Stanford Alpaca 是在 LLaMA 整个模型上微调,即对预训练模型中的所有参数都进行微调(full fine-tuning)。但该方法对于硬件成本要求仍然偏高且训练低效。
因此, Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降,还能获得和全模型微调(full fine-tuning)类似的效果。
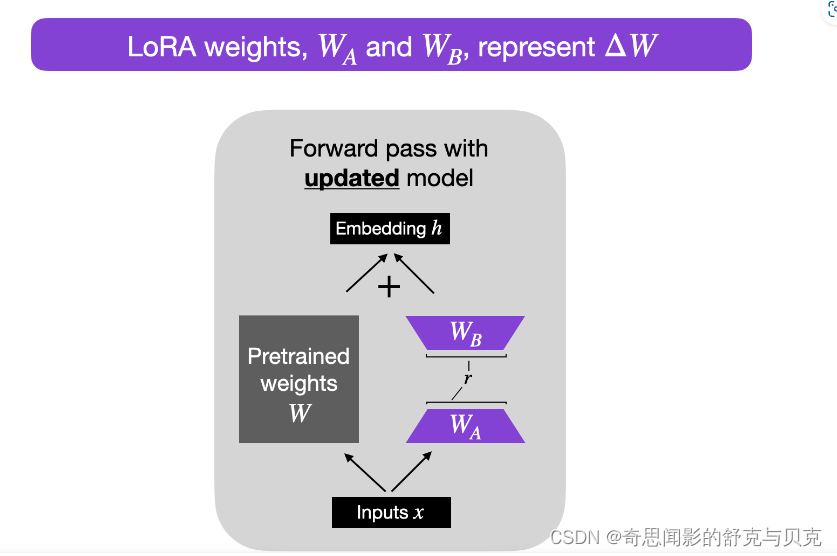
LoRA 的原理其实并不复杂,它的核心思想是在原始预训练语言模型旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank(预训练模型在各类下游任务上泛化的过程其实就是在优化各类任务的公共低维本征(low-dimensional intrinsic)子空间中非常少量的几个自由参数)。训练的时候固定预训练语言模型的参数,只训练降维矩阵 A 与升维矩阵 B。而模型的输入输出维度不变,输出时将 BA 与预训练语言模型的参数叠加。用随机高斯分布初始化 A,用 0 矩阵初始化 B。这样能保证训练开始时,新增的通路BA=0从,而对模型结果没有影响。
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。
LoRA 的最大优势是速度更快,使用的内存更少;因此,可以在消费级硬件上运行。
一 环境搭建
基础环境配置如下:
- 操作系统: CentOS 7
- CPUs: 单个节点具有 1TB 内存的 Intel CPU,物理CPU个数为64,每颗CPU核数为16
- GPUs: 4 卡 A100 80GB GPU
- Docker Image: pytorch:1.13.0-cuda11.6-cudnn8-devel
在 Alpaca-LoRA 项目中,作者提到,为了廉价高效地进行微调,他们使用了 Hugging Face 的 PEFT。PEFT 是一个库(LoRA 是其支持的技术之一,除此之外还有Prefix Tuning、P-Tuning、Prompt Tuning),可以让你使用各种基于 Transformer 结构的语言模型进行高效微调。下面安装PEFT。
#安装peft
git clone https://github.com/huggingface/peft.git
cd peft/
pip install .
#安装bitsandbytes。
git clone [email protected]:TimDettmers/bitsandbytes.git
cd bitsandbytes
CUDA_VERSION=116 make cuda11x
python setup.py install如果安装 bitsandbytes出现如下错误: /usr/bin/ld: cannot find -lcudart
请行执行如下命令
cd /usr/lib
ln -s /usr/local/cuda/lib64/libcudart.so libcudart.so#下载alpaca-lora
git clone [email protected]:tloen/alpaca-lora.git
cd alpaca-lora
pip install -r requirements.txtrequirements.txt文件具体的内容如下:
accelerate
appdirs
loralib
bitsandbytes
black
black[jupyter]
datasets
fire
git+https://github.com/huggingface/peft.git
transformers>=4.28.0
sentencepiece
gradio模型格式转换
将LLaMA原始权重文件转换为Transformers库对应的模型文件格式。可以直接从Hugging Face下载转换好的模型如下:
下载方法可以参考:[NLP]Huggingface模型/数据文件下载方法
decapoda-research/llama-7b-hf · Hugging Face
decapoda-research/llama-13b-hf · Hugging Face
模型微调
python finetune.py \
--base_model '/disk1/llama-13b' \
--data_path './alpaca_data_cleaned_archive.json' \
--output_dir './lora-alpaca' \
--batch_size 128 \
--micro_batch_size 8 \
--num_epochs 1
torchrun --nproc_per_node=4 --master_port=29000 finetune.py \
--base_model '/disk1/llama-13b' \
--data_path './alpaca_data_cleaned_archive.json' \
--output_dir './lora-alpaca' \
--batch_size 128 \
--micro_batch_size 8 \
--num_epochs 1Training Alpaca-LoRA model with params:
base_model: /disk1/llama-13b
data_path: ./alpaca_data_cleaned_archive.json
output_dir: ./lora-alpaca
batch_size: 128
micro_batch_size: 8
num_epochs: 1
learning_rate: 0.0003
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
add_eos_token: False
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpaca
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.
warnings.warn(
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.
warnings.warn(
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.
warnings.warn(
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.
warnings.warn(
trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 3%|███▊ | 1330/49759 [00:01<00:39, 1216.23 examples/s]trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 0%| | 0/49759 [00:00<?, ? examples/s]trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 1%|▊ | 272/49759 [00:00<00:36, 1350.21 examples/s]trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:38<00:00, 1294.31 examples/s]
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:38<00:00, 1284.04 examples/s]
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:38<00:00, 1283.95 examples/s]
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1221.03 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:39<00:00, 1274.42 examples/s]
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1285.16 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1281.27 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1290.31 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
0%| | 0/388 [00:00<?, ?it/s]/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantization
warnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantization
warnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantization
warnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantization
warnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
{'loss': 2.249, 'learning_rate': 2.9999999999999997e-05, 'epoch': 0.03}
{'loss': 2.1927, 'learning_rate': 5.6999999999999996e-05, 'epoch': 0.05}
{'loss': 2.0813, 'learning_rate': 7.8e-05, 'epoch': 0.08}
{'loss': 1.7206, 'learning_rate': 0.00010799999999999998, 'epoch': 0.1}
11%|████████████████▋ 11%|███████████▋ | 42/388 [10:50<1:27:24卡输出结果如上图,显存占用如下
-------------------------------+----------------------+----------------------+
| 0 NVIDIA A100-SXM... On | 00000000:47:00.0 Off | 0 |
| N/A 60C P0 322W / 400W | 36944MiB / 81920MiB | 89% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100-SXM... On | 00000000:4B:00.0 Off | 0 |
| N/A 61C P0 321W / 400W | 34204MiB / 81920MiB | 97% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA A100-SXM... On | 00000000:89:00.0 Off | 0 |
| N/A 62C P0 349W / 400W | 34200MiB / 81920MiB | 98% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA A100-SXM... On | 00000000:8E:00.0 Off | 0 |
| N/A 63C P0 261W / 400W | 33882MiB / 81920MiB | 89% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+导出为 HuggingFace 格式:
可以下载: Angainor/alpaca-lora-13b · Hugging Face 的lora_weights
修改export_hf_checkpoint.py文件:
import os
import torch
import transformers
from peft import PeftModel
from transformers import LlamaForCausalLM, LlamaTokenizer # noqa: F402
BASE_MODEL = os.environ.get("BASE_MODEL", "/disk1/llama-13b")
LORA_MODEL = os.environ.get("LORA_MODEL", "./alpaca-lora-13b")
HF_CHECKPOINT = os.environ.get("HF_CHECKPOINT", "./hf_ckpt")
tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)
base_model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=False,
torch_dtype=torch.float16,
device_map={"": "cpu"},
)
first_weight = base_model.model.layers[0].self_attn.q_proj.weight
first_weight_old = first_weight.clone()
lora_model = PeftModel.from_pretrained(
base_model,
LORA_MODEL,
device_map={"": "cpu"},
torch_dtype=torch.float16,
)
lora_weight = lora_model.base_model.model.model.layers[
0
].self_attn.q_proj.weight
assert torch.allclose(first_weight_old, first_weight)
# merge weights - new merging method from peft
lora_model = lora_model.merge_and_unload()
lora_model.train(False)
# did we do anything?
assert not torch.allclose(first_weight_old, first_weight)
lora_model_sd = lora_model.state_dict()
deloreanized_sd = {
k.replace("base_model.model.", ""): v
for k, v in lora_model_sd.items()
if "lora" not in k
}
LlamaForCausalLM.save_pretrained(
base_model, HF_CHECKPOINT, state_dict=deloreanized_sd, max_shard_size="400MB"
)python export_hf_checkpoint.py
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:26<00:00, 1.56it/s]查看模型输出文件:
hf_ckpt/
├── config.json
├── generation_config.json
├── pytorch_model-00001-of-00082.bin
├── pytorch_model-00002-of-00082.bin
├── pytorch_model-00003-of-00082.bin
├── pytorch_model-00004-of-00082.bin
├── pytorch_model-00005-of-00082.bin
├── pytorch_model-00006-of-00082.bin
├── pytorch_model-00007-of-00082.bin
├── pytorch_model-00008-of-00082.bin
├── pytorch_model-00009-of-00082.bin
├── pytorch_model-00010-of-00082.bin
├── pytorch_model-00011-of-00082.bin
├── pytorch_model-00012-of-00082.bin
├── pytorch_model-00013-of-00082.bin
├── pytorch_model-00014-of-00082.bin
├── pytorch_model-00015-of-00082.bin
├── pytorch_model-00016-of-00082.bin
├── pytorch_model-00017-of-00082.bin
├── pytorch_model-00018-of-00082.bin
├── pytorch_model-00019-of-00082.bin
├── pytorch_model-00020-of-00082.bin
├── pytorch_model-00021-of-00082.bin
├── pytorch_model-00022-of-00082.bin
├── pytorch_model-00023-of-00082.bin
├── pytorch_model-00024-of-00082.bin
├── pytorch_model-00025-of-00082.bin
├── pytorch_model-00026-of-00082.bin
├── pytorch_model-00027-of-00082.bin
├── pytorch_model-00028-of-00082.bin
├── pytorch_model-00029-of-00082.bin
├── pytorch_model-00030-of-00082.bin
├── pytorch_model-00031-of-00082.bin
├── pytorch_model-00032-of-00082.bin
├── pytorch_model-00033-of-00082.bin
├── pytorch_model-00034-of-00082.bin
├── pytorch_model-00035-of-00082.bin
├── pytorch_model-00036-of-00082.bin
├── pytorch_model-00037-of-00082.bin
├── pytorch_model-00038-of-00082.bin
├── pytorch_model-00039-of-00082.bin
├── pytorch_model-00040-of-00082.bin
├── pytorch_model-00041-of-00082.bin
├── pytorch_model-00042-of-00082.bin
├── pytorch_model-00043-of-00082.bin
├── pytorch_model-00044-of-00082.bin
├── pytorch_model-00045-of-00082.bin
├── pytorch_model-00046-of-00082.bin
├── pytorch_model-00047-of-00082.bin
├── pytorch_model-00048-of-00082.bin
├── pytorch_model-00049-of-00082.bin
├── pytorch_model-00050-of-00082.bin
├── pytorch_model-00051-of-00082.bin
├── pytorch_model-00052-of-00082.bin
├── pytorch_model-00053-of-00082.bin
├── pytorch_model-00054-of-00082.bin
├── pytorch_model-00055-of-00082.bin
├── pytorch_model-00056-of-00082.bin
├── pytorch_model-00057-of-00082.bin
├── pytorch_model-00058-of-00082.bin
├── pytorch_model-00059-of-00082.bin
├── pytorch_model-00060-of-00082.bin
├── pytorch_model-00061-of-00082.bin
├── pytorch_model-00062-of-00082.bin
├── pytorch_model-00063-of-00082.bin
├── pytorch_model-00064-of-00082.bin
├── pytorch_model-00065-of-00082.bin
├── pytorch_model-00066-of-00082.bin
├── pytorch_model-00067-of-00082.bin
├── pytorch_model-00068-of-00082.bin
├── pytorch_model-00069-of-00082.bin
├── pytorch_model-00070-of-00082.bin
├── pytorch_model-00071-of-00082.bin
├── pytorch_model-00072-of-00082.bin
├── pytorch_model-00073-of-00082.bin
├── pytorch_model-00074-of-00082.bin
├── pytorch_model-00075-of-00082.bin
├── pytorch_model-00076-of-00082.bin
├── pytorch_model-00077-of-00082.bin
├── pytorch_model-00078-of-00082.bin
├── pytorch_model-00079-of-00082.bin
├── pytorch_model-00080-of-00082.bin
├── pytorch_model-00081-of-00082.bin
├── pytorch_model-00082-of-00082.bin
└── pytorch_model.bin.index.json
0 directories, 85 files导出为PyTorch state_dicts:
修改export_state_dict_checkpoint.py文件:
参考文档:
- LLaMA
- Stanford Alpaca:斯坦福-羊驼
- Alpaca-LoRA