1.Pandas的数据结构 Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
一个Series相当于DataFrame中的一列,Series索引值相当于DataFrame中的左侧行索引
import pandas as pd
a = [1, 2, 3]
pd1 = pd.Series(a)
print(pd1)

从上图可知,如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据。
如,pd1[0]取到的值为1
通过index参数指定索引:
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index=["x", "y", "z"])
print(myvar)
#x Google
#y Runoob
#z Wiki
#dtype: object
我们也可以使用 key/value 对象,类似字典来创建 Series:
sites = {
1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)
#输出与上例相似
如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可,如下实例:
myvar2 = pd.Series(sites, index=[1, 3])
print(myvar2)
#1 Google
#3 Wiki
#dtype: object
2.Pandas的数据结构DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
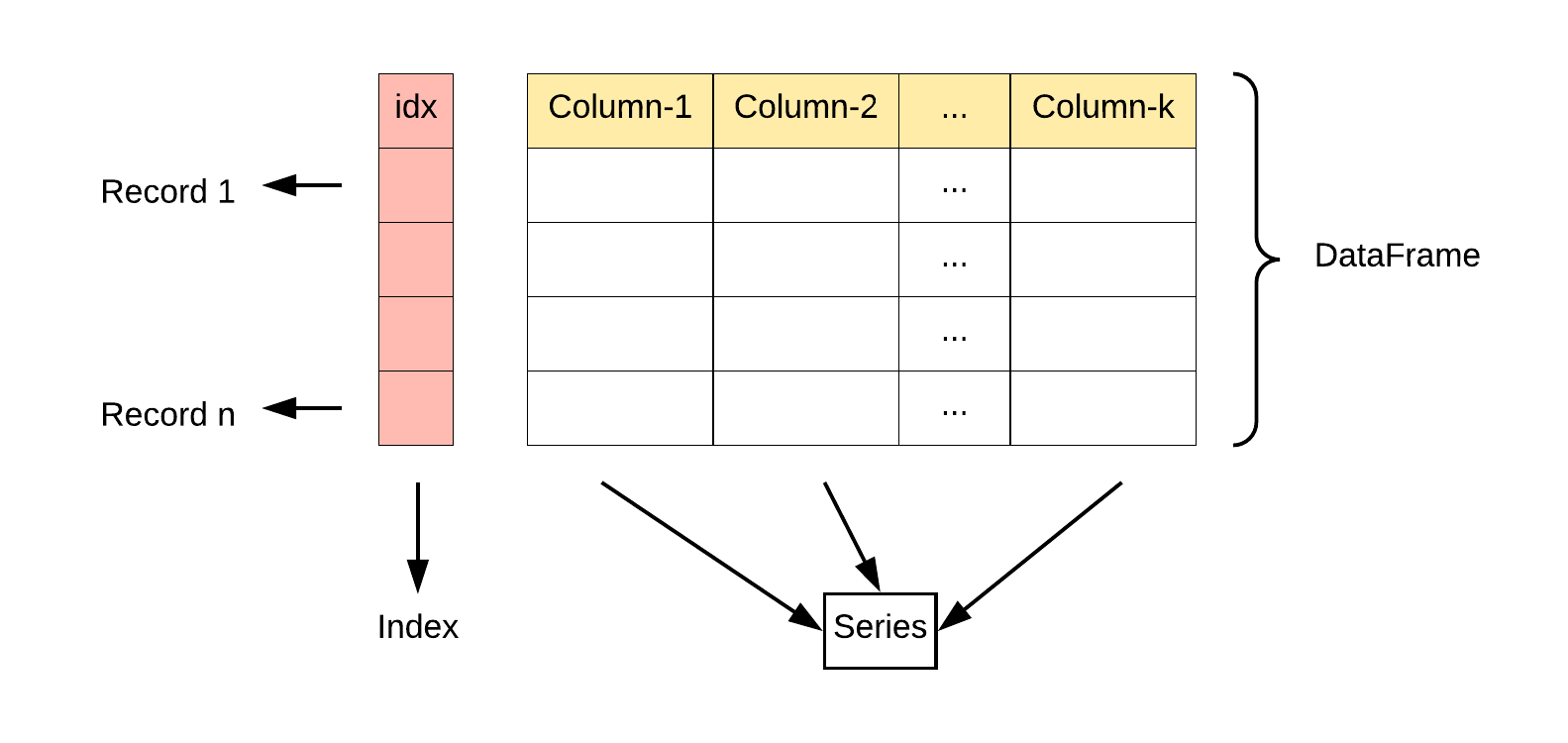
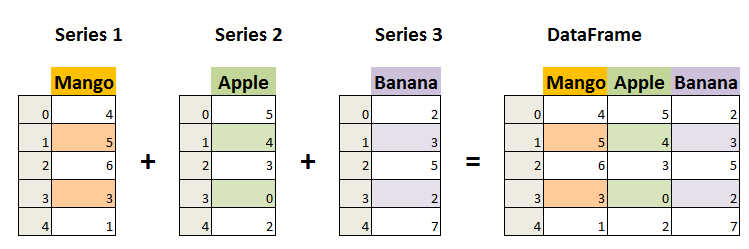
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
参数说明:
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:索引值,或者可以称为行标签。
- columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
Pandas DataFrame 是一个二维的数组结构,类似二维数组。
#构建的列表为(4, 2)
data = [['火车', '交通工具'], ['狗', '动物'], ['玫瑰花', '植物'], ['蘑菇', '真菌']]
df1 = pd.DataFrame(data, columns=['名称', '分类'], dtype=float)
print(df1)
# 名称 分类
#0 火车 交通工具
#1 狗 动物
#2 玫瑰花 植物
#3 蘑菇 真菌
以下实例使用 ndarrays 创建,ndarray 的长度必须相同, 如果传递了 index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
#每个:后的数据为一列
data = {
'Site': ['Google', 'Runoob', 'Wiki'], 'Age': [10, 12, 13]}
df2 = pd.DataFrame(data)
# Site Age
#0 Google 10
#1 Runoob 12
#2 Wiki 13
还可以使用字典(key/value),其中字典的 key 为列名:
#每个词典是一行,所有词典的key应该相对于应,缺省值为NaN
data = [{
'a': 1, 'b': 2}, {
'a': 5, 'b': 10, 'c': 20}]
# a b c
#0 1 2 NaN
#1 5 10 20.0
Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])
**注意:**返回结果其实就是一个 Pandas Series 数据。
也可以返回多行数据,使用 [[ … ]] 格式,… 为各行的索引,以逗号隔开
# 返回第一行和第二行
print(df.loc[[0, 1]])