一、策略
1. 状态转移概率函数

状态的随机性来自于状态转移函数。当状态 s 和动作 a 都被确定下来,下一个状态仍然有随机性。
2.随机策略

**动作的随机性来自于随机决策。**
3.确定策略

4.价值函数
4.1 动作价值函数
- 折扣率

- U t U_t Ut中的随机性来自于 t + 1 时刻起的所有的状态和动作,因此对回报 U t U_t Ut求期望,消除掉其中的随机性。


4.2 最优动作价值函数
消除 π \pi π的影响,就是要选择最好的策略函数 π \pi π,记为 Q ∗ ( s t , a t ) : Q_*(st,at): Q∗(st,at):
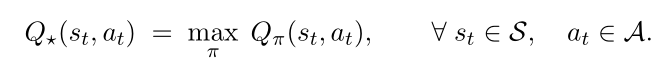
其中只依赖于 s t 和 a t ,而与策略 π 无关。
4.3 状态价值函数 V π V_\pi Vπ

- 衡量当前状态的胜算程度。
- 用状态价值可以衡量策略 π 与状态 st 的好坏。
5.补充
-
轨迹

-
区别回合(episodes)和epoch
- 一个 epoch 意思是用所有训练数据进行前向计算和反向传播,而且每条数据恰好只用一次。常用于监督学习。
- “回合”的概念来自游戏,指智能体从游戏开始到通关或者结束的过程。强化学习对样本数量的要求很高,即
便是个简单的游戏,也需要玩上万回合游戏才能学到好的策略。