(1)概述及特点
官方解释:Apache Flink® — Stateful Computations over Data Streams
- Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台
Flink1.12官方文档:


(2)应用类型
(2.1)事件驱动型应用
什么是事件驱动型应用?
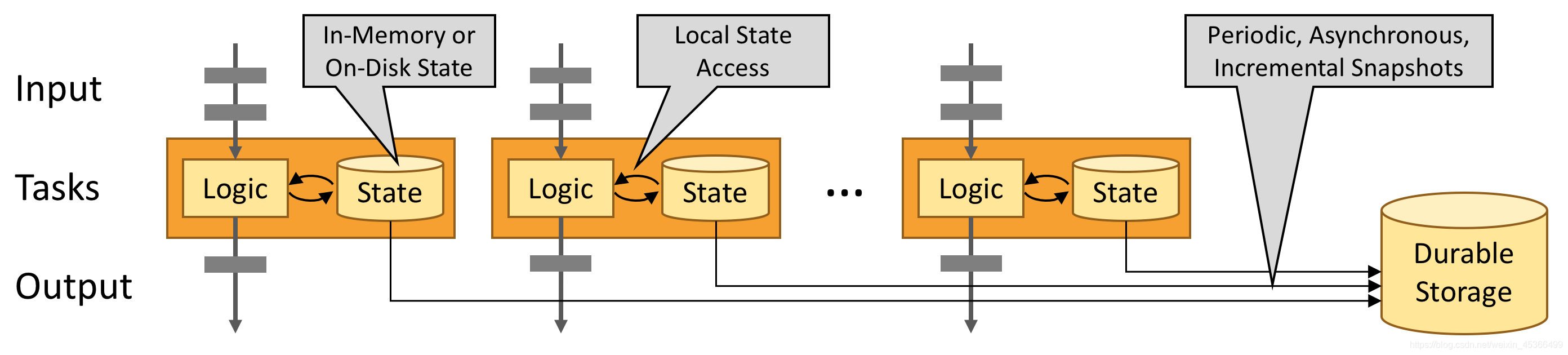
事件驱动的应用程序是有状态的应用程序,它从一个或多个事件流中提取事件,并通过触发计算,状态更新或外部操作来对传入的事件做出响应。也就是说根据我们设定的数据处理逻辑规则,我们可以对传入的一条消息或者多条消息进行实时计算,计算的结果我们以state的方式缓存本地,同时将结果发送到下一个消息系统等待被其他应用程序来处理。
下图描述了传统应用和事件驱动型应用架构的区别:
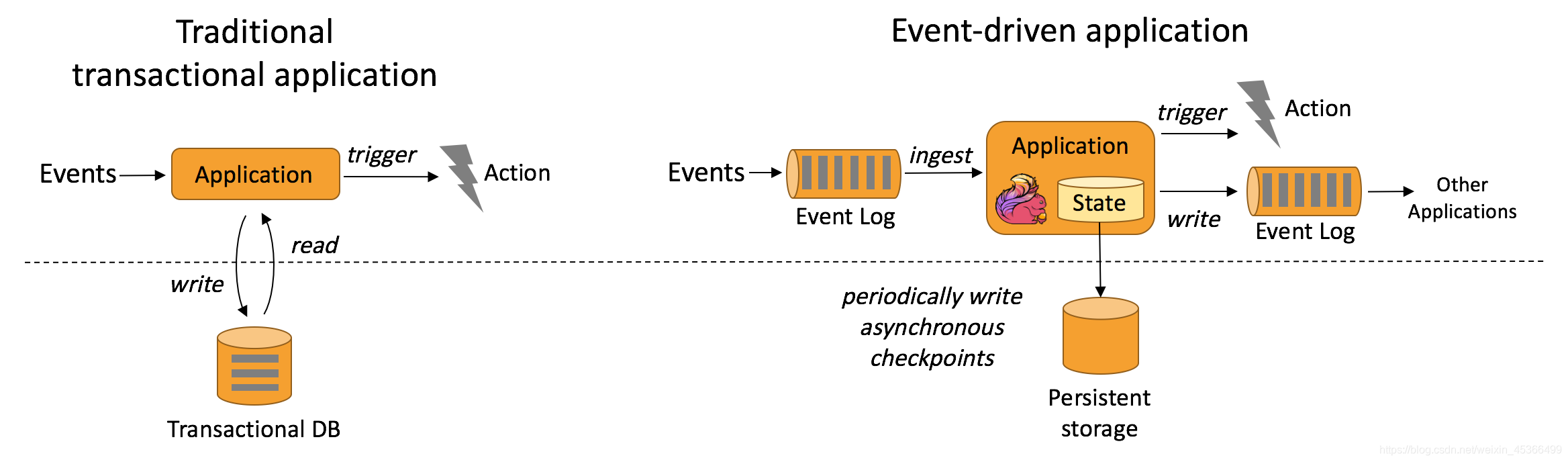
事件驱动型应用的优势?
事件驱动型应用无须查询远程数据库,本地数据访问使得它具有更高的吞吐和更低的延迟。而由于定期向远程持久化存储的 checkpoint 工作可以异步、增量式完成,因此对于正常事件处理的影响甚微。事件驱动型应用的优势不仅限于本地数据访问。传统分层架构下,通常多个应用会共享同一个数据库,因而任何对数据库自身的更改(例如:由应用更新或服务扩容导致数据布局发生改变)都需要谨慎协调。反观事件驱动型应用,由于只需考虑自身数据,因此在更改数据表示或服务扩容时所需的协调工作将大大减少。
典型的事件驱动型应用实例:
- 欺诈识别
- 异常检测
- 基于规则的警报
- 业务流程监控
- Web应用程序(社交网络)
(2.2)流批数据分析应用
什么是数据分析应用?
数据分析任务需要从原始数据中提取有价值的信息和指标。传统的分析方式通常是利用批查询,或将事件记录下来并基于此有限数据集构建应用来完成。为了得到最新数据的分析结果,必须先将它们加入分析数据集并重新执行查询或运行应用,随后将结果写入存储系统或生成报告。
借助一些先进的流处理引擎,还可以实时地进行数据分析。和传统模式下读取有限数据集不同,流式查询或应用会接入实时事件流,并随着事件消费持续产生和更新结果。这些结果数据可能会写入外部数据库系统或以内部状态的形式维护。仪表展示应用可以相应地从外部数据库读取数据或直接查询应用的内部状态。
如下图所示,Apache Flink 同时支持流式及批量分析应用。
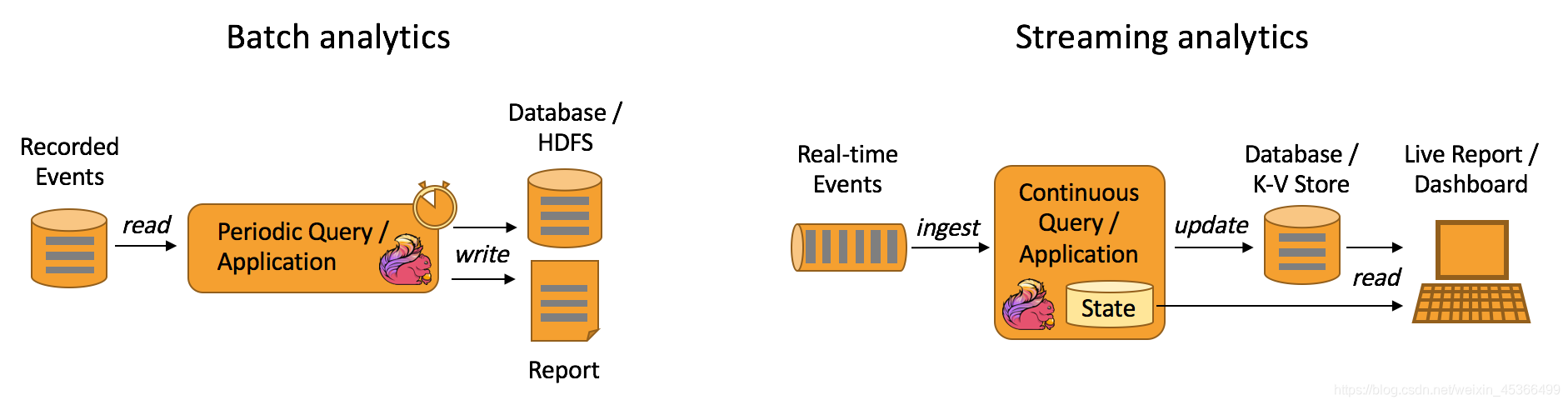
典型的数据分析应用实例
- 电信网络质量监控
- 移动应用中的产品更新及实验评估分析
- 消费者技术中的实时数据即席分析
- 大规模图分析
(2.3)数据管道应用
什么是数据管道?
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发。因此它支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。
下图描述了周期性 ETL 作业和持续数据管道的差异。
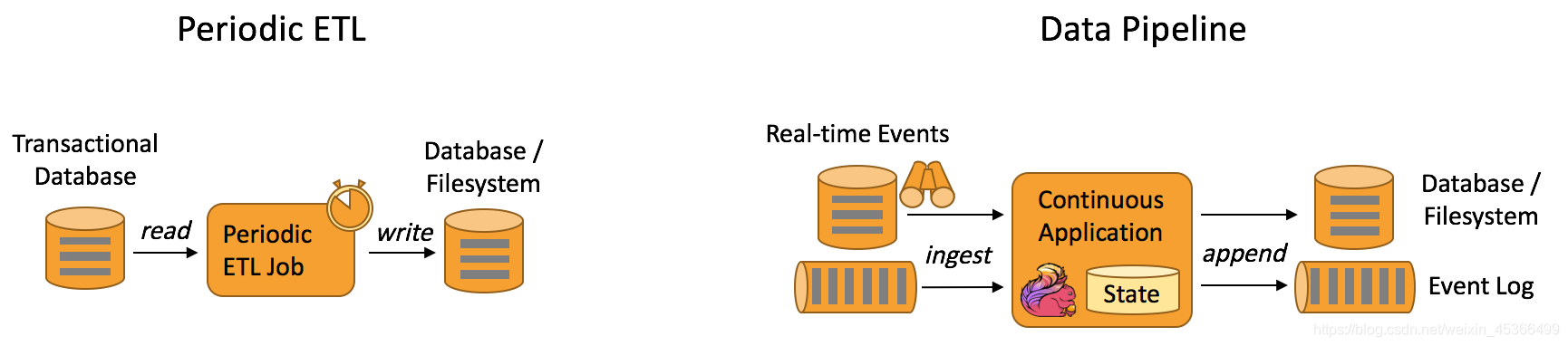
典型的数据管道应用实例
- 电子商务中的实时查询索引构建
- 电子商务中的持续 ETL
(3)容错性
(3.1)Exactly-once状态一致性
Flink 的 checkpoint 和故障恢复算法保证了故障发生后应用状态的一致性。状态可存储在内存或RocksDB(高效的key一value存储)。因此,Flink 能够在应用程序发生故障时,对应用程序透明,不造成正确性的影响。
(3.2)基于事件时间的处理
使用事件时间语义的流处理应用根据事件本身自带的时间戳进行结果的计算。因此,无论处理的是历史记录的事件还是实时的事件,事件时间模式的处理总能保证结果的准确性和一致性。
(3.3)基于迟到数据的事件处理
当以带有 watermark 的事件时间模式处理数据流时,在计算完成之后仍会有相关数据到达。这样的事件被称为迟到事件。Flink 提供了多种处理迟到数据的选项,例如将这些数据重定向到旁路输出(side output)或者更新之前完成计算的结果。
(4)分层API
Flink 根据抽象程度分层,提供了三种不同的 API。每一种 API 在简洁性和表达力上有着不同的侧重,并且针对不同的应用场景。
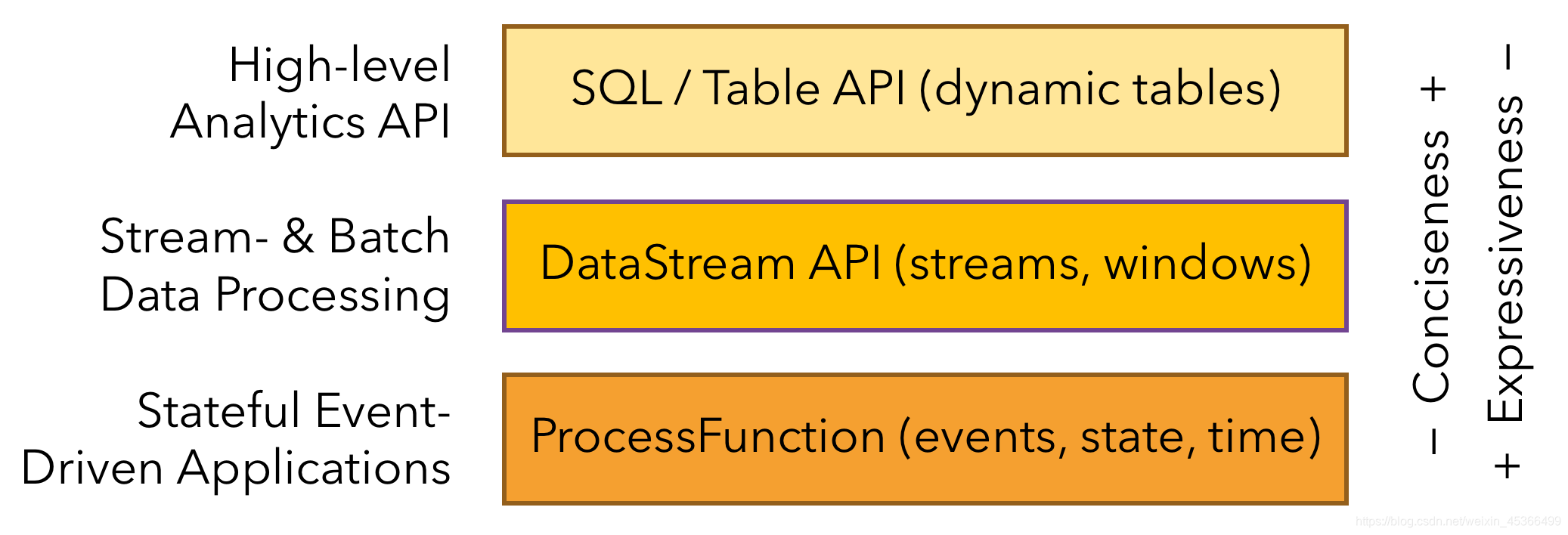
(4.1)ProcessFunction(底层流处理)
Flink提供了ProcessFunctions来处理来自一个或两个输入流或分组在一个窗口中的事件的单个事件。
ProcessFunctions提供对时间和状态的细粒度控制。ProcessFunction可以任意修改其状态并注册计时器,这些计时器将来会触发回调函数。
(4.2)DataStream API & DataSet API(提供应用开发层面的API)
DataStream API 为许多通用的流处理操作提供了处理原语。这些操作包括窗口、逐条记录的转换操作,在处理事件时进行外部数据库查询等。DataStream API 支持 Java 和 Scala 语言,预先定义了例如map()、reduce()、aggregate() 等函数。你可以通过扩展实现预定义接口或使用 Java、Scala 的 lambda 表达式实现自定义的函数。
(4.3)SQL on Stream & Batch Data(基于SQL的流批处理)
Flink 支持两种关系型的 API,Table API 和 SQL。这两个 API 都是批处理和流处理统一的 API,这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型 API 会以相同的语义执行查询,并产生相同的结果。Table API 和 SQL 借助了 Apache Calcite 来进行查询的解析,校验以及优化。它们可以与 DataStream 和 DataSet API 无缝集成,并支持用户自定义的标量函数,聚合函数以及表值函数。
(5)运维
(5.1)灵活部署
Flink已与多种集群管理服务紧密集成,如 Hadoop YARN, Mesos, 以及 Kubernetes。
(5.2)高可用性
Flink内置了为解决单点故障问题的高可用性服务模块,此模块是基于Apache ZooKeeper 技术实现的,Apache ZooKeeper是一种可靠的、交互式的、分布式协调服务组件。
(5.3)Savepoints
Flink的Savepoint的是一项独特而强大的功能。保存点是应用程序状态的一致快照,因此与Checkpoints非常相似。但是,与Checkpoint相比, Savepoint需要手动触发,并且在停止应用程序时不会自动将其删除。Savepoint可用于启动状态兼容的应用程序并初始化其状态
Savepoint启用的功能场景:
- 应用程序升级: 可以从先前版本的应用程序中获取的 Savaepoint重新启动应用程序的固定版本或改进版本。也可以从较早的时间点启动应用程序(如果存在这样的
Savepoint),以修复有缺陷的版本产生的错误结果 。 - 集群迁移: 使用 Savepoint,可以将应用程序迁移(或克隆)到不同的集群。
- Flink版本更新: 可以使用 Savepoint迁移应用程序以在新的 Flink版本上运行。
- 应用程序并行度: 保存点可用于增加或减少应用程序的并行性。
- A/B测试: 可以通过从同一保存点启动所有版本来比较应用程序的两个(或多个)不同版本的性能或质量。
- 暂停和恢复: 可以通过保存一个点并停止它来暂停应用程序。在以后的任何时间点,都可以从保存点恢复应用程序。
(6)扩展性
(6.1)资源无限扩展
Flink应用程序被并行化为可能数千个任务,这些任务分布在集群中并发执行。所以应用程序能够充分利用无尽的 CPU、内存、磁盘和网络 IO。
(6.2)支持大数据量的状态持久化
Flink 很容易维护非常大的应用程序状态。其异步和增量的Checkpoint算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
(6.3)增量的Checkpoint
Flink 很容易维护非常大的应用程序状态。其异步和增量的Checkpoint算法对处理延迟产生最小的影响,同时保证精确一次状态的一致性。
(7)性能
- 低延迟
- 高吞吐
- 内存计算
有状态的 Flink 程序针对本地状态访问进行了优化。任务的状态始终保留在内存中,如果状态大小超过可用内存,则会保存在能高效访问的磁盘数据结构中。任务通过访问本地(通常在内存中)状态来进行所有的计算,从而产生非常低的处理延迟。Flink 通过定期和异步地对本地状态进行持久化存储来保证故障场景下精确一次的状态一致性。
以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!