本文转载自:https://blog.csdn.net/u013710265/article/details/72798348
分布式文件系统
一、分布式系统概念
(1)分布式系统类型:
Client/Server、P2P(Peer-to-Peer)、Master/Worker
(2)故障模型(Failure Model):
Fail stop:出现故障时,进程停止/崩溃
Fail slow:出现故障时,运行速度变得很慢
Byzantine failure:包含恶意攻击
(3)
CAP定理:三者不可得兼
Consistency:多份数据一致性
Availability:可用性
Partition tolerance:容忍网络断开
二、分布式文件系统
(1)本地文件系统(Local File System):
Linux ext4、Windows ntfs、Mac OS hfs……
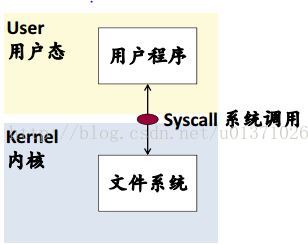
(2)NFS(Sun’s Network File System):
定义了开放的client/server之间的通信协议标准。
主要目的:从不同的终端都可以访问同一个目录;多用户共享数据;集中管理。
系统架构:
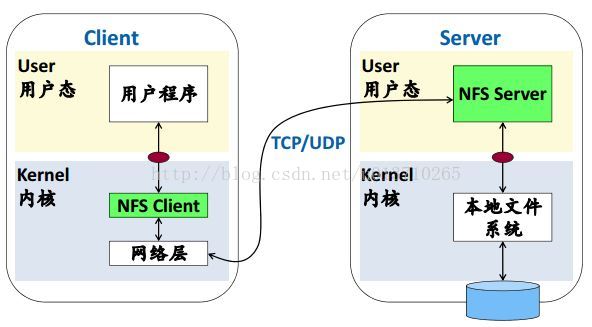
设计目标1:服务器出现故障,可以简单快速恢复(Fail-stop模型)。
实现过程1:
<1>Stateless:NFS Server不保持任何状态,每个操作都是无状态的。
<2>Idempotent:Read,Write操作时Idempotent(幂等性)。
设计目标2:远程文件操作性能高。
解决思路2:Client cache(在内存中),缓存读写的数据。存在问题,Cache Consistency。
对于Cache Consistency的解决办法:Flush-on-close(或close-to-open)consistency;文件关闭时,把缓存的已修改的文件数据,写回NFS Server。然后每次在使用缓存的数据前,必须检查是否过时。方法是用
GETATTR请求去poll(轮询),获得最新的文本属性;然后比较文件修改时间。
(3)AFS(Andrew File System):
设计目标:Scalability。即每一个服务器支持尽可能多的客户端,
解决NFS polling状态的问题。
解决polling状态的问题:Invalidation。当Client获得一个文件时,在server上登记;当server发现文件修改时,向已经登记的client发一个callback;当Client收到callback,则删除缓存的文件。
其他不同点:AFS VS NFS
AFS缓存整个文件;而NFS是以数据页为单位的。
AFS缓存在本地硬盘中,而NFS缓存是在内存中,所以AFS可以缓存大文件。
AFS有统一的名字空间,而NFS可以mount到任何地方。
三、Google File System和HDFS
HDFS为Google File System的开源实现。为
应用层的文件系统。
(1)
GFS设计目标:优化大块数据的顺序读;并行追加(append)。不支持文件修改操作。
(2)系统架构:

Name Node:存储文件的metadata(元数据)。文件名、长度、分成多少数据块,每个数据块分布在哪些Data Node上。
Data Node:存储数据块。
文件切分成定长的数据块(默认为64MB大小)。
每个数据块独立地分布存储在Data Node上。默认每个数据块存储3份,在3个不同的data node上。
(3)读写操作
HDFS/GFS读文件:打开文件(通过Name Node);读数据(通过Data Node,绕开Name Node)。
HDFS/GFS写文件:向Name Node请求写数据块,返回应该写的Data Node;发送数据块,Data Node在内存中缓存数据;发送写命令,收到写命令后才真正进行写操作,把缓存的数据写到文件系统中。
不支持并发写,支持并发Append!