地解决了实际的优化问题,但与过滤技术相比,计算成本较高。包装器技术基于贪婪搜索算法工作,在贪婪搜索算法中,对所有特征组合进行评估,并选择为机器或深度学习算法提供更好结果的特征组合。包装技术包括两个主要优点;(i) 有效地找到最佳特征子集(ii)并检测变量之间的交互作用。通常,包装器技术导致与过滤技术相关的更好的预测精度。对于特征选择,包装器技术分为三类:穷举特征选择、向前和向后特征选择。Lee等人[20]使用基于包装器的特征选择技术来有效处理医疗保健系统生成的高容量和多维数据。本文提出了一种新的基于bagging C4.5算法的包装特征选择方法,用于医疗保健领域的临床决策。Jadhav等人[21]实现了一种新的特征选择技术,称为信息增益导向的特征选择技术,该技术基于信息增益对特征进行排序,并利用遗传算法选择顶部特征。Apolloni等人[22]介绍了一种基于二进制差分进化算法的包装特征选择技术,以减少微阵列数据的维数。
Sawhney等人[23]将惩罚函数与二进制firefly算法的现有适应度函数相结合,以减少特征集。选择的最优特征子集有效地提高了随机森林分类器对宫颈癌、乳腺癌、宫颈癌、肝癌和肝细胞癌的分类精度。Mafarja和Mirjalili[24]利用鲸鱼优化算法最小化输入特征的维数。实验结果表明,与粒子群优化(PSO)[25]、[26]和遗传算法[27]等其他现有技术相比,开发的算法提供了更好的结果。此外,Shen等人[28]和Balasubramanian及Marichamy[29]使用果蝇优化算法来最小化特征的维数。实验结果表明,该算法获得了更合适的模型参数,具有较高的分类精度。果蝇优化算法被认为是医疗决策的有效工具。
C. EMBEDDED TECHNIQUES
在嵌入式技术中,特征选择作为学习算法的一部分集成在一起,它结合了包装器和过滤技术的质量。嵌入技术的常见示例是套索和岭回归,它具有内置的惩罚函数,用于减少过拟合问题。套索回归技术执行L1正则化,增加与系数大小相等的惩罚。然而,岭回归技术执行L2正则化,为系数大小的平方增加惩罚等价物。Liu等人[30]为无监督特征选择实现了一种有效的邻域嵌入技术。首先,使用局部线性嵌入算法获得特征权重矩阵。接下来,采用L1归一化技术来抑制数据集中噪声和异常值的影响。大量实验表明,与现有的无监督特征选择技术相比,该技术在基准数据集上取得了更好的性能。
Tao等人[31]引入了一种新的多源自适应嵌入技术,通过L2归一化、跟踪范数和l-范数正则化利用相关信息进行特征选择。此外,所开发的自适应嵌入技术对域中存在的异常值或噪声具有鲁棒性,并通过应用稀疏回归方法和通过L1和L2范数最小化的图嵌入来保持原始几何结构信息。Wang和Zhu[32]使用稀疏性保持和邻域嵌入特征选择技术来处理大量数据。已开发的特征选择技术在机器学习库中的八个公开可用数据集上进行了研究。大量实验表明,与现有技术相比,所开发的技术在特征选择方面取得了更好的性能。
D. HYBRID TECHNIQUES
近几十年来,混合技术被研究人员广泛用于特征选择。混合技术结合了两种或更多的特征选择技术以获得最佳结果。通常,与过滤技术相比,混合技术具有更好的计算效率,并且与包装器和嵌入式技术相比具有更高的分类精度。Baliarsingh等人[33]结合帝企鹅优化器和社会工程优化器来选择肺癌、卵巢癌、结肠癌和白血病的相关属性。接下来,使用支持向量机(SVM)分类器对相关基因进行分类。此外,AlMuhaideb和Menai[34]将人工蜂群(ABC)和蚁群优化器(ACO)相结合,以优化医疗数据。在实时数据库和基准数据库上的实验结果表明了混合技术的有效性。在混合技术的帮助下,分类模型获得了更好的预测精度。
Jayaraman和Sultana[35]将粒子群优化算法和引力布谷鸟搜索算法(GCSA)相结合,以管理心脏病分类系统中存在的特征。首先,从心脏病数据库UCI存储库收集数据。采集到的数据维数高,难以处理,降低了心脏病诊断系统的效率。因此,PSO和GCSA的行为降低了数据的维数。所选特征被送入联想记忆分类器进行数据分类。Khourdifi和Bahaj[36]将PSO和ACO算法结合起来,以提高心脏病分类的质量。所选择的特征被送入不同的分类器进行数据分类。大量实验表明,混合优化技术显著提高了医学数据库的诊断准确率。
Bharti和Mittal[37]开发了一个基于混合特征选择的特征融合系统,用于生成最佳特征子集,将肝脏超声图像分为4类;肝硬化、正常、肝细胞癌和慢性。混合特征选择消除了重复和不相关的特征子集,显著提高了分类性能。Jain和Singh[38]引入了一种新的自适应分类系统来诊断慢性病。首先,使用reliefF和主成分分析(PCA)进行特征优化,并使用SVM分类器进行数据分类。在本研究中,一种有效的参数优化技术被应用到支持向量机分类器中,以获得更高的分类精度。为了评估系统性能,使用著名的疾病数据库(卵巢癌、前列腺癌、白血病、肺癌、结肠数据集和心脏病)进行医疗诊断。表2说明了用于慢性病诊断的特征选择技术的优缺点。

E. DIMENSIONAL REDUCTION TECHNIQUES
降维技术将高维数据空间转换为低维数据空间。在处理高维数据空间时,原始数据通常是稀疏的,这会导致“维度诅咒”问题和计算困难。降维技术广泛应用于医学、生物信息学等领域,主要分为线性降维和非线性降维两大类。慢性病诊断中最常用的技术是PCA、线性判别分析(LDA)、广义判别分析(GDA)等。Muhammad等人[39]将PCA技术用于糖尿病的变量分类。慢性病的诊断是卫生保健领域的一项具有挑战性的任务,在卫生保健领域,有多种数据挖掘技术被用于决策。Banu[40]应用LDA技术对甲状腺机能减退疾病进行分类。Shahbazi和Asl[41]将GDA用作特征选择技术,以最小化特征空间中的特征数量和样本重叠。此外,利用K-最近邻(KNN)分析特征集在心脏病分类中的性能。
IV. CLASSIFICATION TECHNIQUES USED IN CHRONIC DISEASE DIAGNOSIS
在数据挖掘中,分类包括基于人工智能、数学、概率分布和统计学的无监督和有监督技术[3]。通常,分类技术用于表示数据项的描述性分析,并预测数据项的组成员,以进行有效决策。
在数据挖掘中,一些研究人员使用不同的分类技术进行慢性病诊断,以获得更好的诊断准确性和诊断结果。SVM[42]、[43]、random forest[44]、KNN[45]、Adaboost[46]等分类器用于慢性病的诊断和预后。图3显示了应用于预处理医疗数据以实现预测结果的分类过程。
在大多数科学应用中,需要自动化和可理解的系统来更好地诊断和诊断慢性疾病,如肺癌、肝炎、慢性肾病、帕金森病等,大多数传统的系统效率低下,降低了成功率,增加了计算时间或决策时间。因此,需要一种能够准确预测疾病的自适应分类技术来进行慢性病诊断。此外,并行分类技术也用于提高诊断结果。表3说明了慢性病诊断中使用的分类技术的优缺点。
Mohapatra等人[47]使用布谷鸟搜索和极端机器学习(EML)技术对四个基准数据集进行分类;肝炎、糖尿病、Bupa和乳腺癌。实验结果表明,该模型在敏感性、f评分、特异性、总体准确度、Gmean、混淆矩阵和归一化值等方面均有效。Polat[48]使用属性加权技术对心脏、帕金森、皮马印第安人和胸外科医学数据库进行数据预处理和分类。为了减少类内的方差值,本研究采用了三种聚类算法(均值漂移、k-均值和模糊C-均值)。在属性加权处理后,利用支持向量机、KNN、随机森林和LDA对不平衡的医学数据库进行分类。大量实验表明,与随机子抽样技术相比,所开发的属性加权技术实现了更高的分类精度。Seera和Lim[49]开发了一种基于随机森林、回归树和模糊最小最大神经网络的混合智能医疗数据分类系统。在肝脏疾病、Pima印第安人糖尿病和威斯康星州乳腺癌数据库上分析了开发的智能系统的性能。
Jaganathan和Kuppuchamy[50]使用特征选择技术,如均值选择、神经网络和半选择,以减少克利夫兰心脏病、statlog、威斯康星州乳腺癌、肝炎和皮马印第安人糖尿病数据集中冗余、不相关和不必要的特征。然后,将选定的最优特征输入径向基函数,对医学数据进行分类。Nalband等人[51]使用遗传算法和apriori算法从提取的特征向量中选择重要特征。然后,应用随机森林和最小二乘支持向量机(LS-SVM)分类技术,对异常和正常振动测图信号进行精确区分。此外,Cheruku等人[52]介绍了一种基于bat优化算法和粗糙集理论的新型混合决策支持系统。该混合系统通过生成模糊规则有效地减少了冗余特征。然后,将选定的特征输入基于模糊规则的分类技术,对疾病进行分类。在本文献中,根据g-测量、准确性、敏感性和特异性,对威斯康星州乳腺癌、Pima印第安人糖尿病、iris和克利夫兰心脏病数据集的开发系统性能进行了调查。
A. PARALLEL CLASSIFICATION TECHNIQUES USED IN CHRONIC DISEASE DIAGNOSIS
传统的分类技术对于处理海量或非结构化的医学数据是无效的。因此,利用数据分析改进了现有医疗保健系统的结构。目前,大数据分析是通过使用Hadoop、map reduce编程等多种技术和工具完成的。然而,并行分类技术在提高诊断系统的预测准确性方面具有巨大潜力。平行分类技术在慢性病的临床决策中是有效的。图4显示了应用于预处理数据的并行分类技术,以实现奥斯特罗姆和科克[5]提出的更好的预测结果。
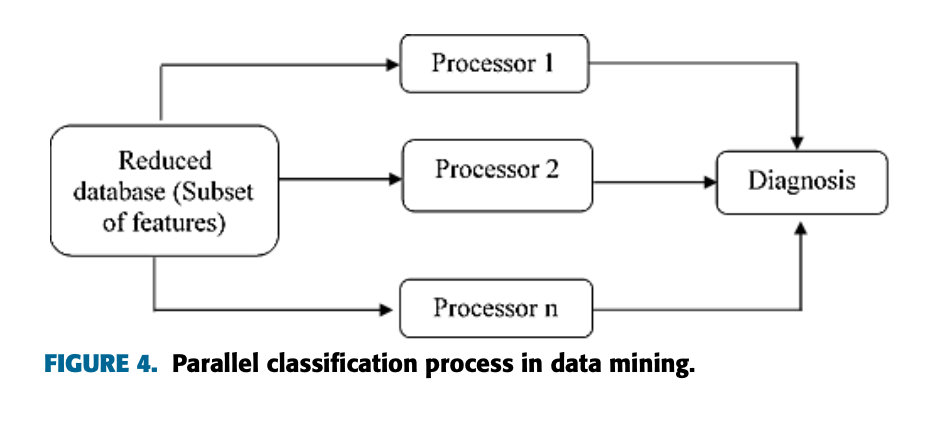
在本文献中,使用两个神经网络来减少错误决策的可能性。对于最终决策,使用基于规则的系统分析每个神经网络的输出。所开发的并行网络有效地提高了慢性病诊断的鲁棒性。仿真结果表明,与单一的唯一网络相比,并行网络在帕金森病诊断方面提高了8.4%。此外,Shrivastava等人[53]开发了一种并行支持向量机技术,用于在调查数据库中预测人类患糖尿病的几率。这篇研究论文预测了一个人将来患糖尿病的可能性。由于调查数据的高维性,传统的支持向量机是无效的。为了处理大量的参数,本文引入了并行支持向量机的概念。并行支持向量机将参数分布在不同的机器上,降低了处理能力、计算复杂度和存储空间。仿真结果表明,与传统的支持向量机技术相比,并行支持向量机减少了1/3的计算时间。
B. ADAPTIVE CLASSIFICATION TECHNIQUES USED IN CHRONIC DISEASE DIAGNOSIS
最近,在高级版本中使用了分类技术来为医学数据集中的属性生成分类,以便更好地进行分类。自适应分类器的高级版本是聚类和分类技术的结合。自适应系统显著提高了成功率,并帮助医务人员和医生在慢性病诊断中做出有效的临床决策。
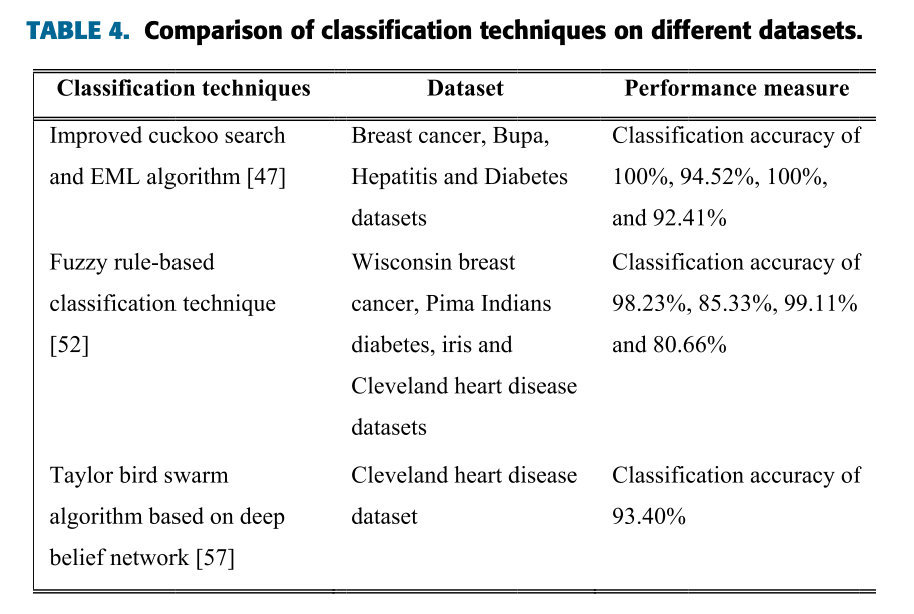
Jain和Singh[38]开发了一种自适应SVM分类技术来诊断慢性病。在这篇文献中,混合PCA和reliefF技术被用于支持向量机的参数优化,以获得较高的分类精度。为了研究开发的系统性能,九个慢性病数据集用于医疗诊断。大量实验表明,所开发的系统大大减少了数据库的维数,提高了分类器的有效性,减少了计算时间和成本。Yu等人[54]介绍了一种用于微阵列数据分类的混合自适应集成学习(HAEL)系统。开发的系统在KEEL和实时微阵列数据库上表现良好。Dennis和Muthukrishnan[55]利用自适应遗传模糊系统优化医疗数据分类过程的成员函数和规则。此外,Chandra和Kaur[56]使用自适应KNN分类技术进行肝硬化和淋巴结诊断。Alhassan和Zainon[57]提出了一种新的方法,即基于深度信念网络的Taylor鸟群算法用于心脏病诊断,这是一种用于医疗决策的医疗数据分类方法。该方法分类准确率达93.4%。实验表明,与SVM、NB和DBN技术相比,Taylor BSA–DBN大大降低了数据库的维数,提高了分类器的有效性,并减少了计算时间和成本。该方法在实时医学数据库上的分类准确率达到90%,优于传统的KNN方法。通过比较传统分类技术、并行分类技术和自适应分类技术,并行分类技术在提高慢性病诊断系统的预测准确性方面具有巨大潜力。不同数据集上分类技术的比较如表4所示。
V. PERFORMANCE MEASURES USED IN CHRONIC DISEASE CLASSIFICATION
在医疗诊断系统中,通过使用不同的性能度量来分析分类的性能;精确度、召回率、f-度量、准确性、特异性、Fowlkes-Mallows指数(FMI)等。通常,这些性能度量用于分析不同分类模型的性能。
精密度:确定为真阳性与假阳性和真阳性之和的比率。在所有预测的积极观察中,精度是正确预测的积极观察的比率。精度的数学表达式在方程式(1)中定义。
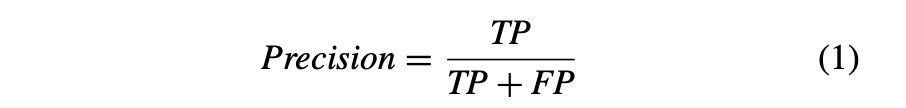
召回率:它被定义为真阳性与假阴性和真阳性之和的比率,在方程式(2)中用数学表示。
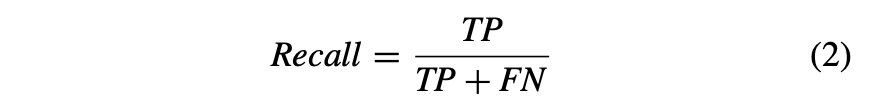
F-度量:定义为精确性和召回率的加权调和平均值,如等式3所述)
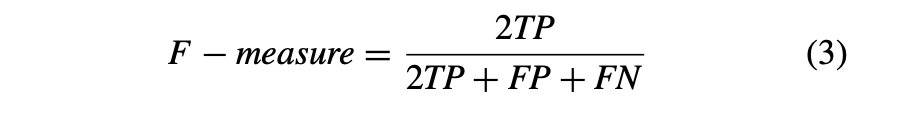
准确性:这是慢性病诊断中使用的最直观的性能指标,它是总观察值中正确预测的观察值的比率。精度的数学表达式定义在方程式(4)中。

特异性:定义为正确识别阴性的比例。特异性也被称为真阴性率,用数学公式(5)表示。
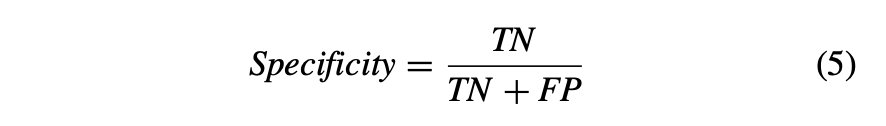
FMI:它被定义为召回率和精度之间的几何平均值。FMI在方程式(6)中用数学表示。
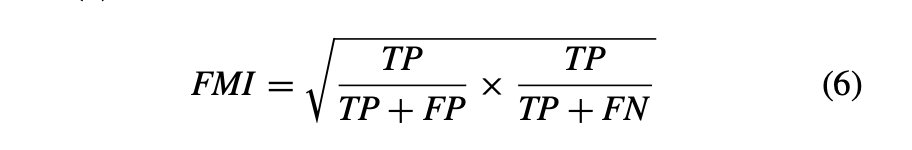
其中TP表示为真正,TN表示为,真阴性,FP表示为假阳性,FN表示为假阴性。
VI. CONCLUSION
本文综述了目前用于慢性病有效诊断的特征选择、降维和分类器。在医疗诊断系统中,还对用于评估分类器性能的性能指标进行了综述。此外,本文还比较了几种特征选择、降维和分类技术的优缺点。此外,本文还根据数据挖掘任务、搜索策略和评估标准对特征选择技术进行了分类。特征选择技术的研究表明,与包装器技术和嵌入式技术相比,过滤技术在识别最优特征子集方面效率更高,性能更好。这篇调查文章揭示了当前特征选择的优势是混合技术,这些技术被用于慢性病数据库,以消除噪声、冗余和不重要的特征。另一方面,许多分类技术被用于慢性病诊断,如与传统分类器相关的SVM、朴素贝叶斯、决策树、神经网络、随机森林等,自适应并行分类技术在慢性病诊断中具有较高的成功率和较低的计算时间。现有的大多数研究主要集中在传统的医学诊断分类技术上。本文综述了自适应分类和并行分类技术,通过提供高诊断和分类精度,显著提高了慢性病诊断的性能。这些分类技术有助于医疗专业人员、医生、内科医生和临床医生做出有效的慢性病诊断决策。
VII. RESEARCH GAP
这篇综述文章建议,未来慢性病检测的研究应集中于开发新的混合分类技术,以提高分类精度和优化结果的计算效率。近几十年来,人们对几种分类系统进行了卓有成效的研究。现有的工作主要集中在使用传统的分类系统进行医学诊断。