1. 基本信息
| 题目 | 论文作者与单位 | 来源 | 年份 |
|---|---|---|---|
| Parameter-Efficient Transfer Learning for NLP | Neil Houlsby等Google Research,雅盖隆大学-波兰 | PMLR | 2019 |
Houlsby N, Giurgiu A, Jastrzebski S, et al. Parameter-efficient transfer learning for NLP[C]//International Conference on Machine Learning. PMLR, 2019: 2790-2799.
论文链接:http://proceedings.mlr.press/v97/houlsby19a.html
论文代码:
2. 要点
| 研究主题 | 问题背景 | 核心方法流程 | 亮点 | 数据集 | 结论 | 论文类型 | 关键字 |
|---|---|---|---|---|---|---|---|
| 大模型微调 | 微调参数不高效或无效 | 提出Adapter模块。基于Bert模型来进行实验,26个不同的分类任务。 | 针对每个任务仅添加少量可训练参数,之前网络的参数固定,参数高度复用。 | 26个分类。包括GLUE benchmark。 | 在训练很少的参数的情况下,可以接近训练全参数的效果。Adapter的GLUE得分为80.0,而完全微调为80.4。 | 模型方法 | PETL,Adapter |
引入Adapter的目标:对于N个任务,完全微调模型需要N x 预训练模型的参数数量。可是Adapter的目标是达到微调相当的性能,但总参数训练更少,理想情况下接近1 ×。
3. 模型(核心内容)
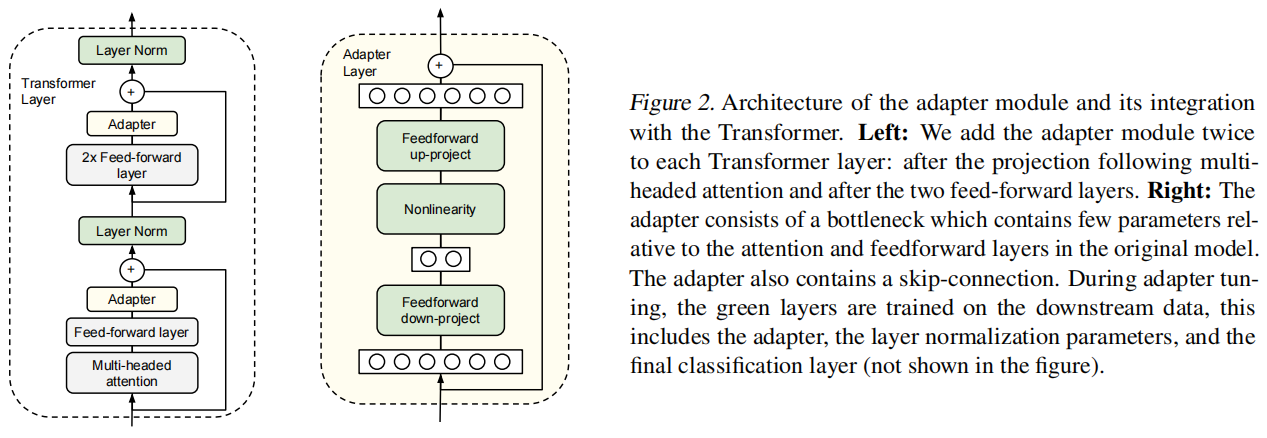
Adapter与transformer的结合框架。
在Transformer中的两个地方增加,一个地方在projection后面,一个地方在两个前向层后面;
对于每个Adapter层像一个瓶颈。它的参数比较原始模型少很多,也包含skip-connection. 只更新绿色部分部分。
4. 实验与分析
AutoML平台进行实验的。
4.1 数据集
GLUE benchmark
17个公开数据
SQuAD question answering
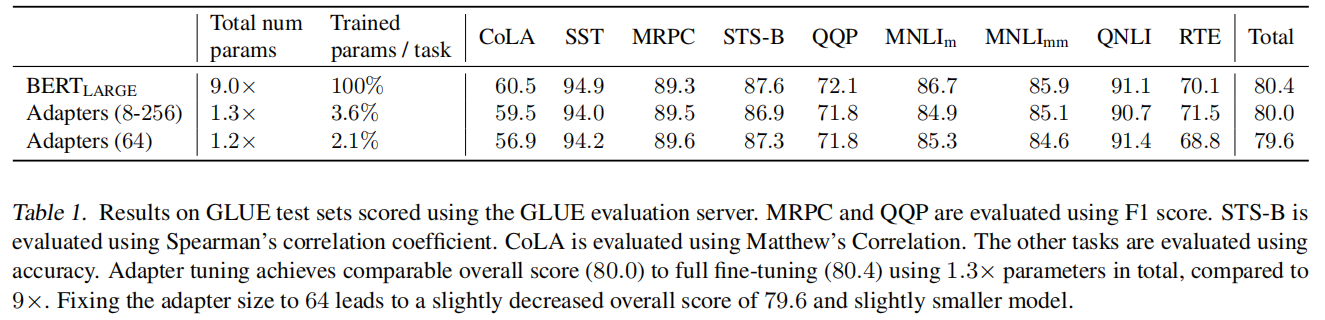
4.2 GLUE benchmark的结果
GLUE得分为80.0,而完全微调为80.4。
BERT_LARGE模型的总调参数为9.0 x ,表示这9个任务都得微调的总和;
Adapters的最好效果为80.0,而参数总量只为1.3倍于原模型参数据,训练的参数只有3.6%.
5. 小结
提出了与transformer相结合的adapter模型,可以在训练少参数的情况下达到全调的效果。想法很不错,效果也是比较好的。