什么是scrapy ?
1 Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛
2 Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯
3 Scrapy非常的灵活 ,我们可以自己修改一些参数,或者是自己写代码丰富,非常的方便这张图片是scrapy的流程图,开始看可能感觉 什么鬼,但是了解它的工作方式后,并不是那么的难以理解。

Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
Scrapy的安装
关于 Windows 和 linux 的安装 可以根据自己的操作系统进行安装,搜索一下其他安装博客,很多。我这就跳过
新建项目的简介 (linux操作系统为例)
当我们安装好scrapy 时候,我们可以通过命令快速的创建一个爬虫项目
scrapy startproject Spider_name >>>> (Spider_name为你的爬虫项目名称,可根据自己项目要求取名)
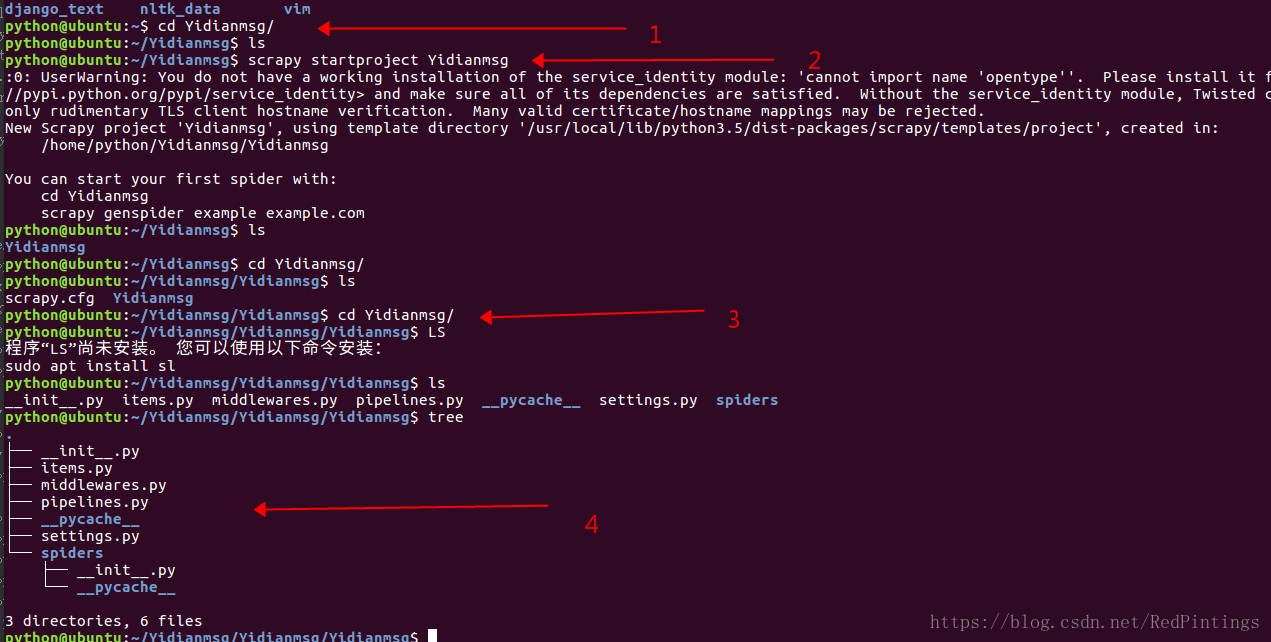
第一步 新建一个文件夹
第二步 我们通过命令新建一个爬虫项目
第三步 我们cd 到这个项目中去
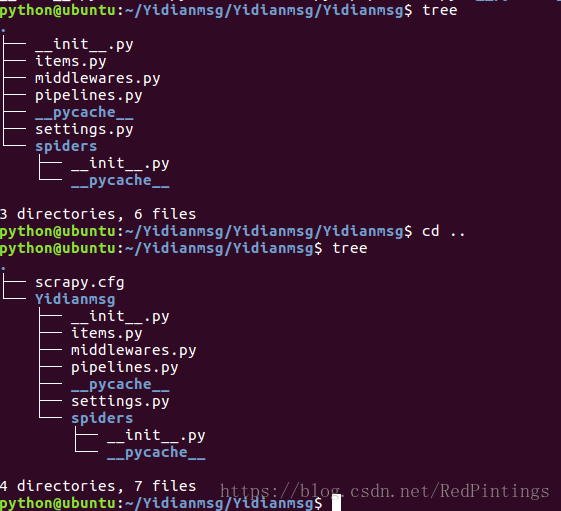
第四步 我们tree一下看看项目的目录结构
发现这个架构的起始文件就这么几个,他们的具体是做什么用的:
scrapy.cfg :项目的配置文件 可以挂载项目到服务器
Yidianmsg/ :项目的Python模块
items.py :项目的目标文件 这里主要是定义我们要抓取的字段
pipelines.py :项目的管道文件 这里主要是文件的存储,以及其他的一些处理
settings.py :项目的设置文件 这里是项目的一些配置文件
spiders/ :存储爬虫代码目录 这里使我们写爬虫代码的地方,
项目新建完成了,但是spider目录里面是空的,我们怎么快速的创建一个爬虫,这里scrapy也提供了快捷键
当然了,也可以自己写,但是我更喜欢用命令直接创建,方便快捷,何乐不为。
scrapy有两个爬虫类 他们的创建方式不同
scrapy genspider spider_name xx.com # spider_name 是你爬虫名字,xx.com 允许爬虫爬取的域名
scrapy genspider -t crawl spider_name xxxx.com # 名称 和域名范围 快速创建命令
我们这里只说第一个spider类,也就是第一条命令,关于第二条命令 crawlspider有兴趣的课去查下,它的爬取速度更快,行为更为粗暴
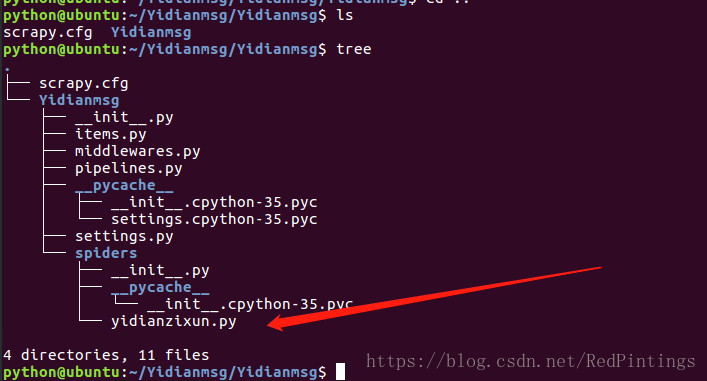
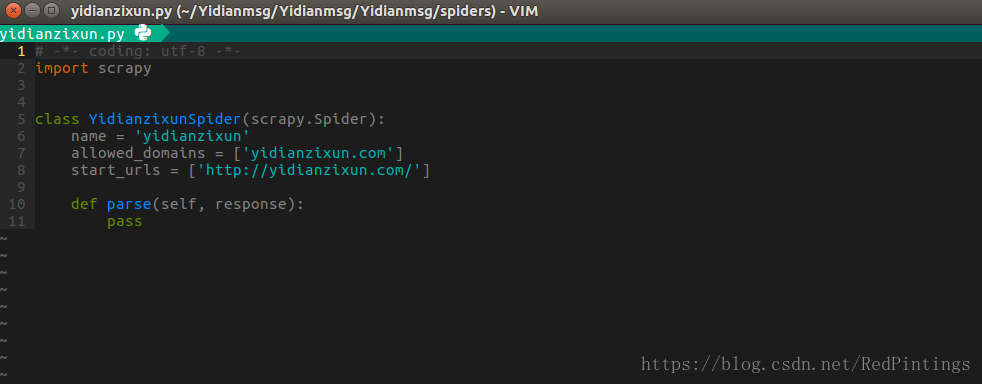
项目和爬虫都建立完毕后我们会发现,spiders文件下多了一个爬虫文件,这是我们写爬虫的地方 名字为 yidianzixun.py
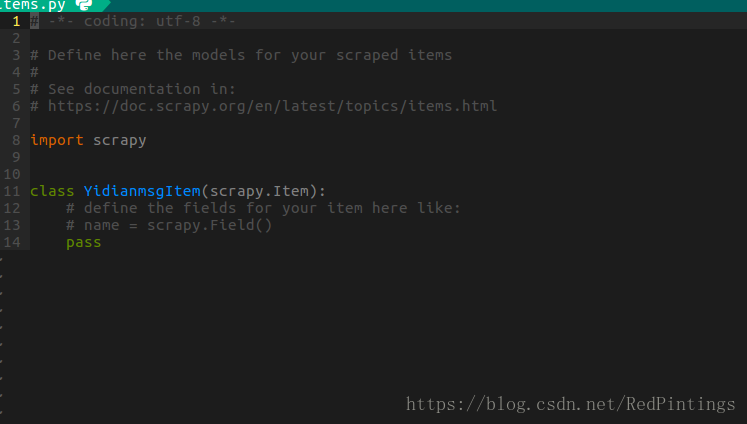
items.py 可以定义我们的爬取字段
pipelines.py 文件存储路径
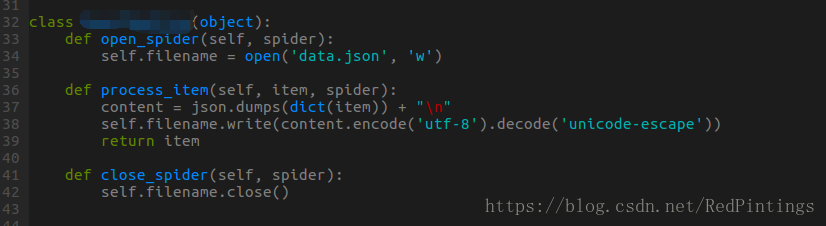
import something
class SomethingPipeline(object):
def __init__(self):
# 可选实现,做参数初始化等
# doing something
def process_item(self, item, spider):
# item (Item 对象) – 被爬取的item
# spider (Spider 对象) – 爬取该item的spider
# 这个方法必须实现,每个item pipeline组件都需要调用该方法,
# 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
# spider (Spider 对象) – 被开启的spider
# 可选实现,当spider被开启时,这个方法被调用。
def close_spider(self, spider):
# spider (Spider 对象) – 被关闭的spider
# 可选实现,当spider被关闭时,这个方法被调用spider
文件里面的 .py文件是写爬虫的文件,name是爬虫的名称,allowed_domains允许的爬取域名,start_urls是起始url
里面的parse方法 是第一个回调函数(注意用crawlspider不能使用parse方法,源码中已经实现parse方法,重写会覆盖)
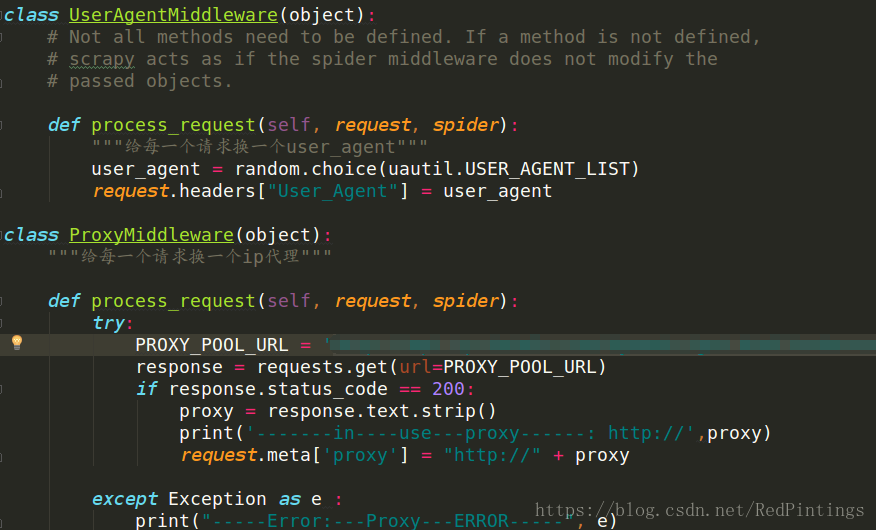
middlewares.py
这里是书写中间件的地方,这里的作用是下载器和引擎中间的钩子。在settings.py开启后我们发送的请求会经过这里,我们可以做一些处理,比如可以在这里加ip代理,user-agent等 可以参考以下图中实例
settings.py 常用设置
自上往下 【 user_agent ,自行设置】【是否遵守robots协议】【请求并发量,默认为16,可根据带宽自行调解】
【下载延迟,防止爬虫被网站屏蔽】【cookie】【添加默认的头部信息】【启用中间件】【启用pipeline】

下边我们以一点资讯为例 带来一个scrpy 爬虫实例
注:(代码仅作参考,有一些引用自写工具类却没有贴出来)
items.py
import scrapy
class YidianspiderItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
channel = scrapy.Field()
title = scrapy.Field()
item_type = scrapy.Field()
create_type = scrapy.Field()
original_url = scrapy.Field()
body = scrapy.Field()
images = scrapy.Field()
spider
# -*- coding: utf-8 -*- # @Time : 18-5-23 下午2:10 # @Author : 杨星星 # @Email : [email protected] # @File : YidianSpider # @Software: PyCharm import logging import scrapy import re from YidianSpider.items import YidianspiderItem from YidianSpider.MyUtils import Util class YidianSpider(scrapy.Spider): name = 'yidian' allowed_domains = ['yidianzixun.com'] start_urls = ['http://yidianzixun.com/'] child_channel_dicts = {"育儿":['t10449','e212806','t9651','u7916','u9392','u7934','e1595662','u7744','e268214','t19398','u7682','t10447','u7699']} emotion_channel_dicts = {"情感":['u141','u9384','u575','u9387','u338','e2654','e288452','e929007','e158508','t9436','u655']} headers = { "User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1", "Referer": "http://www.yidianzixun.com/", } def parse(self,response): for channel, ids in self.child_channel_dicts.items(): for id in ids: print('---id----', id) url = "http://www.yidianzixun.com/channel/" + str(id) yield scrapy.Request(url=url, callback=self.parse_page_links,headers=self.headers, meta={"channel": channel}) for channel, ids in self.emotion_channel_dicts.items(): for id in ids: print('---id----', id) url = "http://www.yidianzixun.com/channel/" + str(id) yield scrapy.Request(url=url, callback=self.parse_page_links,headers=self.headers, meta={"channel": channel}) def parse_page_links(self,response): channel = response.meta['channel'] # print(channel) # url = response.url response_html = response.body.decode('utf-8') article_links = re.findall(r'href="(.*?)"',response_html) for article_link in article_links: if 'article' in article_link: article_url = "http://www.yidianzixun.com" + str(article_link) print('--flag1---url----',article_url) yield scrapy.Request(url=article_url,callback=self.parse_article_detail,meta={"channel": channel},headers=self.headers) else: continue def parse_article_detail(self,response): channel = response.meta['channel'] item = YidianspiderItem() # class="doc-source">福建吃喝玩乐</ <div class="source imedia">福建吃喝玩乐</div>< name = re.findall(r'<div class="source imedia">(.*?)</div>', response.body.decode('utf-8'))[0] title = re.findall(r'<h3>(.*?)</h3>', response.body.decode('utf-8'))[0] OriginalBody = re.findall(r'<body>(.*?)</body>', response.body.decode('utf-8'))[0] NeedRepImageUrls = re.findall(r'"url":"(.*?)"', re.findall(r'"images":\[(.*?)\]', response.body.decode('utf-8'))[0]) BodyFlags = re.findall(r'<div id="article-img-\d+"class="a-image" .*?></div>', response.body.decode('utf-8')) if '.mp4' in OriginalBody: print('>>>-----视频资源----PASS----') return else: rep_body = OriginalBody for flag, image in zip(BodyFlags, NeedRepImageUrls): rep_body = rep_body.replace(flag, '<img src="http:' + image + '">') RemoveBodyId = re.sub(r'id=".*?"', '', rep_body) RemoveBodyClass = re.sub(r'class=".*?"', '', RemoveBodyId) ImageUrl = re.findall(r'src="(.*?)"', RemoveBodyClass) item['image_urls'] = ImageUrl try: tag = Util.get_tags_by_jieba(RemoveBodyClass) if tag: tag.append(channel) item['tag'] = tag except Exception as error: logging.info(error,'-----tag--error-----') return if title: item['title'] = title else: return try: Temp_Content = RemoveBodyClass for content_img_url in ImageUrl: content_url_temp = Util.generate_pic_time_yidian_lazy(content_img_url) Temp_Content = Temp_Content.replace(content_img_url, content_url_temp) item['body'] = Temp_Content except Exception as e: print(e) logging.info('-------------BODY---ERROR---------------') return try: item['images'] = [] data_echo_url = re.findall(r'data-echo="(.*?)"', item['body']) for num, image_url in enumerate(data_echo_url): temp_image_url = Util.generate_pic_time_yd(image_url) + '.jpg' image_dict = {"index": num, "url": temp_image_url, "title": ""} item['images'].append(image_dict) except Exception as e: print('-----ERROR----', e, '--IMAGES---ERROR----') logging.info('-------------IMAGES---ERROR---------------') return item['channel'] = channel item['source'] = '一点号' if name: item['name'] = name else: item['name'] = '一点号' item['original_url'] = response.url if not item['body']: return if len(item['body']) < 200: return CheckItem = Util.check_item(item) print('----------',CheckItem ,'------------') if CheckItem == 1: return yield item
pipeline.py
import json
class NewsPipeline(object):
def open_spider(self, spider):
self.filename = open('data.json', 'w')
def process_item(self, item, spider):
content = json.dumps(dict(item)) + "\n"
self.filename.write(content.encode('utf-8').decode('unicode-escape'))
return item
def close_spider(self, spider):
self.filename.close()
settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for YidianSpider project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'YidianSpider'
SPIDER_MODULES = ['YidianSpider.spiders']
NEWSPIDER_MODULE = 'YidianSpider.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 16
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 2
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'YidianSpider.middlewares.YidianspiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'YidianSpider.middlewares.YidianspiderDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'YidianSpider.pipelines.YidianspiderPipeline': 300,
}