原始的爬虫流程:效率低、同步、阻塞
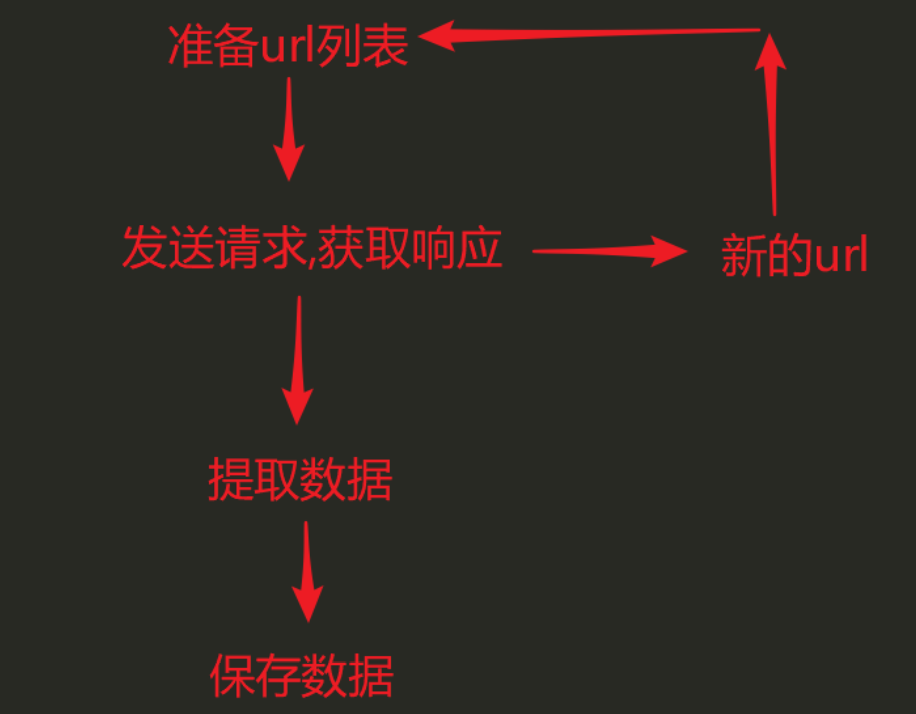
scrapy执行流程:效率高、异步、非阻塞

scrapy的概念
scrapy是一个爬虫框架
开发速度快
稳定性高
性能优越
scrapy的流程
1. 爬虫模块(Spiders) --> 准备起始URL(Request) --> 爬虫中间件 --> 引擎 --> 调度器(Scheduler):请求去重, 缓存请求(队列)
2. 调度器 --> 请求(Request) --> 引擎 --> 下载器中间件 --> 下载器:发送请求, 获取响应, 把响应封装为Response对象
3. 下载器 -Response --> 下载器中间件 --> 引擎 --> 爬虫中间件 --> 爬虫模块:解析响应数据, 提取数据, 提取请求
4. 爬虫模块 --> 数据 --> 引擎 --> 管道(Pipeline):保存数据
5. 爬虫模块 --> 请求 --> 爬虫中间件 --> 引擎 --> 调度器.
scrapy各个组件作用
引擎模块:调度各个模块, 以及模块间数据传递.
调度器模块:请求去重, 缓存请求(队列)
下载器: 发送请求, 获取响应数据
爬虫模块:解析响应数据, 提取数据, 提取请求
管道模块:处理数据, 比如:保存数据
下载器中间件: 在引擎和下载器之间, 把请求交给下载器之前, 可以对请求进行处理, 比如设置代理, 设置随机请求头.
爬虫中间件: 在引擎和爬虫之间, 可以请求和响应数据进行过滤.
ScrapyShell
使用格式:scrapy shell URL
作用:
可以用于测试response常见属性和方法
可用于用于测试/调试XPATH
response中重要属性:
response.body:响应的二进制数据
response.text: 响应的文本字符串数据
response.url: 响应的URL
response.request.headers: 响应对应的请求的请求头
settings.py中的设置信息
ROBOTSTXT_OBEY 是否遵守robots协议,默认是遵守
DOWNLOAD_DELAY 下载延迟,默认0.5~1.5的随机延迟
COOKIES_ENABLED 是否开启cookie,即每次请求带上前一次的cookie,默认是开启的
DEFAULT_REQUEST_HEADERS 设置默认请求头
DOWNLOADER_MIDDLEWARES 下载中间件
LOG_LEVEL 控制日志输出的级别
日志等级: DEBUG,INFO,WARNING,ERROR,CRITICAL
LOG_FILE 设置log日志文件的保存路径, 如果设置该参数,终端将不再显示日志信息
回调函数之间数据的传递
yield scrapy.Requst(url,[callback,method,headers,body,cookies,meta,dont_filter])
callback:表示当前的url的响应交给哪个函数去处理
meta:实现数据在不同的解析函数中传递,设置代理IP
meta={'xx':yy}:在callback函数中使用response.meta['xx']获取传递过来的yy的数据
dont_filter:默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为True
method:指定POST或GET请求
headers:接收一个字典,其中不包括cookies
cookies:接收一个字典,专门放置cookies
body:接收字符串格式:name=aa&age=bb