目录
- 任务内容
-
- (1)将数据进行转置,转置后型如eg.csv, 缺失值用NAN代替。
- (2) 对数据中的异常值进行识别并用NA代替。
- (3) 计算每个用户用电数据的基本统计量,包括:最大值、最小值、均值、中位数、和、方差、偏度、峰度。(不包括空值)
- (4) 每个用户用电数据按日差分,并计算差分结果的基本统计量,统计量同上述第3问。
- (5) 计算每个用户用电数据的5%分位数。
- (6) 对每个用户的用电数据按周求和并差分(一周7天),计算差分结果的基本统计量,统计量同第3问。
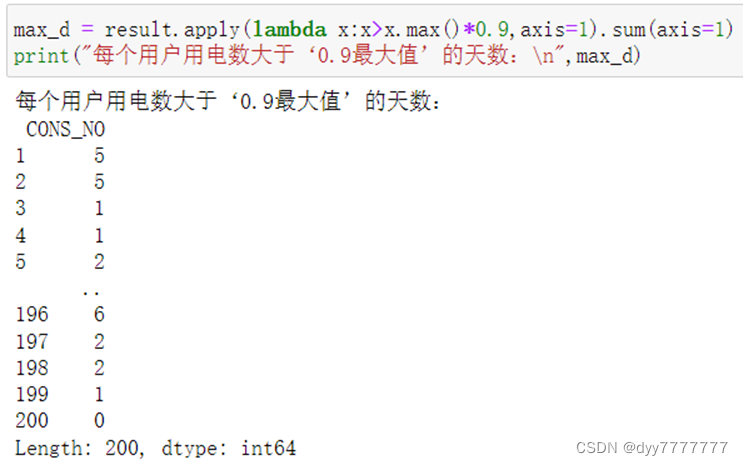
- (7) 每个用户在一段时间内会有用电数据最大值,统计用电数大于‘0.9×最大值’的天数。
- (8) 获取每个用户用电数据出现最大值和最小值的月份,若最大值(最小值)存在于多个月份,则输出含有最大值(最小值)最多的那个月份。我们按天统计每个用户的用电数据,假设1号用户用电量的最小值为0(可能是当天外出没有用电),在一年的12个月,每个月都有可能有若干天用电量为0,那么就输出含有最多用电量为0的天数所在的月份。最大用电量统计同理。
- (9) 以每个用户7月和8月用电数据为同一批统计样本,3月和4月用电数据为另一批统计样本,分别计算这两批样本之间的总体和(sum)之比,均值(mean)之比,最大值(max)之比和最小值(min)之比。
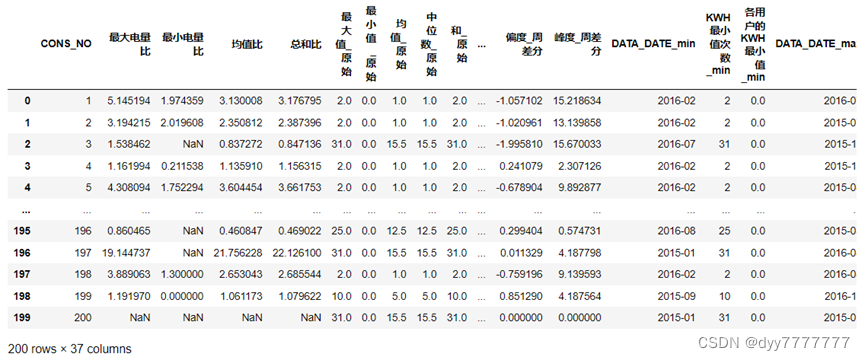
- (10)将上述统计的所有特征合并在一张表格中显示出来。
任务内容
给定数据文件data.csv,其中记录的是用户用电数据。数据中有编号为1~200的200位用户,DATA_DATE表示时间,如:2015/1/1表示2015年1月1日, KWH表示用电量。请用给定的数据,实现以下任务:
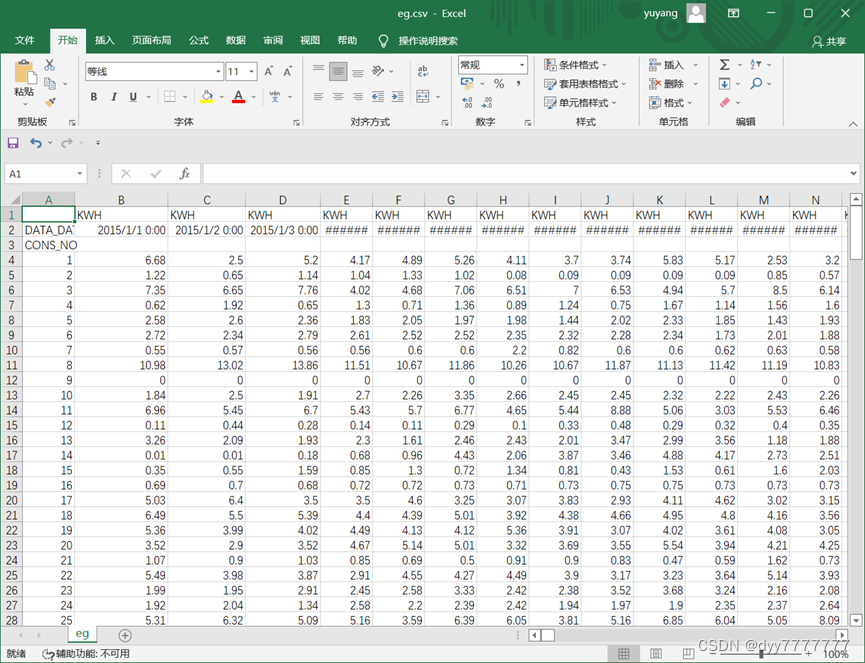
(1)将数据进行转置,转置后型如eg.csv, 缺失值用NAN代替。
(2) 对数据中的异常值进行识别并用NA代替。
(3) 计算每个用户用电数据的基本统计量,包括:最大值、最小值、均值、中位数、和、方差、偏度、峰度。(不包括空值)
(4) 每个用户用电数据按日差分,并计算差分结果的基本统计量,统计量同上述第3问。
(5) 计算每个用户用电数据的5%分位数。
(6) 对每个用户的用电数据按周求和并差分(一周7天),计算差分结果的基本统计量,统计量同第3问。
(7) 每个用户在一段时间内会有用电数据最大值,统计用电数大于‘0.9×最大值’的天数。
(8) 获取每个用户用电数据出最大值和最小值的月份,若最大值(最小值)存在于多个月份,则输出含有最大值(最小值)最多的那个月份。我们按天统计每个用户的用电数据,假设1号用户用电量的最小值为0(可能是当天外出没有用电),在一年的12个月,每个月都有可能有若干天用电量为0,那么就输出含有最多用电量为0的天数所在的月份。最大用电量统计同理。
(9) 以每个用户7月和8月用电数据为同一批统计样本,3月和4月用电数据为另一批统计样本,分别计算这两批样本之间的总体和(sum)之比,均值(mean)之比,最大值(max)之比和最小值(min)之比。
(10)将上述统计的所有特征合并在一张表格中显示出来。
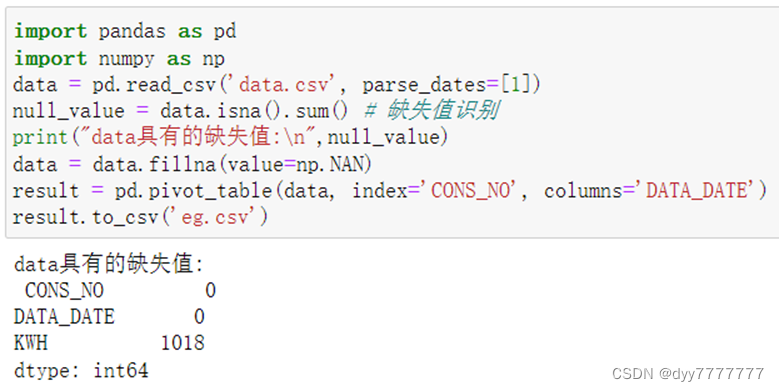
(1)将数据进行转置,转置后型如eg.csv, 缺失值用NAN代替。
import pandas as pd
import numpy as np
data = pd.read_csv('data.csv', parse_dates=[1])
null_value = data.isna().sum() # 缺失值识别
print("data具有的缺失值:\n",null_value)
data = data.fillna(value=np.NAN)
result = pd.pivot_table(data, index='CONS_NO', columns='DATA_DATE')
result.to_csv('eg.csv')
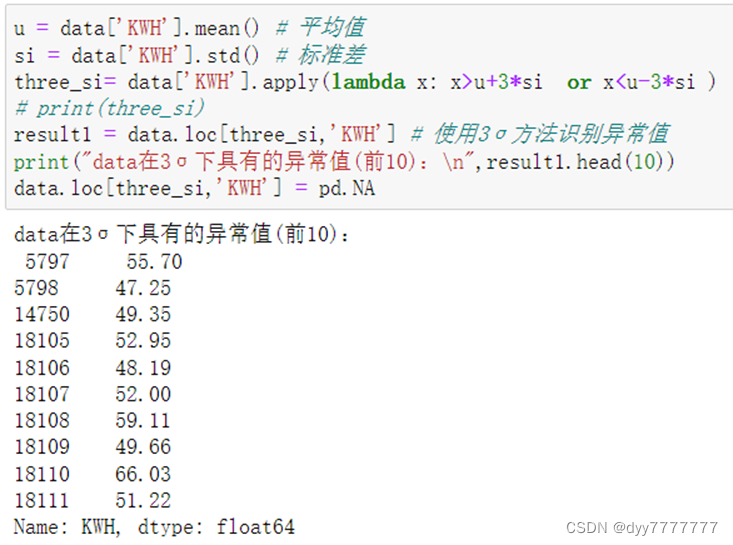
(2) 对数据中的异常值进行识别并用NA代替。
u = data['KWH'].mean() # 平均值
si = data['KWH'].std() # 标准差
three_si= data['KWH'].apply(lambda x: x>u+3*si or x<u-3*si )
# print(three_si)
result1 = data.loc[three_si,'KWH'] # 使用3σ方法识别异常值
print("data在3σ下具有的异常值(前10):\n",result1.head(10))
data.loc[three_si,'KWH'] = pd.NA
(3) 计算每个用户用电数据的基本统计量,包括:最大值、最小值、均值、中位数、和、方差、偏度、峰度。(不包括空值)
def statistics(df): # 数据统计并合并统计量
statistical_table = pd.concat([df.max(), df.min(), df.mean(), df.median(), df.sum(), df.var(), df.skew(), df.kurt()],axis=1)
statistical_table.columns = ['最大值','最小值','均值','中位数','和','方差','偏度','峰度']
return statistical_table
# 对其输出
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
pd.set_option('display.width',180)
print("每个用户用电数据的基本统计量:\n",statistics(result.T))
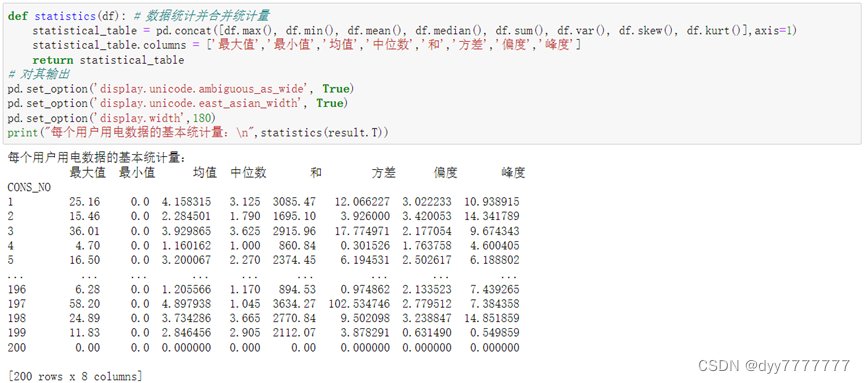
(4) 每个用户用电数据按日差分,并计算差分结果的基本统计量,统计量同上述第3问。
difference = result.diff(axis=1)
difference.T #每个用户用电数据按日差分
print("每个用户用电数据按日差分的基本统计量:\n",statistics(difference.T))
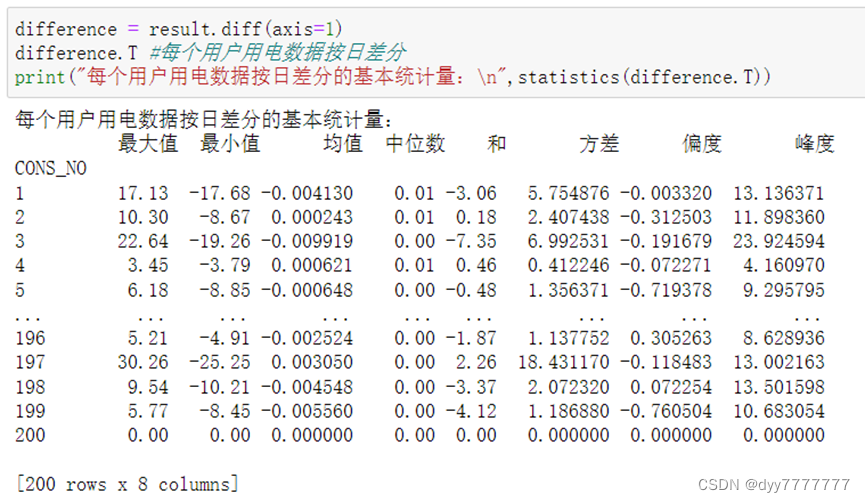
(5) 计算每个用户用电数据的5%分位数。
print("每个用户的5%分位数为:\n",result.quantile(0.05,axis=1))#运用df.quantile()函数求分位数
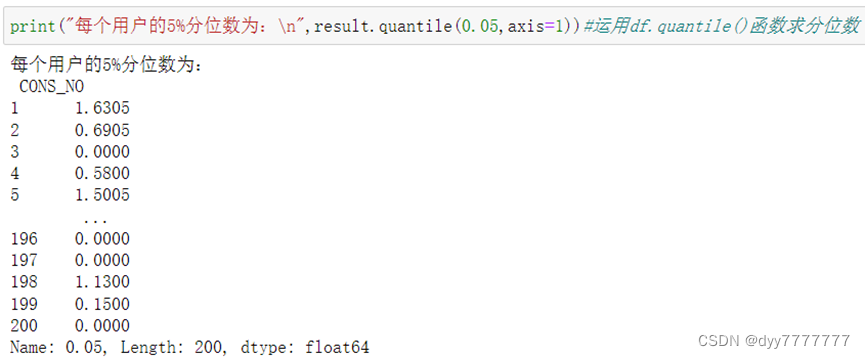
(6) 对每个用户的用电数据按周求和并差分(一周7天),计算差分结果的基本统计量,统计量同第3问。
w_index = pd.PeriodIndex(data['DATA_DATE'], freq='w')#重组时间序列
sum_week = data.groupby(by=['CONS_NO', w_index]).sum()
week_table = pd.pivot_table(sum_week, index='DATA_DATE', columns='CONS_NO')
diff_week = week_table.diff(1)#差分
print("每个用户按周求和并差分:\n",diff_week)
print("每个用户按周求和并差分的基本统计量:\n",statistics(diff_week))
(7) 每个用户在一段时间内会有用电数据最大值,统计用电数大于‘0.9×最大值’的天数。
max_d = result.apply(lambda x:x>x.max()*0.9,axis=1).sum(axis=1)
print("每个用户用电数大于‘0.9最大值’的天数:\n",max_d)
(8) 获取每个用户用电数据出现最大值和最小值的月份,若最大值(最小值)存在于多个月份,则输出含有最大值(最小值)最多的那个月份。我们按天统计每个用户的用电数据,假设1号用户用电量的最小值为0(可能是当天外出没有用电),在一年的12个月,每个月都有可能有若干天用电量为0,那么就输出含有最多用电量为0的天数所在的月份。最大用电量统计同理。
最大值:
data['flag']=data.groupby('CONS_NO')['KWH'].apply(lambda x:x==x.max())#为每个最大值的记录打上标记
data['MAX']=data.groupby('CONS_NO')['KWH'].transform('max')#记录最大值
max_index = data[data.flag == True].index #筛出最大值的记录
surface_max = data.iloc[max_index]
#print(surface_max) #筛选出的数据
key = pd.PeriodIndex(surface_max['DATA_DATE'], freq='m')
max_count = surface_max.groupby(by=['CONS_NO', key])['KWH'].count()# 按月进行分组,统计每个月份最大值数量
max_count_df = pd.DataFrame(max_count)
max_count_df_index = max_count_df.reset_index().groupby('CONS_NO')['KWH'].idxmax()#筛出数量最多的月份
max_result = max_count_df.iloc[max_count_df_index]
max_result.columns = ['KWH最大值次数']
#print(max_result) # 最大值数量
key = pd.PeriodIndex(data['DATA_DATE'], freq='m')
month = data.groupby(by=['CONS_NO', key])['KWH'].max()# 按月进行分组
month_df = pd.DataFrame(month)
max_index = month_df.reset_index().groupby('CONS_NO')['KWH'].idxmax()#筛出用户KWH最大值
max_value = month_df.iloc[max_index]
#print(max_value) # 最大值
max_result=max_result.copy()
max_result.loc[:,'各用户的KWH最大值']=max_value.values
print(max_result)

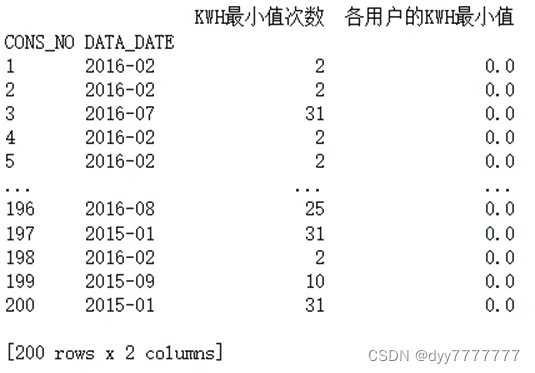
最小值:
data['flag']=data.groupby('CONS_NO')['KWH'].apply(lambda x:x==x.min())#为每个最小值的记录打上标记
data['MIN']=data.groupby('CONS_NO')['KWH'].transform('min')#记录最小值
min_index = data[data.flag == True].index #筛出最小值的记录
surface_min = data.iloc[min_index]
#print(surface_min) #筛选出的数据
key = pd.PeriodIndex(surface_min['DATA_DATE'], freq='m')
min_count = surface_min.groupby(by=['CONS_NO', key])['KWH'].count()# 按月进行分组,统计每个月份最小值数量
min_count_df = pd.DataFrame(min_count)
min_count_df_index = min_count_df.reset_index().groupby('CONS_NO')['KWH'].idxmax()#筛出数量最多的月份
min_result = min_count_df.iloc[min_count_df_index]
min_result.columns = ['KWH最小值次数']
#print(min_result) # 最小值数量
key = pd.PeriodIndex(data['DATA_DATE'], freq='m')
month = data.groupby(by=['CONS_NO', key])['KWH'].min()# 按月进行分组
month_df = pd.DataFrame(month)
min_index = month_df.reset_index().groupby('CONS_NO')['KWH'].idxmin()#筛出用户KWH最小值
min_value = month_df.iloc[min_index]
#print(min_value) # 最小值
min_result=min_result.copy()
min_result.loc[:,'各用户的KWH最小值']=min_value.values
print(result)
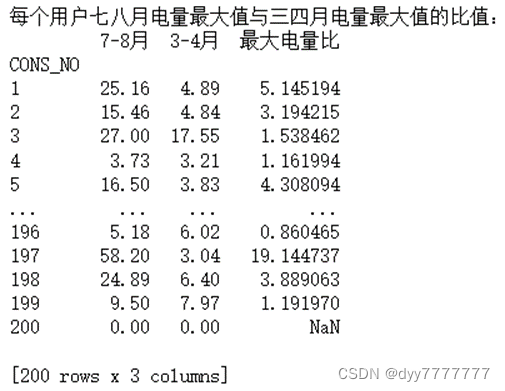
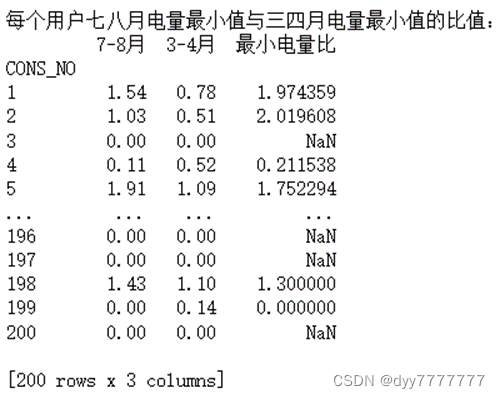
(9) 以每个用户7月和8月用电数据为同一批统计样本,3月和4月用电数据为另一批统计样本,分别计算这两批样本之间的总体和(sum)之比,均值(mean)之比,最大值(max)之比和最小值(min)之比。
data = pd.read_csv('data.csv', parse_dates=[1])#重新加载数据(之前加载的data已被修改)
def date_filter(df): # 日期筛选,返回两张表
idx = pd.IndexSlice
mon78 = df.loc[idx[:,['2015-7','2015-8', '2016-7', '2016-8']],:]
mon34 = df.loc[idx[:,['2015-3','2015-4', '2016-3', '2016-4']],:]
return mon78, mon34
def date_merge(df_1, df_2, name): # 合并符合要求的日期,同时进行比值处理
df_ratio = pd.merge(df_1, df_2, on='CONS_NO')
df_ratio.columns = ['7-8月', '3-4月']
df_ratio[name] = df_ratio['7-8月'] / df_ratio['3-4月']
return df_ratio
def analysis(df): # 每月数据统计
a_table = pd.concat([df.max()['KWH'], df.min()['KWH'], df.mean(), df.sum()],axis=1)
a_table.columns = ['最大值','最小值','均值','和']
return a_table
def analysis2(df):# 筛选出来的数据统计
a2_table = pd.concat([df['最大值'].max(),df['最小值'].min(),df['均值'].mean(),df['和'].sum()],axis=1)
return a2_table
m_index = pd.PeriodIndex(data['DATA_DATE'], freq='m')
m_all = data.groupby(['CONS_NO', m_index])# 按月进行分组
t=analysis(m_all)
mon78,mon34 = date_filter(t)
mon_78 = analysis2(mon78.groupby('CONS_NO'))
mon_34 = analysis2(mon34.groupby('CONS_NO'))
col = ['最大值','最小值','均值','和']
names=['最大电量比','最小电量比','均值比','总和比']
summary_table = pd.DataFrame()
for i in range(4):
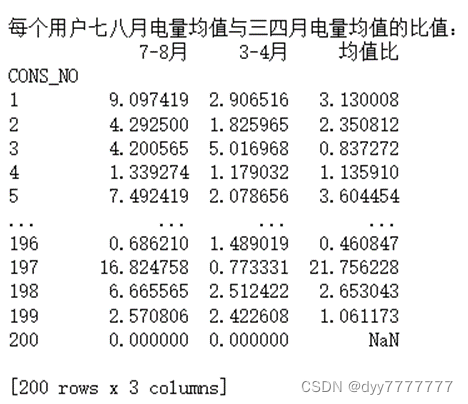
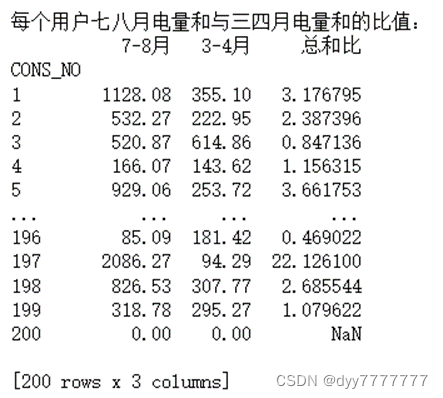
print('每个用户七八月电量%s与三四月电量%s的比值:'%(col[i],col[i]))
ratio_table = date_merge(mon_78[col[i]], mon_34[col[i]], names[i])
summary_table[names[i]] = ratio_table[names[i]]
print(ratio_table,'\n')
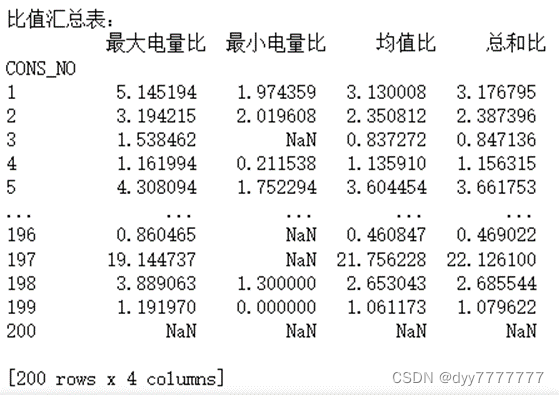
print('比值汇总表:\n',summary_table)
(10)将上述统计的所有特征合并在一张表格中显示出来。
def rename_columns(df,add):#统计量重命名
new_col = list()
for i in df.columns:
if i != 'CONS_NO':
new_col.append(i+add)
else:
new_col.append(i)
df.columns=new_col
return df
df1 ,df2,df3,df4 ,df5= statistics(result.T),statistics(difference.T),statistics(diff_week),min_result.reset_index(),max_result.reset_index()
df6,df7= pd.DataFrame(result.quantile(0.05,axis=1)),pd.DataFrame(max_d)
adds = ['_原始','_日差分','_周差分','_min','_max']
new = ['5%分位数','kwh>0.9max的天数']
dfs=[df1,df2,df3,df4,df5,df6,df7]#合并表单的集合
all_feature_tables = summary_table
for i in range(len(dfs)):
if i < 5:
a = rename_columns(dfs[i],adds[i])
all_feature_tables = pd.merge(all_feature_tables,a,on='CONS_NO')
elif i < 7:
dfs[i].columns=[new[i-5]]
all_feature_tables = pd.merge(all_feature_tables,dfs[i],on='CONS_NO')
all_feature_tables #展示总表