本文提出一种新的基于 condition NeRF 的 talking portrait 合成框架 ER-NeRF,可以在较小的参数量下实现高精度的实时渲染和快收敛。用于合成高保真Talking Portrait的高效区域感知神经辐射场
单位:北京航空航天大学,格里菲斯大学,RIKEN AIP,东京大学
论文:https://arxiv.org/abs/2307.09323
代码:https://github.com/Fictionarry/ER-NeRF
Abstract
本文提出一种新的基于 condition NeRF 的 talking portrait 合成框架 ER-NeRF,可以在较小的参数量下实现高精度的实时渲染和快速收敛。我们的想法是显示利用空间区域的不平等贡献来指导谈话肖像建模。具体而言,为了提高动态头部重建的准确性,通过使用三个2D哈希编码器修剪空间区域,我们引入了一种紧凑且富有表现力的基于NeRF的三平面哈希表示。对于语音音频,我们提出了一个区域注意模块,通过区域注意力机制生成区域感知条件特征。现有的方法通常利用基于MLP的编码器隐式地学习音频-视频跨模态关系,而在我们的方法使用注意力机制在音频特征和空间区域之间建立了显式连接,以捕捉局部运动的先验。此外,对于身体部分,我们提出了一种直观且快速的适应性姿态编码,通过将头部姿态的复杂变换映射到空间坐标中以优化头部-躯干分离问题。大量实验表明,与以前的方法相比,在talking portrait 合成任务中,我们的方法在高保真度和唇形同步程度上表现更优,并具有逼真的细节和更高的效率。
 图1. 与以往的方法不同,我们没有通过基于MLP的编码器来学习隐含的音频-视觉关系,而是明确地关注语音音频和空间区域之间的跨模态交互。区域感知使ER NeRF能够呈现更准确的面部运动。
图1. 与以往的方法不同,我们没有通过基于MLP的编码器来学习隐含的音频-视觉关系,而是明确地关注语音音频和空间区域之间的跨模态交互。区域感知使ER NeRF能够呈现更准确的面部运动。
1. Introduction
音频驱动的 talking portrait 合成是一个重要而具有挑战性的问题,并有多种潜在应用场景,如数字人、虚拟化身、电影制作和视频会议。在过去的几年里,许多研究人员已经用深度生成模型来处理这项任务。最近,神经辐射场(NeRF)被引入到音频驱动的说话肖像合成中。它提供了一种通过深度多层感知器(MLP)学习从音频特征到相应视觉外观的直接映射的新方法。此后,一些研究以端到端的方式或通过一些中间表示对音频信号进行NeRF条件处理,以重建特定的说话肖像。尽管这些基于NeRF的方法在合成质量上取得了巨大成功,但推理速度远远不能满足实时性要求,这严重限制了它们的实际应用。
最近,一些关于高效神经表示的工作通过用稀疏特征网格替换MLP网络的一部分,实现了对NeRF的显著加速。Instant-NGP 引入用于静态场景建模的哈希编码体素网格,使用紧凑的模型实现了快速和高质量的渲染。RAD NeRF首先将这项技术应用于 talking portrait 合成,并构建了一个具有最先进性能的实时渲染框架。然而,RAD-NeRF需要一个复杂的带有MLP的网格编码器来隐式学习区域性的音频-动作映射,这限制了其收敛速度和重建质量。
本文旨在探索一种更有效的解决方案,以实现高效、高保真的talking portrait 合成。基于之前的研究,我们注意到不同的空间区域对于 talking portrait 的外观的贡献并不相等:
(1) 在体渲染中,由于只有表面区域有助于表示动态头部,因此大多数其他空间区域是无用的,且头部的表面结构较为简单,可以进一步探索如何使用一些高效NeRF技术进行修剪,以降低训练难度;
(2) 由于不同的面部区域与语音音频具有不同的关联,因此不同的空间区域以其独特的方式与音频信号固有地相关,并表现出独特的音频驱动的局部运动。
受这些观察结果的启发,我们明确利用空间区域的不平等贡献来指导 talking portrait 建模,并提出了一种新颖的 Efficient Region-aware talking portrait NeRF (ER-NeRF)框架,用于逼真高效的 talking portrait 合成,该框架在具有较小模型尺寸的情况下实现了高质量的渲染、快速收敛和实时推理。
本文的贡献主要在于:
(1) 我们引入了一种高效的三平面哈希表示来促进动态头部重建,以紧凑的模型大小实现了高质量的渲染、实时推理和快速收敛。(2)我们提出了一种新颖的区域注意模块来捕捉音频条件和空间区域之间的相关性,以进行精确的面部运动建模。
2. Methods

 2.1 Hash Tri-Plane Representation
2.1 Hash Tri-Plane Representation
我们的第一个改进针对在动态头部表示上。尽管RAD NeRF利用Instant-NGP来表示 talking portrait 并实现了快速推理,但在对音频驱动的3D动态头部建模时,其渲染质量和收敛性受到哈希冲突的阻碍。为了解决这个问题,我们引入了一种三平面哈希表示,该表示通过基于NeRF的三平面分解将3D空间分解为三个正交平面。在因子分解过程中,所有空间区域都被压缩到2D平面上,并修剪相应的特征网格。因此,散列冲突仅发生在低维子空间中且数量更少。在噪声较少的情况下,网络可以更加关注音频特征的处理,从而能够重建更准确的头部结构和更精细的动态运动。
 图3. 可视化的占用网格。(a)没有音频条件的纯静态3D哈希网格。(b,c)3D哈希网格和我们的以音频为条件的三平面哈希表示。在被要求处理音频特征并同时学习动态运动后,3D哈希网格的MLP解码器表现出过载,而我们的表示仍然可以重建精细的表面。
图3. 可视化的占用网格。(a)没有音频条件的纯静态3D哈希网格。(b,c)3D哈希网格和我们的以音频为条件的三平面哈希表示。在被要求处理音频特征并同时学习动态运动后,3D哈希网格的MLP解码器表现出过载,而我们的表示仍然可以重建精细的表面。
 2.2 Region Attention Module
2.2 Region Attention Module
音频等动态条件几乎不会均匀地对整个portrait产生影响。因此,了解这些条件如何影响肖像的不同区域对于生成自然的面部运动至关重要。许多以往的工作在特征层面忽略了这一点,并使用一些昂贵的方法来隐式地学习其中的相关性。通过利用存储在哈希编码器中的多分辨率区域信息,我们引入了一种轻量级区域注意机制来显式获取动态特征和不同空间区域之间的关系。


图4. 区域注意力模块的可视化。即使受到一些不确定细节(如蓬松的头发)的影响,我们的区域注意模块也成功地捕获了动态条件和空间区域之间的关系,而无需显式的标注。
2.3 Adaptive Pose Encoding
 图5. Adaptive Pose Encoding
图5. Adaptive Pose Encoding
为了解决头躯干分离问题,我们在之前的工作的基础上进行了改进(RAD-NeRF,GeneFace)。我们没有直接使用整个图像或姿势矩阵作为条件,而是将头部姿势的复杂变换映射到具有更清晰位置信息的几个关键点的坐标,并引导torso-NeRF从中学习隐式躯干姿势坐标。

3. Experiments
3.1 定量实验
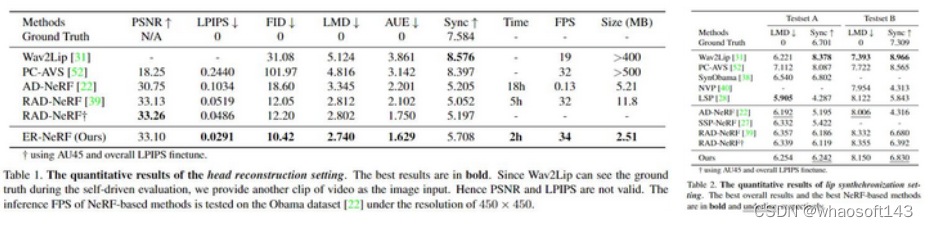
在_自驱动_和_异源音频驱动_两个setting下,我们的方法在基于NeRF的方法中同时在渲染质量、唇形同步、面部动作重建、训练时间、模型尺寸和推理速度上均表现最优。
 3.2 定性实验
3.2 定性实验
为了对整个肖像(头部+躯干)进行直观的比较,我们在图6中展示了部分视频关键帧和四个任务的细节。对于基于 NeRF 的方法,我们合成躯干部分来评估整个肖像。结果表明,ER-NeRF 能够渲染出更多细节,并具有最高的个性化口型同步精度。虽然 Wav2Lip 和 PC-AVS 在 Sync 方面取得了很高的分数,但它们生成的结果与真实情况有明显的差距。
对于合成的躯干部分, AD-NeRF 中的头部-躯干分离(黄色箭头)的问题较为突出,而 RAD-NeRF 的躯干在某些极端情况下也无法与头部对齐(红色箭头),而ER-NeRF由于Adaptive Pose Encoding 在躯干合成上表现出更高的鲁棒性和质量。
 图6. 定性结果
图6. 定性结果
为了进一步的评估合成质量,我们使用问卷调查的形式邀请真人进行了user study。实验结果表明我们的方法能够合成高真实度的talking portrait视频。
 同时我们对稳定性进行了测试,在一些转动角度较大的视角下,我们的方法仍表现出良好的稳定性。 whaosoft aiot http://143ai.com
同时我们对稳定性进行了测试,在一些转动角度较大的视角下,我们的方法仍表现出良好的稳定性。 whaosoft aiot http://143ai.com
 3.3 消融实验
3.3 消融实验
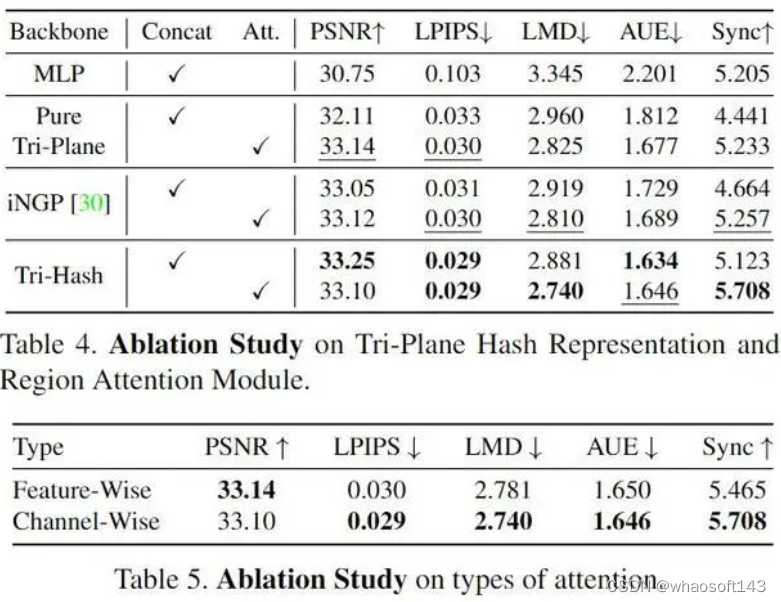 Representation. 我们对三个不同的 representation backbone 的头部重建质量进行评估。首先是基于纯MLP 的网络,与 AD-NeRF相同。其次,对于基于 grid 的 backbone,我们将我们的 Tri-Hash 与 EG3D中的 pure tri-plane 和 RAD-NeRF 中使用的 Instant-NGP 3D 哈希网格进行比较 。所提出的三哈希表示实现了最佳图像质量,并显着改进了唇形同步。
Representation. 我们对三个不同的 representation backbone 的头部重建质量进行评估。首先是基于纯MLP 的网络,与 AD-NeRF相同。其次,对于基于 grid 的 backbone,我们将我们的 Tri-Hash 与 EG3D中的 pure tri-plane 和 RAD-NeRF 中使用的 Instant-NGP 3D 哈希网格进行比较 。所提出的三哈希表示实现了最佳图像质量,并显着改进了唇形同步。
Region Attention Module. 与直接concat相比,我们评估了三个backbone上的区域注意机制。结果显示了我们的方法对精确运动建模的巨大影响。值得注意的是,仅仅通过仅将所提出的注意力机制与现有的主干结合使用,我们便可以在图像质量和唇形同步方面获得比当前最先进的方法更好的分数,同时训练时间减少一半且参数更少,这表明了我们的注意力机制的高效性。
注意力类型. 在表 5 中,我们比较了区域注意力机制的两种类型的注意力:feature-wise 和 channel-wise。feature-wise 的注意力使用一维注意力向量缩放整个音频特征,而 channel-wise 则对每个通道重新加权。我们的实验表明,在口型同步质量方面,channel-wise 优于 feature-wise,这表明所提出的区域注意机制成功捕获了不同空间区域间的互不相同的独特影响,并因此显着提高了口型运动质量。
4. 总结
在本文中,我们提出了一种高校且有效的用于合成高保真 talking portrait 的框架 ER-NeRF,主要由三平面哈希表示和区域注意模块组成。我们的框架以更高的效率在高保真 talking portrait 合成任务上取得了显著的性能进步。这也可能为 condition NeRF 的设计提供新技术。