本文是由https://github.com/ibab/tensorflow-wavenet翻译的而来。
这是以tensorflow框架来实现WaveNet神经网络用于语音生成的完整案例。
WaveNet神经网络架构能够直接生成原始语音波形,结果显示其在文语转换(TTS)和声音生成方面有着出色的效果。
WaveNet给定所有先前的样本和可能的附加参数,网络对条件概率进行建模以生成音频波形中的下一个样本。
在音频预处理步骤之后,输入波形量化为固定的整数范围。 这一堆整数然后会被编码为一个大小为(num_samples, num_channels)的one-hot矩阵。
仅访问当前和之前输入的卷积层能够减小信道维度。
网络的核心是由一系列因果扩张层构成的,每一层都是一个扩大的卷积(带步长的卷积),它只能访问当前和过去的音频样本。
所有的图层组合在一起并且通过一系列的密集后处理层能够扩展会原来的通道数量,接着使用softmax函数将输出转换为分类分布。
损失函数是每个时间步长的输出和下一个时间步长输入之间的交叉熵代价函数。
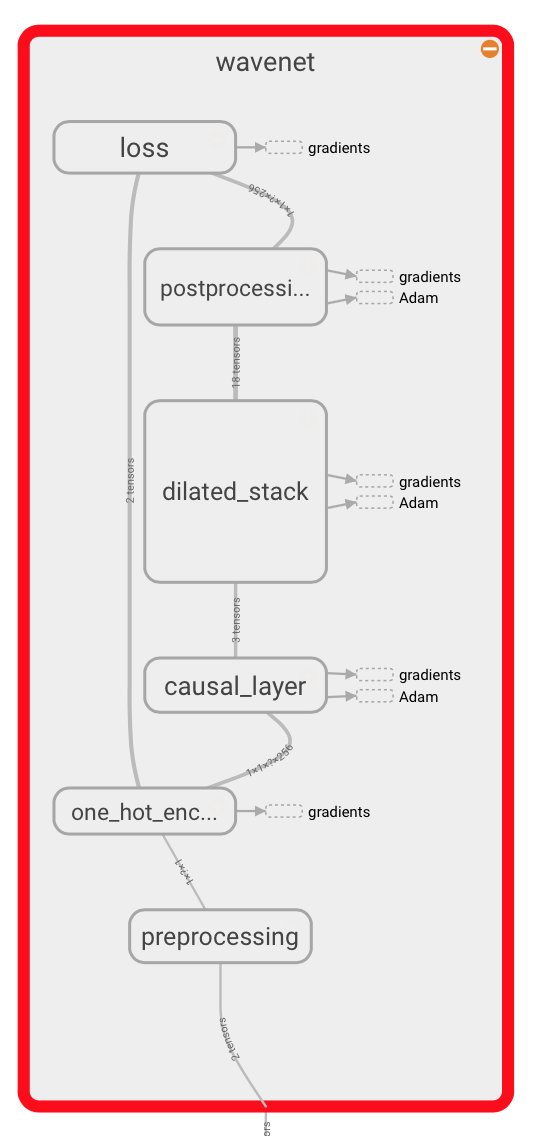
在这个代码库中,网络的实现可以在model.py中找到。
代码运行要求:
在运行训练脚本之前需要安装TensorFlow。 代码在TensorFlow版本1.0.1上针对Python 2.7和Python 3.5进行测试。
此外,librosa库必须安装好,用于读入和写入音频信号。
安装好了必要的包之后运行pip install -r requirements.txt
对于GPU版本,使用pip install -r requirements_gpu.txt
训练网络:
你可以使用任意后缀名为.wav的语料库,论文中使用的是VCTK corpus(大约10.4G,备用),为了训练网络,请执行python train.py --data_dir=corpus
其中语料库是包含.wav文件的目录。 该脚本将递归地收集目录中的所有.wav文件。
你可以查看每一个训练设置的文档通过运行python train.py --help
你可以在wavenet_params.json文件中找到模型参数的配置数值。这些参数在训练过程和生成音频的过程中要保持一致。
全局调节(全局条件修改):Global conditioning
全局条件修改是指修改模型,使得在训练和生成.wav文件期间指定一组互斥类别的ID。 在VCTK的情况下,这个ID是说话者的整数ID,其中有一百以上。 这允许(确实需要)在生成时指定讲话者ID以选择它应该模仿哪个讲话者。 欲了解更多信息,请参阅论文或源代码。
运用全局调节来训练:
以上关于训练的说明指的是没有全局调节的训练。 要使用全局条件训练,请按如下方式指定命令行参数:
python train.py --data=corpus --gc_channels=32
--gc_channels参数做了两件事情:1、告诉train.py程序,需要构建一个包含全局调节的模型
2、指定了embedding vector 的size,这个值是由说话人不同的id决定的。
train.py和audio_reader.py中的全局条件逻辑此时与VCTK语料库"hard-wired",因为它期望能够从VCTK中使用的文件命名模式中确定演讲者ID,而且是可以很容易被修改的。
生成音频信号:
soundcloud.com上有@jyegerlehner根据VCTK语料库中的扬声器280生成的输出示例。可以使用插件下载。
你可以运行generate.py脚本来生成音频信号,使用先训练好的模型。
不适用全局调节来生成:
运行python generate.py --samples 16000 logdir/train/2017-02-13T16-45-34/model.ckpt-80000
logdir/train/2017-02-13T16-45-34/model.ckpt-80000需要成为先保存模型的路径(不带扩展名),--samples参数指定您想要生成多少个音频采样(默认情况下16000对应于1秒)。
生成的波形可以通过使用tensorboard显示,或者用--wav_out_path参数存储为.wav格式。
python generate.py --wav_out_path=generated.wav --samples 16000 logdir/train/2017-02-13T16-45-34/model.ckpt-80000
除了--wav_out_path之外--save_every将每n个样本保存正在生成的.wav文件。
python generate.py --wav_out_path=generated.wav --save_every 2000 --samples 16000 logdir/train/2017-02-13T16-45-34/model.ckpt-80000
默认状态是快速生成,使用的案例来自于https://github.com/tomlepaine/fast-wavenet储存仓,你可以有上述连接探索它是如何工作的,这种方式可以使生成样本的时间降低一些。
只需要将fast generateion设置为不使能状态:
python generate.py --samples 16000 logdir/train/2017-02-13T16-45-34/model.ckpt-80000 --fast_generation=false
在全局调节下生成音频:
包含全局调节的模型生成可执行如命令:
python generate.py --samples 16000 --wav_out_path speaker311.wav --gc_channels=32 --gc_cardinality=377 --gc_id=311 logdir/train/2017-02-13T16-45-34/model.ckpt-80000
其中,--gc_channels=32指示的32是embedding vector的大小,这个值必须和训练时候设置的数值相同
--gc_cardinality=377表明VCTK语料库中最大的发音人id为376,如果使用其他语料库,则此编号应与训练时由train.py脚本自动确定并打印的内容相匹配。
--gc_id=311表明了发音人的标号是311,即要生成的样本也应当对应标号为311的说话者的语音。
执行测试:
安装测试要求:pip install -r requirements_test.txt
运行测试套件:
./ci/test.sh
缺少的功能:
目前没有进行本地调节的额外信息,额外信息允许上下文堆栈或控制生成什么语音。
相关项目:
tex-wavenet https://github.com/Zeta36/tensorflow-tex-wavenet
image-wavenet https://github.com/Zeta36/tensorflow-image-wavenet