卷积神经网络基础+ 图像分类算法
配置环境
查看有多少个虚拟环境 conda env list
1、 安装自己的环境 conda create -n xxx python==x.xx 提倡在这一步先把Python版本定下来
2、 切换到自己的环境 conda activate xxx
3、 然后在这个环境下装包 比如pytorch
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
pytorch官网 https://pytorch.org/get-started/locally/

根据代码需求装后续代码
相关错误及解决方法:
如果出现ModuleNotFoundError: No module named ‘matplotlib’ 直接在命令行pip install相应包名
ImportError:cannot import name ‘OrderedDict’ from ‘typing’ (/home/fwq/anaconda3/envs/hudie/lib/python3.7/typing.py)
解决:在命令行输入 pip intstall typing_extensions 而后找到"/home/fwq/anaconda3/envs/hudie/lib/python3.7/site-packages/torchvision/models/maxvit.py文件,改成

命令行输入nvtop查看gpu占用情况
命令行输入 nvidia-smi 查看服务器配置
深度学习
深度学习是机器学习的一部分
其中最重要的是特征工程:
特征工程的作用:
数据特征决定了模型的上限
预处理和特征提取是最核心的
算法与参数选择决定如何逼近这个上限

神经网络就是一个黑盒子 做各种个样的变换 然后得出一个结论
对特征数据自动提取 计算机可以认识 学习的一个过程
深度学习就是计算机学习
深度学习应用
无人驾驶 高速车站 计算机视觉的识别
深度学习必须是自然语言处理以及计算机视觉
图像数据+文本数据 + 人脸识别
卡帧 医学深度学习应用很广 神经网络自动重构
李飞飞 imageNet 计算机的效果远超人类
数据规模 必须要几万几十万才需要深度学习
1万人脸 数值数据
图像分类
计算机视觉: 图像分类任务 图像在矩阵中就是一些点
0-255 weightheight颜色通道
整体思路都是跟机器学习差不多
CIFAR-10
K近邻 部分结果还是不错的 但是有的分类效果还是不行
无法确定什么是主体 什么是背景 深度学习可以自学习
不能做图像分类 无法自圆其说
图像分类 计算像素乘积得分值
正值是一个促进的作用 负值是抑制的作用
数据预处理之后 数值不变 W矩阵可以变 W会对最后的结果产生影响 选择优化方法不断改进W参数
损失函数是衡量一个事情的结果的正确
模型不要太复杂 过拟合的模型是没用的
神经网络过于强大 越强大 过拟合的风险越大 神经网络需要变弱
Softmax分类器
我们得到一个输入的得分制 概率得分是
只关注正确类别的概率值 log不让他是负值
反向传播
神经网络正则化的处罚力度:
sigmod函数 所有的梯度的函数都可以计算
函数数值较大小 会因为梯度计算直接消失0
Relu函数 市面上90%都是这个 避免大树或者小数消失
Drop-Out消除 七伤拳 全连接 为了避免过拟合
随机选择一部分不使用 重复多次每次选择一部分进行杀死
卷积神经网络的应用
深度学习
CV运用计算机视觉 远远高于人眼
检测+追踪 现在计算机视觉论文 每一年都在进行提升
只要跟图片相关 无人驾驶 也是卷积神经网络 CPUGPU
图像处理单元 lps 连接不连贯 应用实际项目就必须使用GPU
人脸重构 怎么养提取特征
卷积的作用
CNN输入原始的图像 卷积神经网络 hwc
卷积神经网络:整体架构:
输入层 卷积层 池化层 全连接层
对不同的区域 提取不同的特征
步长影响特征
边缘填充
Pad1 边缘填充 有些点对计算结果天生就有优势 边界点被利用的次数就是比较少
池化的作用
压缩 下采样
卷积神经网络的结构
两次卷积 一次池化压缩 拉长操作 是把特征值拉长
一次卷积 特征值个数明显变多
Alexnet Vgg
训练时间 以天为单位
Resnet
训练自己的数据集流程
每个都是1000个数据 必须做到3000个数据
keras实战:
TensorFlow 复杂API变简单 便捷 keras就是一个安装包
相应tensorflow也可以一起安装
flatten拉成一维的
需要验证集 序列网络 直接添加

神经网络影响最大的就是学习率
加载模型进行预测
拉平操作 变成1
卷积模型
VGG RESNET 框架都是有现成的 直接使用就可以了 不需要改进
网络结构 参数学不需要自己调
所有的参数一点点试验 直接调用就可以了
如何让模型的泛化效果更平和一些
卷积层:全连接层
CNN 边角 形状: 语义
卷积为什么能提取特征???
黑白图片是由像素点构成的 0 -255 卷积核就是 【-1,1】
从特征图 构成featureMap 从卷积核可以得到边界线
卷积核就是匹配特征 匹配到了之后就是100 不匹配就是0
卷积层直接把特征交给全连接层 全连接层的工作内容就是分类
https://transcranial.github.io/keras-js/#/mnist-cnn
数据决定上线 模型决定下限
CNN 卷积 只是迭代了简单的一部分 NN神经网络判断黑白图片就很好了
RNN 图像识别相关 时间序列 考虑前后时间关系
输入的是序列数据 dense 是全连接
v
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8TLEB6AM-1679538456281)(null)]


1.bias直接加入
2。激活 函数应该Relu归零
3,所以需要softmax一下
激活函数

- sigmod缺点:饱和梯度值非常小 网络层数较深容易出现梯度消失
- Relu缺点: 反向传播权重过大导致无法更新权重,失活(实际上运用比较多)有一个别称 叫做“濒死的Relu” 因为某些神经元实际上死亡了 停止输出0以外的任何值,如果你使用较大的学习率 当神经元的权重进行调整的时候,其输入的加权对于所有的训练集中的所有实例均为负数 所以需要leakyRelu
函数越界 可以直接使用padding补0进行计算
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bKNsSm6p-1679538452642)(null)]
慕课上 复旦大学赵卫东
池化层
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lMR2uq8d-1679538448271)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230221170144631.png )]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pTS1ywpB-1679538448271)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230221170236562.png )]
反向传播
误差的计算

为什么要使用softmax函数呢?需要让输出变成概率分布
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3jDGQ294-1679538448272)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230221170945329.png style=“zoom:67%;”)]
softmax函数是所有的概率和都是1针对的是猫狗问题
sigmod函数针对分类的是人和男人 二分类
误差的反向传播
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3KYepgkk-1679538448272)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230221172943962.png style=“zoom:67%;”)]

Q:损失梯度的方向是否指向了全局最优的方向?
权重的更新

SGD容易受到噪声影响 随机陷入局部最优解
Q:如何解决SGD容易陷入局部最优解这个问题呢?
可以有效抑制样本噪声的影响
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0EeSAf4r-1679538448272)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230222102023846.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-igKW2fwF-1679538453981)(null)]
在学习率上做手脚 学习率会要越来越小 所以这个叫做自适应学习率
Adagrad学习缺点:下降太快 有可能还没有收敛到最低点就停止训练
Q:怎么解决学习率下降太快这个问题呢?

这两个系数就是为了控制衰减系数的

代码地址
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JC1hrrOh-1679538455682)(null)]
pytorch



CNN网络雏形是LeNet pytorch的通道顺序是 batch,channel,height,width

Inchannnels 通道数 out_channels 代表卷机核的个数 kernel_size 代表卷积核的大小 stride代表的是布局
class LeNet(nn.Module):
def __init__(self):
# 初始化函数
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5) # 输入特征层的深度3 卷积核的个数16个 卷积核的大小5
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
Q:为什么最后没有使用softmax?
转化为概率分布 计算卷积交叉墒的过程 已经调用了softmax层了
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
def main():
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = next(val_data_iter)
# classes = ('plane', 'car', 'bird', 'cat',
# 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
with torch.no_grad():
outputs = net(val_image) # [batch, 10]
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()


这里是为什么定义的网络不需要使用softmax作为概率分布的最后一层的原因
Q:为什么需要zero_grad()


AlexNet

亮点:1.GPU 2.RELU 3.LRN局部响应归一化 4。DROPout 减少过拟合
卷积神经网络第一个提出来是有李春提出来的 GPU是CPU20倍
dropout会随机失活一定的神经元

AlexLet使用了两块gpu
总结:这节课讲了AlexLet的网络结构以及数据集 下节课使用pytorch和tensorflow搭建Alexnet
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
#
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
#dropout一般放在全联接层与全联接层之间
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
# 输出是变量集类别的个数 默认=1000 因为本数据集只有5个分类 所以使用时直接穿入5即可
)
if init_weights:
self._initialize_weights()
#如果初始化权重设置为true的话 那么就会初始化权重 其实在这里并不需要初始化 pytorch自动使用凯明初始化的
def forward(self, x):
x = self.features(x)
# 直接调用网络中一系列操作
x = torch.flatten(x, start_dim=1)
# 进行网络中的展平处理
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
#返回一个可以便利所有层结构的迭代器
if isinstance(m, nn.Conv2d):
#判断当前层是否是卷积层
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
#使用这个函数 凯明初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
# 正态分布 初始化 bias=0
nn.init.constant_(m.bias, 0)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oRTufxkW-1679538448274)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230227104500771.png)]

应对s的上下左右都不相同的时候需要使用nn.ZreoPad2d方法 更精细化的操作
padding假如最后使得输出层的层数输出位小数,那么pytorch里面会自动舍去最右侧和最下面的padding补全的0
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
# 随机裁剪 将图片裁剪成224 * 224
transforms.RandomHorizontalFlip(),
# 在水瓶方向随机反转
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
# 进行标准化处理
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path 获取数据集的根目录
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
# 加上数据的训练集路径 transform是数据预处理的工具 字典
train_num = len(train_dataset) # 确定训练集有多少图片
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
# 将class这个类别转换成json格式
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# 把这个文件保存class_indices.json 这个json文件中可以直接使用
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
# 加载数据所使用的线程个数 windows只能使用0
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
# 加载测试集的图片
val_num = len(validate_dataset)
# 统计测试集的文件个数
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=4, shuffle=False,
num_workers=nw)
# 通过dataLoader载入测试集
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
#
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
# imshow(utils.make_grid(test_image))
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
# 将网络制定的gpu上
loss_function = nn.CrossEntropyLoss()
# 多类别的损失交叉墒
# pata = list(net.parameters())
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 10
save_path = './AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
# 通过net.train和net.eval来实现管理是否使用dropout方法 后面还会使用到batchnormalization
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()


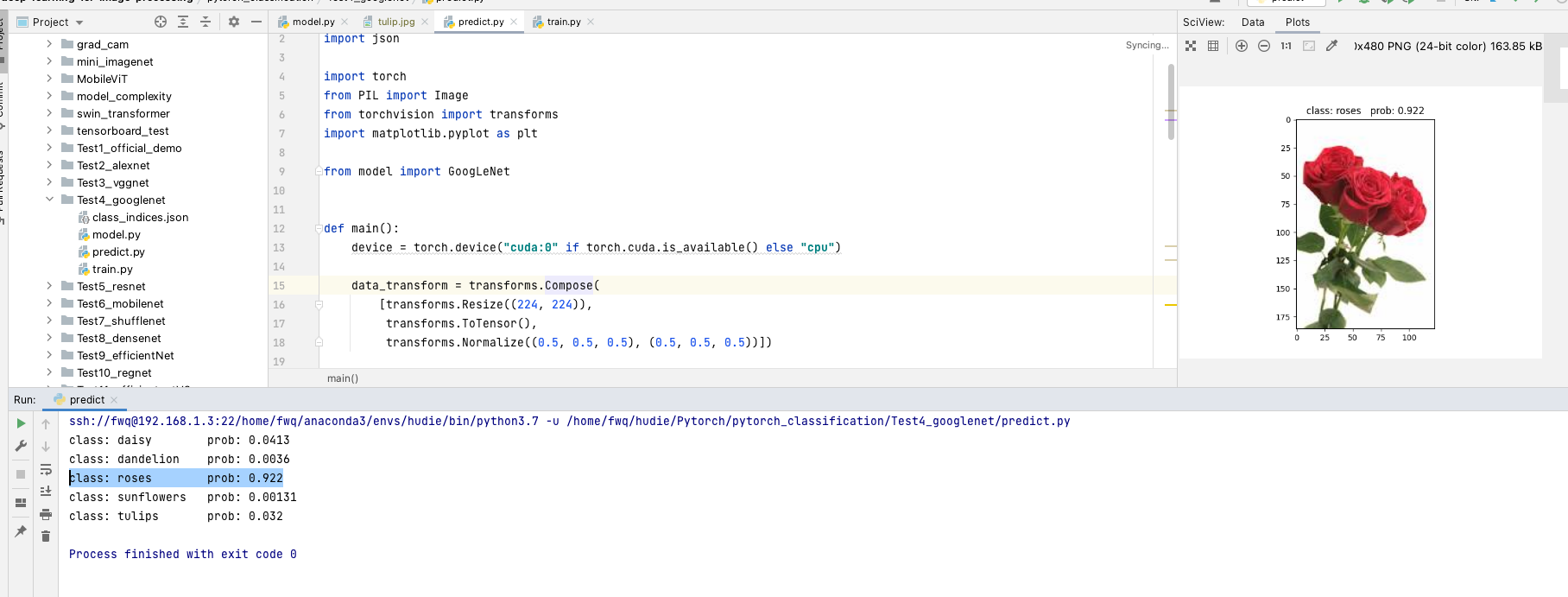
运行predict之后的结果:

- 运行结果是郁金香 但是原图片是玫瑰
VGG网络
VGG网络亮点; 通过堆叠多个3*3 的卷机核来滴爱大尺度卷积核(减少所需参数)

Q: 什么是感受野?
在卷机神经网络中 举鼎某一层输出结果中一个元素所对应的输入层的区域大小 被称作感受野

通过堆叠两个33 的卷积核替代55 的卷积核, 堆叠3个 3 * 3 的就可以替代 7 * 7 的

网络结构
网络代码结构
import torch.nn as nn
import torch
# official pretrain weights
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
# 通过非关键字的形势传入 直接序列化使用创建模型参数 *可以传入不定长的参数
# 通过这个函数 可以提取特征网络结构
cfgs = {
# 对应的是一个列表 卷积核的一个个数 M 对应的是池化层的结构 网络配置信息
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
return model
训练截图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m7MsNyXu-1679538456264)(null)]

GoogleNet
googleNet 在2014年提出 斩获当年ImageNet竞赛中分类任务的第一名
网络亮点:
- 引入了Inception结构(融入不同尺度的特征信息)
- 使用1*1的卷积核进行降维以及映射处理(VGG也用了 但是googleNet给出了更详细的介绍)
- 添加了两个辅助分类器帮助训练
- 丢弃全联接层,使用平均池化层(大大减少模型参数)
AlexNet和VGG都只有一个输出层 但是GoogleNet有三个输出层(其中两个辅助分类层)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ltm9YouV-1679538448276)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230303093133864.png)]
- AlexNet和VGG网络都是串行结构
- 但是GoogleNet的创新点在于它是并行结构
Q: 1*1的卷积核是如何起到降维的功能呢?
A:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nJZFJAQg-1679538448276)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230303093636043.png)]
这就是为什么需要1*1的卷积核进行降维处理

Q:为什么需要辅助分类器呢?
A:因为网络层数太深误差反反向播后原本在前面的网络层很难调节 最后softmax不能调节地层的参数了 辅助分类器防止反向传播梯度消失
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4kz8jBAE-1679538452589)(null)]
Q:GoogleNet相较于VGGNet 优化在哪里
A: 
Q: 为什么GoogleNet这么好 但是现在网络上大规模使用的还是VGGNet呢?
A:1.VGGNet搭建比较方便 2。有两个 辅助分类器,对于网络的修改和训练比较的麻烦
GoogleNet网络实现训练结果:

预测结果:
比VGGNet的表现结果要好得多
ResNet
在ResNet网络提出之前,传统的卷积神经网络都是通过将一系列卷积层与池化层进行堆叠得到的。
一般我们会觉得网络越深,特征信息越丰富,模型效果应该越好。但是实验证明,当网络堆叠到一定深度时,会出现两个问题 梯度消失或爆炸问题、退化问题
网络亮点
- 超深的网络结构
- 提出了残差模块
- 提出了Batch Normalization加速训练(丢弃dropout)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oAIgpC7h-1679538452621)(null)]
Q:ResNet的层数可以超过1000层 我直接尽心简单的堆叠不就可以了么?
A:简单的堆叠会导致梯度消失或爆炸问题 还会导致退化问题(层数越多 表现不一定越好) 简单的堆叠并不是层数越多效果越好
通过残差解决退化问题 虚线是训练集错误率 实线是验证集错误率
为了解决深层网络中的退化问题,可以人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为 残差网络 (ResNets)。
残差网络由许多隔层相连的神经元子模块组成,我们称之为 残差块 Residual block。单个残差块的结构如下图所示:
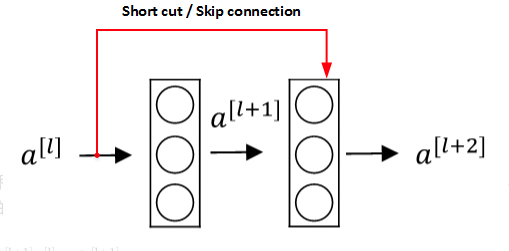
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-glpn7Vs7-1679538448278)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230307091002376.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vn68ANCA-1679538448278)(…/Library/Application%20Support/typora-user-images/image-20230307091753636.png)]
这部分讲解为什么残差结构有实线和虚线呢? 实线是因为对应的输入输出结构是一致的 但是虚线部分对应的是不一致的 所以需要stride步距为2 卷积核个数的变化来变化
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ptHnA31v-1679538452782)(null)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ufyX0TVn-1679538448279)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230307095713356.png)]
Batch Normalization详解

https://blog.csdn.net/qq_37541097/article/details/104434557 博客详解
通过该方法能够加速网络的收敛并提升准确率。
BN原理
我们在图像预处理过程中通常会对图像进行标准化处理,这样能够加速网络的收敛,

最后一步yi的值变化是因为 有的人认为(0,1)标准正态分布在训练上的效果并不一定是最好的 所以构建反向传播过程中 可以获取γ和β值来对预测值进行放缩
迁移学习

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y7pCtDQi-1679538452609)(null)]
Q: 为什么可以实现迁移
A:在浅层的网络中 这些角点信息 纹理信息是对于大多数网络是通用的 所以这些识别到的信息也是可以直接运用到其他的网络上的 将已经学习好的浅层的网络参数直接迁移到新的网络 新的网络就可以拥有识别底层通用特征的能力 这样新的网络就可以更加快速识别新的数据集的特征

ResNeXt
网络亮点:更新了block
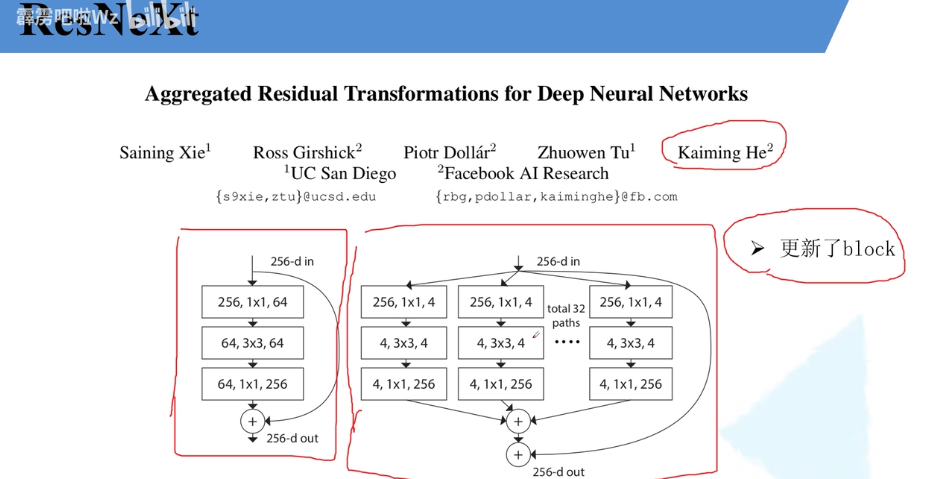
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vAV4BmRk-1679538452725)(null)]
详解block
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a3c3nRiC-1679538448280)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230307195358559.png )]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IAdZMHbo-1679538452746)(null)]

这种是两种方式的等价
ResNet训练结果
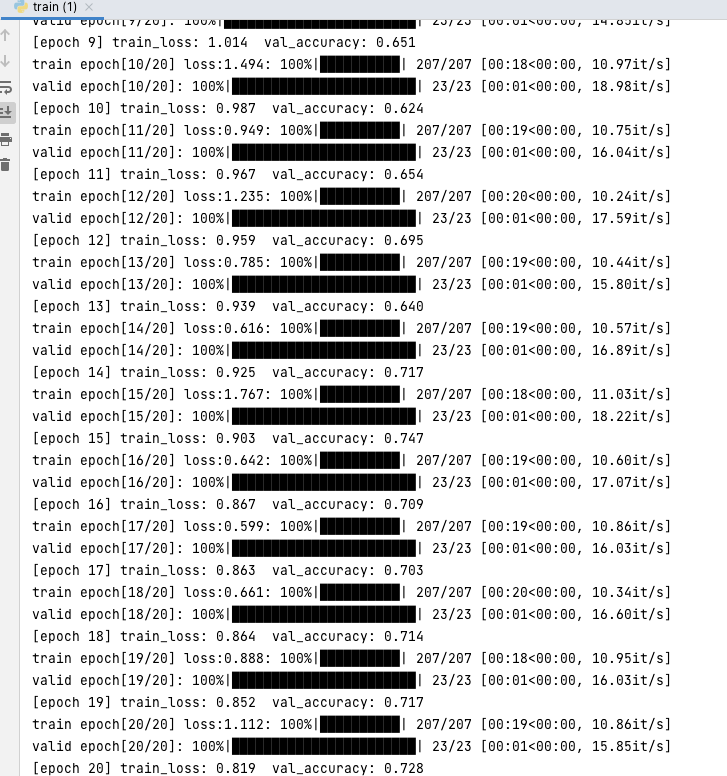
ResNet的训练正确率大概在90%
改完ResNetXt之后的训练结果
未见明显提升 可能数据集再大一点吧
ResNetXt预测结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iflfXO0M-1679538452763)(null)]
其中分类为玫瑰的正确概率为98.7%
使用批量检测

这个使用批量为8的检测 所以<8的话 剩余的图片就不展示 分类的图片因为训练的时候使用了 分类正确的概率甚至100%
第2次训练
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3kmWYinZ-1679538453885)(null)]
MobileNet
卷积神经网络CNN已经普遍应用在计算机视觉领域,并且已经取得了不错的效果,图1为近年来CNN在ImageNet竞赛的表现,可以看到为了追求分类准确度,模型深度越来越深,模型复杂度也越来越高,如深度残差网络(ResNet)其层数已经多达152层
在某些真实的应用场景如移动或者嵌入式设备,如此大而复杂的模型时难以被应用的。首先是模型过于庞大,面临着内存不足的问题,其次这些场景要求低延迟,或者说响应速度要快,想象一下自动驾驶汽车的行人检测系统如果速度很慢会发生什么可怕的事情。所以,研究小而高效的CNN模型在这些场景至关重要,至少目前是这样,尽管未来硬件也会越来越快。
目前的研究总结来看分为两个方向:
- 一是对训练好的复杂模型进行压缩得到小模型;
- 二是直接设计小模型并进行训练。
不管如何,其目标在保持模型性能(accuracy)的前提下降低模型大小(parameters size),同时提升模型速度(speed, low latency)。本文的主角MobileNet属于后者,其是Google最近提出的一种小巧而高效的CNN模型,其在accuracy和latency之间做了折中。
传统卷积神经网络 内存需求大 运算量大 导致无法在移动设备以及嵌入式设备上运行
我们的研究本身就是为了服务社会




[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sr91MDLp-1679538452564)(null)]
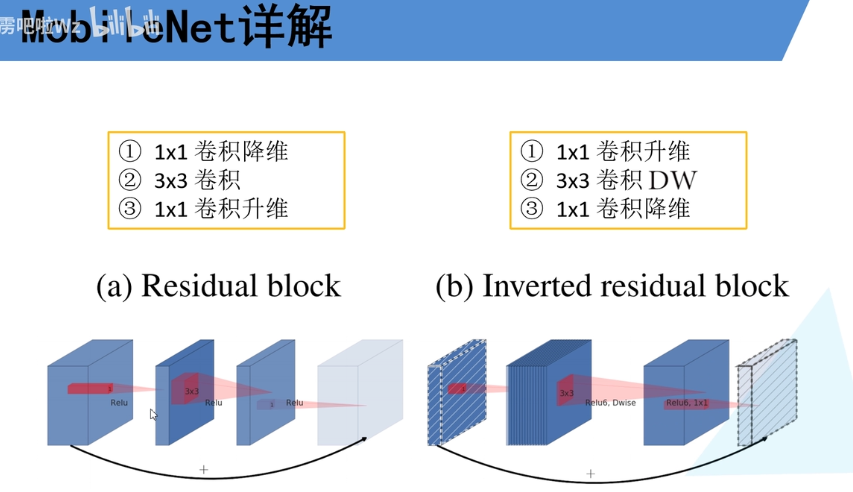



MobileNetV3




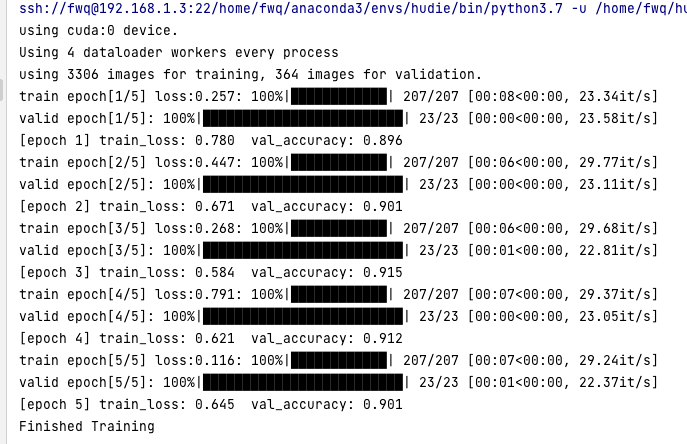
5轮MobileNetV2下来:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-umm7F4C7-1679538452525)(null)]
正确率达到89.6%
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cfnhRroj-1679538455078)(null)]
预测玫瑰的正确率达到75.7%
MobileNetV3训练结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-486SjEU3-1679538448285)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230317114155325.png)]

运行过程没有示例的结果高 正确率92.3% 但是相较于V2正确率得到了大大的提升 就网络表现来说ResNet的正确率要高的多