基本概念
1)is_leaf
叶子节点和非叶子节点的区别:计算图中的节点分为叶子节点和非叶子节点,叶子节点可以理解成没有其他tensor再利用它进行计算(例如b = a+1,那么b需要a进行计算,那么a就不是叶子结点,b是叶子节点),但是需要注意若tensor是由用户创建,则该tensor为叶子节点(即使有别的tensor利用它进行计算)。
是否是叶子结点
- 所有requires_grad为False的tensor都是叶子节点,也即is_leaf属性返回true。
- 若tensor是由用户创建,则该tensor为叶子节点。而叶子节点经过进一步计算得到的变量叫非叶子节点,叶子节点的梯度值不为None。非叶子节点的梯度值没有保存在内存中,所以对非叶子节点进行求梯度则为None。
import torch
# 若tensor是由用户创建,则该tensor为叶子节点
x = torch.tensor([1.0, 2.0, 3.0, 4.0], requires_grad=True)
print(x.is_leaf)
# 叶子节点经过进一步计算得到的变量叫非叶子节点
x = x.view(2,2)
print(x.is_leaf)
out = x.sum()
print(out.is_leaf)
out.backward()
# 非叶子节点的梯度值没有保存在内存中,所以对非叶子节点进行求梯度则为None
print(x.grad)- 由requires_grad为False的节点通过operation产生的节点还是叶子节点,此时设置requires_grad为true,不影响是否为叶子节点,但会影响后续节点是否为叶子节点。猜想这么设计的原因是:由于无法判断是否是由operation产生的节点,因此通过设置requires_grad也就无法更新是否为叶子节点。
2)grad
这是保存参数的梯度值。在进行反向传播后,对于具有 requires_grad=True 的参数,梯度会被计算并存储在 param.grad 中。对于没有梯度的参数或未计算梯度的参数,param.grad 为 None。你可以使用 param.grad 获取参数的梯度值,进而执行自定义的操作,如参数更新或梯度剪裁。
当计算梯度的时候,只有叶子节点才会保留梯度,所有中间节点(非叶子节点)的grad在计算完backward()的时候为了节约内存都会被清除掉
在使用backward()函数进行反向传播计算tensor的梯度时,并不是计算所有的tensor的梯度,而是计算满足下面这几个全部条件的tensor的梯度,
- 类型为叶子节点、
- requires_grad==True
- 依赖该tensor的所有tensor的require_grad为True
3)grad_fn
记录变量是怎么来的,例如:y = x*3,grad_fn记录了y由x计算的过程。所以:
- 当grad_fn为None时:无论requires_grad为True还是False,都为叶子变量,即只要是直接初始化的都为叶子变量。
- 当grad_fn不为None时:requires_grad = False为叶子变量,requires_grad = True为非叶子变量
4)requires_grad
这是一个布尔值属性,指示是否计算参数的梯度。默认情况下,所有模型参数的 requires_grad 属性都设置为 True,以便在进行反向传播时计算梯度。如果你想冻结参数或防止其梯度更新,可以将其设置为 False。当你冻结参数时,梯度计算会被停止,这意味着该参数不会在后续的训练迭代中更新。
按照惯例,所有属性requires_grad=False的张量是叶子节点(即:叶子张量、叶子节点张量).
对于属性requires_grad=True的张量可能是叶子节点张量也可能不是叶
子节点张量而是中间节点(中间节点张量). 如果该张量的属性requires_grad=True,
而且是用于直接创建的,也即它的属性grad_fn=None,那么它就是叶子节点.
如果该张量的属性requires_grad=True,但是它不是用户直接创建的,而是由其他张量
经过某些运算操作产生的,那么它就不是叶子张量,而是中间节点张量,并且它的属性
grad_fn不是None,比如:grad_fn=<MeanBackward0>,这表示该张量是通过torch.mean()
运算操作产生的,是中间结果,所以是中间节点张量,所以不是叶子节点张量.
判断一个张量是不是叶子节点,可以通过它的属性is_leaf来查看.
一个张量的属性requires_grad用来指示在反向传播时,是否需要为这个张量计算梯度.
如果这个张量的属性requires_grad=False,那么就不需要为这个张量计算梯度,也就
不需要为这个张量进行优化学习.
在PyTorch的运算操作中,如果参加这个运算操作的所有输入张量的属性requires_grad都
是False的话,那么这个运算操作产生的结果,即输出张量的属性requires_grad也是False,
否则是True. 即输入的张量只要有一个需要求梯度(属性requires_grad=True),那么得到的
结果张量也是需要求梯度的(属性requires_grad=True).只有当所有的输入张量都不需要求
梯度时,得到的结果张量才会不需要求梯度.
对于属性requires_grad=True的张量,在反向传播时,会为该张量计算梯度. 但是pytorch的
自动梯度机制不会为中间结果保存梯度,即只会为叶子节点计算的梯度保存起来,保存到该
叶子节点张量的属性grad中,不会在中间节点张量的属性grad中保存这个张量的梯度,这是
出于对效率的考虑,中间节点张量的属性grad是None.如果用户需要为中间节点保存梯度的
话,可以让这个中间节点调用方法retain_grad(),这样梯度就会保存在这个中间节点的grad属性中.
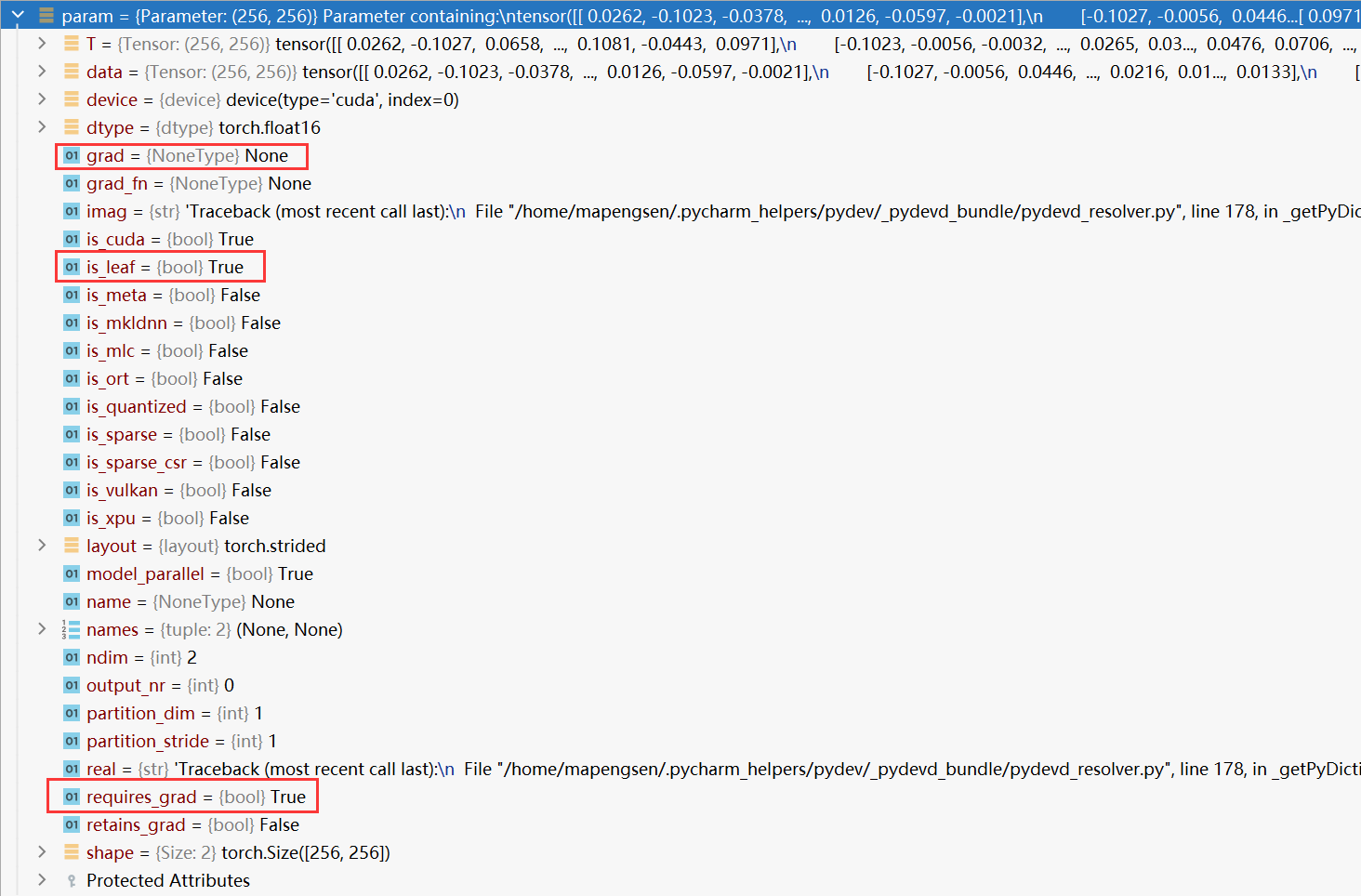
训练过程中params.grad为NoneType(值是None)
首先这并不是空,而是根本不存在,原因有很多种,比如:
- params并不是叶子节点
- params的requires_grad属性为False
- 在网络定义的时候,定义了某层网络,在前向传播时并没有用到,在输出网络梯度时,由于没有前向传播(即 def _init__(self):里面写了, 但def forward()时没有用到上面的某一层,就会有grad为NoneType的情况下,有可能是这个原因),所以没有进行反向传播,自然没有梯度信息,也就出现了nonetype类型。
- 调用backward()函数前,叶子/非叶子节点的grad属性均为none,无论是否设置了requires_grad=True(叶子节点),或者调用了retain_grad()(非叶子节点)
情况一:
import torch
a = torch.ones((2, 2), requires_grad=True).to("cuda")
b = a.sum()
b.backward()
print(a.is_leaf)
print(a.grad)输出:False、None
原因:
由于.to(device)是一次操作,此时的a已经不是叶子节点了
修改为:
import torch
a = torch.ones((2, 2), requires_grad=True)
c = a.to("cuda")
b = c.sum()
b.backward()
print(a.is_leaf)
print(a.grad)情况二:
定义参数相乘应该将所有的操作放在torch.nn.Parameter()内,而不是在外面再乘
错误:
self.miu = torch.nn.Parameter(torch.ones(self.dimensional)) * 0.01应该为
self.miu = torch.nn.Parameter(torch.ones(self.dimensional) * 0.01)grad为NoneType(值是None)怎么办?
打印全部网络的参数梯度(model.named_parameters()),查看哪层开始出现梯度消失问题:https://blog.csdn.net/weixin_43135178/article/details/131754210?
发现是这里的问题:

分别搜索“q_proj”、“.key_value”、“query_key_value”,发现它们都使用了“mpu.ColumnParallelLinear + mpu.RowParallelLinear ”,那么应该是它们这两个类的问题
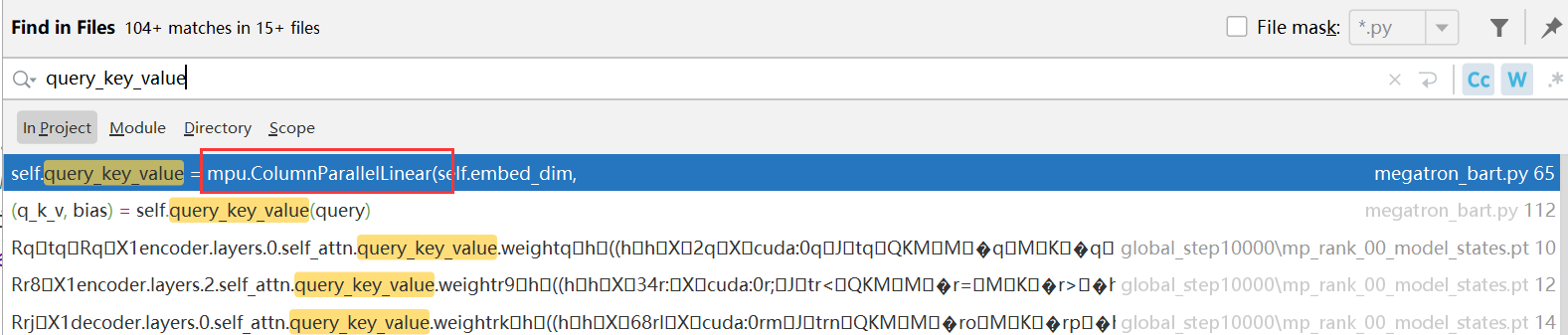
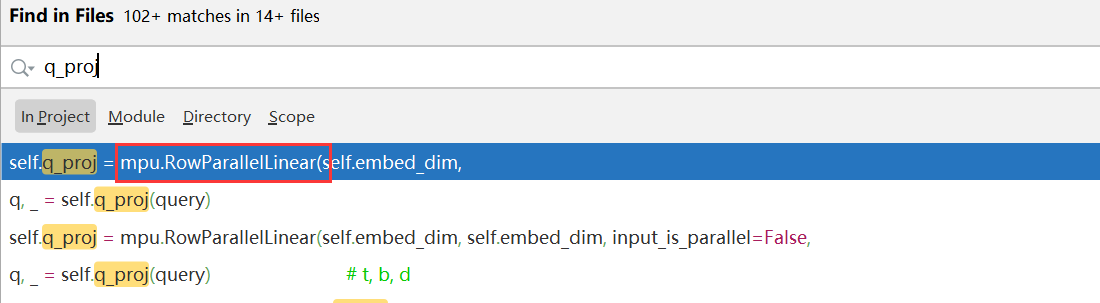

[注]主要查看是否有装饰了torch.no_grad()或者detach()函数,该装饰器会使得该函数内保留梯度
Debug解决思路有以下几种:
1. 检查该变量的梯度是否为0或者为None, 对于pytorch的中间变量,输出梯度的方式见博客: pytorch获取中间变量的梯度
如果是None或者0,说明梯度没有传到该变量,顺着代码往下一直输出变量的梯度,直到梯度出现为止,然后检查为啥梯度消失了。
2. 输出梯度后, 检查梯度乘上学习率是否过小, 比如梯度为5e-2,学习率为1e-4,而变量的值只保留五位小数,那么此时由于学习率过小使得更新被变量忽略,需要把学习率调高。
3. 最重要的是, 检查参数所在的类,是否加入了optimal的优化参数序列中.
(不然梯度虽然回传了,但优化器并不会对你的参数产生反应。 (本次,我代码出现问题的原因便是如此)
4. 检查该变量是否在optimal step函数之前被替换, 即梯度回传之后, step函数之前,该参数被重新赋值。(不常见)
注意: 如果是一个模型类的列表: 请不要用list类型,使用nn.ModuleList , 如果一个list中包含了三个A类, 把list作为B类的参数的时候(在init函数中赋值),那么这个list里面所有的参数(A类中的参数)都不会被优化, 使用nn.ModuleList可以避免这一点。
Pytorch中自定义网络参数,存在梯度但不进行更新 - 知乎
pytorch损失反向传播后梯度为none的问题_python_脚本之家
pytorch计算图、梯度相关操作、固定参数训练以及训练过程中grad为Nonetype的原因 - 知乎
Torch requires_grad / backward / is_leaf 的一些坑 - 简书
pytoch 设置了requires_grad=True,但是计算梯度(grad)为none_requires_grad=true 但是没有梯度_AINLPer的博客-CSDN博客