这篇文章比预期来的要晚一点,第一遍接近完成时,脑子一热去清理了一下草稿箱,然后右手一抖就把它给删了,然后又不得不来第二遍。。。。这个时候分布式备份就显得尤为重要!!!
言归正传,本文对分布式文件系统的集群管理功能进行阐述,对其进行归纳和整理,认为分布式文件系统的集群管理功能需要做到以下几点:
- 维护系统的物理模型
- 维护系统的逻辑模型
- 维护逻辑模型到物理模型的映射
对于分布式系统为了提高容错性,我们常常会将物理存储介质做划分和隔离,以磁盘作为最小存储单位,构成一个存储服务器,再由多台服务器构成一个机架,我们把这些关系抽象成模型就可描述为分布式文件系统的物理模型。这样的划分和隔离,可以增加系统的可靠性,同时也可以简化运维操作。
对于分布式文件系统而言,解决的主要问题是从文件到最终存储介质的映射关系。这一过程我们可称做为是数据定位,数据定位的过程可以理解为是数据流,而本文要说道的集群管理属于管理流,为了能让数据流能正常流通,集群管理必不可缺。如下图1所示即为分布式文件系统集群管理功能需要完成的工作,本文主要围绕下图展开。
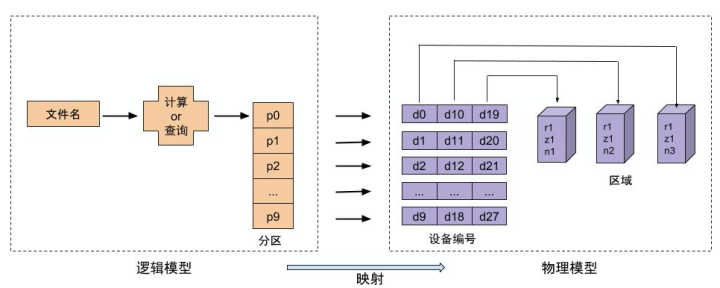
图1
1. 模型的定义
1.1 物理模型
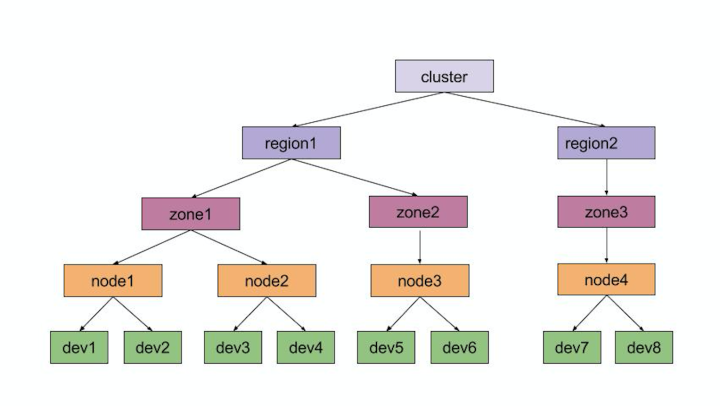
在分布式文件系统中,存储介质从磁盘、机器、机架到机房,从模型的角度来看它们的从属关系如下:
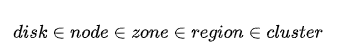

采用树形结构来表示更为直观,如下图所示
图二
- dev: 物理服务器上的一块磁盘,我们看做分布式文件系统的最小物理存储单位,所说的存储节点多也以一块磁盘作为最小管理单位。
- node: 物理服务器,磁盘的集合。
- zone: 物理服务器的集合,引入zone可增加数据的可靠性,我们将数据的不同副本位于不同的域,在物理位置上隔离,可减少数据丢失的可能性。
- region: 更高级别的集合,理解为地区,可对数据进行异地灾备等。
1.2 逻辑模型
分布式文件系统中,文件的存储也会以集合的形式存储,即文件目录称作分区,每个分区有唯一的ID即PartitionID。而逻辑模型定义的就是文件ID到PartitionID的映射关系,客户端通过这个逻辑模型可以进行文件位置的第一步定位,找到文件目录号。
![]()
1.3 逻辑模型到物理模型的映射
分布式文件系统中,逻辑模型到物理模型的映射完成文件的第二步定位,找到文件的物理存储位置。从逻辑模型到物理模型的映射如下表示,根据DocID查找其所属的PartitionID,以存储三副本为例,每个Partition会同时存储三份到不同的磁盘上,所以PartitionID到存储磁盘的映射一对多的关系。
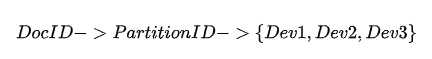
2. 模型的实现
梳理好分布式文件系统的模型,然后对于有中心管理节点和无中心管理节点的系统对于模型的实现进行分别描述。
案例一 有中心管理节点
维护系统物理模型
对于有中心管理节点,最直接简单的方式就是用数据库实现物理模型,为了提高中心节点的性能,减少数据库的频繁读操作,常常会使用内存缓存模型及数据,由后台线程定期维护内存模型数据和数据库持久化数据保持一致。
创建region,zone,node和dev等表结构,通过id将其关联起来,用于表示此物理模型。在系统初始化时模型建立后,引起模型状态变化的操作主要有两类,一种是人工运维操作,如增加、删除dev或节点等常规操作;另外一种是自动运维,即监测节点或者磁盘的状态,一旦发现节点异常,自动将其移出系统。所以中心管理节点需要实现以下功能:
管理工具模块,给管理员提供模型中的变量region、zone、node及dev的增删改操作,本质也就变成了数据库的增删改查的操作。
集群状态监测模块,中心管理节点通过Zookeeper很容易实现此功能。在中心管理节点启动时在Zookeeper目录下创建MasterNode节点,DataNode管理一个磁盘设备,它在上线时会将自己注册在子节点目录下,MasterNode后台线程监听ZooKeeper目录变化,获取和更新当前集群节点的状态(上下线事件)和信息,保证系统模型状态的正确性
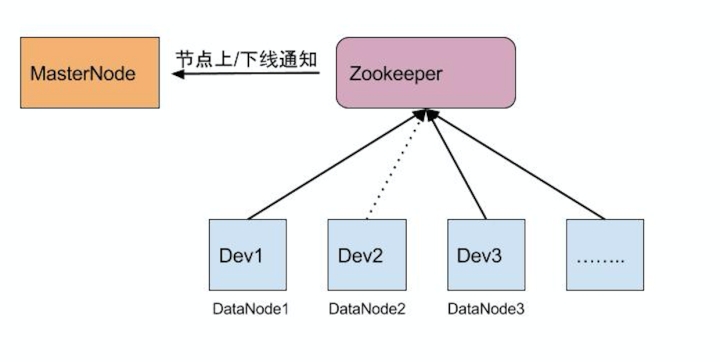
图3
维护系统逻辑模型
DocID到PartitionID的映射关系,如果都存于中心管理节点,那么会导致中心管理节点占用存储量增大,且每次读操作都需要查询中心节点,性能消耗较大。所以分布式文件系统的逻辑模型中的映射关系一般不会采用存储查询的方式,而是通过计算的方式实现。有个比较简单直接的办法就是将PartitionID信息包含在DocID中。在写操作时,系统分配一个全局唯一DocID,DocID中包含该文件所存储的Partition的信息,在读操作时,可直接通过DocID获取Partition的信息。这样中心管理节点只需存储Partition的信息,极大减少中心管理节点的存储占用量。
这里需要提到的一点是逻辑模型中Partition何时创建的问题,对于中心管理节点的系统一般不会采用静态的方式,即在系统初始化的时候就将所有Partition全部创建,而是在系统运行时根据系统当前的状态采用动态异步创建的方式,会更加灵活可控,这样做的好处时,Partition的数量可以随着物理存储磁盘的增加无限扩展增加,也减少了因为物理模型的改变导致Partition数据会频繁迁移。
维护逻辑模型到物理模型的映射
对于中心管理节点,解决逻辑模型到物理模型的映射关系很简单,在Partition表中增加一个字段存储三备份存储的磁盘ID即可。但由于物理模型状态会受到人工操作或者节点状态变化而改变,所以中心管理节点需要维护逻辑模型到物理模型的映射关系动态变化,才能维护系统的高可靠和高可用特性。
中心管理节点在给Partition分配设备需要根据系统运行时物理模型当时的状态,根据一定的策略和原则来进行分配:
- 尽量将三个Partition副本放在不同的region、zone、node上,提高数据的可靠性
- 根据dev设置的权重来选择,一般根据Dev的容量权重来进行Partition副本的选择,尽可能让有存储能力强的dev分配到更多的Partition
除了维护Partition到Dev的映射关系,中心管理节点还有个重要的作用就是选主,本质上就是解决模型中{dev1,dev2,dev3}的主从关系,当三备份中主节点dev1发生故障时,为了保证数据的一致性,中心管理节点将该Partition变为只读,客户端重试写入Partition保证可用性。由于主从节点采用的是强一致性协议,所以中心管理节点选择其中从节点作为主即可。在后面的异常处理章节,对各种异常情况系统如何处理展开细述。
案例二 无中心管理节点
对于无中心管理节点来说,也需要有一个数据结构来存储上述的模型关系,不同的是存储的方式不是采用集中存储的形式,而是集群中的各个节点都需要保存这么一个模型结构。下面也从以下几点,以Swift为例说明,其核心结构Ring实现了以上的模型定义及维护。
Ring实现了集群管理的功能,但它承担的责任远不仅此,作为Swift系统的灵魂,对数据定位以及部分数据复制等功能都起到了至关重要的作用。Ring的原理和实现对于学习分布式文件系统的同学来说,还是值得深入了解的,所以下篇会根据代码从多个维度分析Swift的Ring结构,本篇暂且只说到Ring在集群管理功能上的实现。
维护系统逻辑模型
Swift的Ring在一开始管理员创建时,完成了集群的逻辑模型的建立,如下管理员通过swift-ring-builder命令行工具,在Ring中创建了集群需要的所有Partition,Partition的数量为2的<part_power>次方个,备份为3备份,Partition被连续移动两次之间的最小时间间隔是<min_part_hour>。
swift-ring-builder <builder_file> create <part_power> <replicas><min_part_hours>
Swift的文件到PartitionID的映射关系采用的是计算的方式,计算文件名MD5的hash值,再取part_power位作为PartitionID。对于Ring的Partition数量是固定的,在Ring的初始化时part_power决定了集群可以有多少个partition,从而Swift集群最终可以有多少个物理节点也受此限制。
维护系统物理模型
Swift的Ring结构中Ring._devs列表用于存储系统所有存储设备的的信息,每一个存储设备包括如下的信息,这样整个系统从region到dev的物理模型也就定义好了
===============================================================
id unique integer identifier amongst devices
index offset into the primary node list for the partition
weight a float of the relative weight of this device as compared to
others; this indicates how many partitions the builder will try
to assign to this device
region -
zone integer indicating which zone the device is in; a given
partition will not be assigned to multiple devices within the
same zone
ip the ip address of the device
port the tcp port of the device
device the device's name on disk (sdb1, for example)
meta general use 'extra' field; for example: the online date, the
hardware description
replication_ip -
replication_port -
===============================================================Swift提供了管理工具模块swift-ring-builder,用于dev的增删改操作,设置备份数量,修改dev的权重等常规运维操作,实质即修改了Ring中的_devs数组的元素。add或remove设备的操作都不会导致Partition到Dev的映射关系发生改变的,只是作用于_devs数据结构,只有在运行了rebalance操作后才会进行Partition的重新分配。
swift-ring-builder <builder_file> add
--region <region> --zone <zone> --ip <ip or hostname> --port <port>
--device <device_name> --weight <weight>
swift-ring-builder <builder_file> remove
--region <region> --zone <zone> --ip <ip or hostname> --port <port>
Swift没有集群状态监测模块,实时地去检测并移除有问题的存储节点,如果有节点出现故障,只能通过报警通知管理员,管理员通过swift-ring-builder去移除有问题的设备。由此可以看出Swift的物理模型只能一个入口导致其状态变化。这样的设计和实现有一定的优点,但同时带来了另外一个问题,如果管理员没有及时移除,那么对于有问题的节点的读写操作,客户端都会做多次重试才能保证数据的可靠性。
这里可以多提一点的是,另外一个无中心管理节点的分布式文件系统Ceph对此问题做了改进和优化,增加了Monitor节点用于存储和更新存储节点状态信息,实现了集群状态监测和自动更新的功能。之前因为这个点,将其归类到了中心管理节点的分布式文件系统,后经过热心的网友提示,才仔细一想确实如此。Ceph对于整个数据定位的实现,从文件名到最终存储设备的映射都是通过计算获得,Monitor只是轻量级的维护了系统的节点信息,所以不能完全归类于中心管理节点的分布式文件系统的范畴。
维护逻辑模型到物理模型的映射
Ring中的_replica2part2dev结构定义了逻辑模型到物理模型的映射的关系,它是一个数组的数组,如下所示:
- 3个array表示的是Ring构建的是一个三备份的存储集群
- 每个array的index表示的是partition_id
- 同一个index对应的元素则为三个备份存储的dev_id
dev_id
|
| +--------|-----------------------------+
| 0 | array([1, 3, 1, 5, 5, 3, 2, 1,.....])
replica | 1 | array([0, 2, 4, 2, 6, 4, 3, 4,.....])
| 2 | array([2, 1, 6, 4, 7, 5, 6, 5,.....])
| +--------------------------------------+
0 1 2 3 4 5 6 7.....................
-------------------------------------->
partition_replica2part2dev结构只有在运行了swift-ring-builder rebalance命令后才会生成数据或者改变。Ring的rebalance的过程本质就是根据Ring定义的物理模型和逻辑模型状态变化重新计算和生成_replica2part2dev映射关系的过程,增/删dev或修dev权重,更改备份数量等都会引起Ring的模型状态发生变化,进而需要rebalance,重新计算和分配每个dev的Partition,生成新的Ring数据。然后管理员将其更新至集群的所有节点,系统的不同进程服务会利用最新的Ring数据实现数据定位和数据迁移操作。
最后再回到文章开头提到的图,结合文章分析可以得出,不管是有中心管理节点还是无中心管理节点的分布式文件存储系统在对于集群管理功能需要解决的问题是一致的,所以涉及到的系统模型定义也是大体相同的,在模型数据存储的方式,以及逻辑模型到物理模型的映射关系的计算方式有一些区别。
以上,希望对分布式文件存储系统的理解有所帮助。篇幅有限,后续再分析swift的Ring的rebalance过程的细节。