先导知识
前言
预训练模型按照训练方式或者网络结构可以分成三类:
一是以BERT[2]为代表的自编码(Auto-Encoding)语言模型,它使用MLM做预训练任务,自编码预训模型往往更擅长做判别类任务,或者叫做自然语言理解(Natural Language Understanding,NLU)任务,例如文本分类,NER等。
二是以GPT[3]为代表的自回归(Auto-Regressive)语言模型,它一般采用生成类任务做预训练,类似于我们写一篇文章,自回归语言模型更擅长做生成类任务(Natural Language Generating,NLG),例如文章生成等。
还有一类是以encoder-decoder为基础模型架构的预训练模,例如MASS[4],它通过编码器将输入句子编码成特征向量,然后通过解码器将该特征向量转化成输出文本序列。基于Encoder-Decoder的预训练模型的优点是它能够兼顾自编码语言模型和自回归语言模型:在它的编码器之后接一个分类层便可以制作一个判别类任务,而同时使用编码器和解码器便可以做生成类任务。
这里要介绍的统一语言模型(Unified Language Model,UniLM)[1]从网络结构上看,它的结构是和BERT相同的编码器的结构。但是从它的预训练任务上来看,它不仅可以像自编码语言模型那样利用掩码标志的上下文进行训练,还可以像自回归语言模型那样从左向右的进行训练。甚至可以像Encoder-Decoder架构的模型先对输入文本进行编码,再从左向右的生成序列。
1. UniLM详解
我们刚介绍到,三种不同的类型的预训练架构往往需要使用不同的预训练任务进行训练。但是这些任务都可以归纳为根据已知的内容预测未知的内容,不同的是哪些内容是我们已知的,哪些是需要预测的。UniLM最核心的内容将用来训练不同架构的任务都统一到了一种类似于掩码语言模型的框架上,然后通过一个变量掩码矩阵(Mask Matrix) ![]() 来适配不同的任务。UniLM所有核心的内容可以概括为图1。
来适配不同的任务。UniLM所有核心的内容可以概括为图1。

图1:UniLM的网络结构以及它不同的预训练任务。
1.1 模型输入
首先对于一个输入句子,UniLM采用了WordPiece的方式对其进行了分词。除了分词得到的token嵌入,UniLM中添加了位置嵌入(和BERT相同的方式)和用于区分文本对的两个段的段嵌入(Segment Embedding)。为了得到整句的特征向量,UniLM在句子的开始添加了[SOS]标志。为了分割不同的段,它向其中添加了[EOS]标志。具体例子可以参考图1中的蓝色虚线框中的内容。
1.2 网络结构
如图1红色虚线框中的内容,UniLM使用了 L层Transformer的架构,为了区分使不同的预训练任务可以共享这个网络,UniLM在其中添加了掩码矩阵的运算符。具体的讲,我们假设输入文本表示为 ![]() ,它经过嵌入层后得到第一层的输入
,它经过嵌入层后得到第一层的输入![]() ,然后经过
,然后经过 ![]() 层Transformer后得到最终的特征向量,表示为
层Transformer后得到最终的特征向量,表示为![]() 。 不同于原始的Transformer,UniLM在其中添加了掩码矩阵,以第 l 层为例,此时Transformer转化为式(1)到式(3)所示的形式。
。 不同于原始的Transformer,UniLM在其中添加了掩码矩阵,以第 l 层为例,此时Transformer转化为式(1)到式(3)所示的形式。
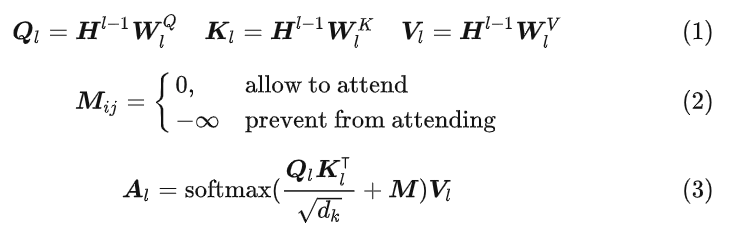
其中 ![]() 分别是Transformer的Query,Key,Value的权值矩阵,
分别是Transformer的Query,Key,Value的权值矩阵, ![]() 是我们前面多次提到过的用于控制预训练任务的掩码矩阵。通过覆盖被编码的特征,让预测时只能关注到与特定任务相关的特征,从而实现了不同的预训练方式。那么他具体的工作方式是什么呢?
是我们前面多次提到过的用于控制预训练任务的掩码矩阵。通过覆盖被编码的特征,让预测时只能关注到与特定任务相关的特征,从而实现了不同的预训练方式。那么他具体的工作方式是什么呢?
1.3 任务统一
UniLM共有4个预训练任务,除了图1中所示的三个语言模型外,还有一个经典的NSP任务,下面我们分别介绍它们。
双向语言模型:双向语言模型是图1的最上面的任务,它和掩码语言模型一样,就是利用上下文预测被掩码的部分。在这种训练方式中,因为模型需要根据所有的上下文分析,所以 � 是一个0矩阵。
单向语言模型:单向语言模型可以使从左向右也可以是从右向左,图1的例子是从左向右的,也就是GPT[3]中使用的掩码方式。在这种预测方式中,模型在预测第t时间片的内容时只能看到第t时间片之前的内容,因此 � 是一个上三角全为 −∞ 的上三角矩阵(图1中第二个掩码矩阵的阴影部分)。同理,当单向语言模型是从右向左时, � 是一个下三角矩阵。
Seq-to-Seq语言模型:在Seq-to-Seq任务中,例如机器翻译,我们通常先通过编码器将输入句子编码成特征向量,然后通过解码器将这个特征向量解码成预测内容。UniLM的结构和传统的Encoder-Decoder模型的差异非常大,它仅有一个多层的Transformer构成。在进行预训练时,UniLM首先将两个句子拼接成一个序列,并通过[EOS]来分割句子,表示为:[SOS]S1[EOS]S2[EOS]。在编码时,我们需要知道输入句子的完整内容,因此不需要对输入文本进行覆盖。但是当进行解码时,解码器的部分便变成一个从左向右的单向语言模型。因此对于句子中的第1个片段(S1部分)对应的块矩阵,它是一个0矩阵(左上块矩阵),对于的句子第2个片段(S2部分)的对应的块矩阵,它是上三角矩阵的一部分(右上块矩阵)。因此我们可以得到图1中最下面的 � 。可以看出,UniLM虽然采用了编码器的架构,但是在训练Seq-to-Seq语言模型时它也可以像经典的Encoder-to-Decoder那样关注到输入的全部特征以及输出的已生成的特征。
NSP:UniLM也像BERT一样添加了NSP作为预训练任务。
1.4 训练与微调
训练:在训练时,1/3的时间用来训练双向语言模型,1/3的时间用来训练单向语言模型,其中从左向右和从右向左各站一半,最后1/3用了训练Encoder-Decoder架构。
微调:对于NLU任务来说,我们可以直接将UniLM视作一个编码器,然后通过[SOS]标志得到整句的特征向量,再通过在特征向量后添加分类层得到预测的类别。对于NLG任务来说,我们可以像前面介绍的把句子拼接成序列“[SOS]S1[EOS]S2[EOS]”。其中S1是输入文本的全部内容。为了进行微调,我们会随机掩码掉目标句子S2的部分内容。同时我们可会掩码掉目标句子的[EOS],我们的目的是让模型自己预测何时预测[EOS]从而停止预测,而不是预测一个我们提前设置好的长度。
2. 总结
UniLM和很多Encoder-Decoder架构的模型一样(例如MASS)像统一NLU和NLG任务,但是无疑UniLM的架构更加优雅。像MASS在做NLU任务时,它只会采用模型的Encoder部分,从而丢弃了Decoder部分的全部特征。UniLM有一个问题是在做机器翻译这样经典的Seq-to-Seq任务时,它的掩码机制导致它并没有使用表示[SOS]标志对应的全句特征,而是使用了输入句子的序列。这个方式可能缺乏了对整句特征的捕获,从而导致生成的内容缺乏对全局信息的把控。
Reference
[1] Dong, Li, et al. "Unified language model pre-training for natural language understanding and generation." Advances in Neural Information Processing Systems 32 (2019).
[2] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[3] Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training.
[4] Song, Kaitao, et al. "Mass: Masked sequence to sequence pre-training for language generation."arXiv preprint arXiv:1905.02450(2019).
[5] Wu, Yonghui, et al. "Google's neural machine translation system: Bridging the gap between human and machine translation." arXiv preprint arXiv:1609.08144 (2016).