1.半监督的生成模型
面对的问题
如下所示,绿色的点表示没有标签的样本。蓝色和橘色分别表示有标签的样本,分别是C1,C2。我们之前根据标签的数据,给每一类计算出了先验概率P(C1)、P(C2)、均值和协方差。(假设服从高斯分布)。但是,如今有了很多的无标签的数据,我们就不能按照原来的类概率、均值和协方差来估计数据。因为无标签的数据会影响概率和参数。那么我们应该如何计算呢?

解决思路:
step1:有监督的生成模型:首先我们使用有标签的数据来训练模型,初始化参数。
Step2:无监督的生成模型:
- E步:基于上述训练出的模型,计算无标签数据的后验概率( 。
- M步:使用E步得到的后验概率重新更新参数。
- 不断重复E步M步,直到稳定。

2.低密度分离:自学习方法
首先提出一个大胆的假设:这是一个非黑即白的世界。也就是对于数据而言,是Hard label。要么属于某一个类,要么不属于某一个类。
- step1:用已知标签的数据训练一个函数f
- step2:将未知标签的数据带入该函数中,得到“新标签”。
- step3:然后从得到“新标签”的未知标签的数据中抽取一些数据放入已知标签的数据中,重新训练得到一个新的f。重复1,2,3。

补充:我们可以通过给未知标签的数据添加权重的方式来辅助抽取数据。对于回归函数而言,这种训练方式对函数没有影响。
我们可以通过熵来度量通过函数f给未知标签的数据生成的标签的质量。熵越小,表示生成的标签质量越高。
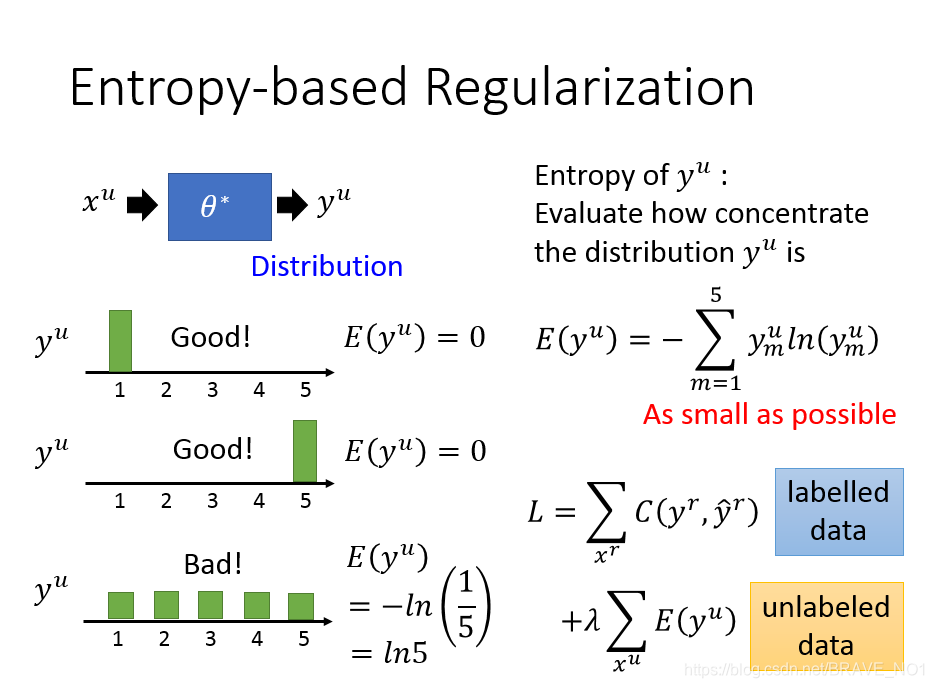
3.平滑假设:基于图的方法
这里我们提供一个假设:这是一个近朱者赤、近墨者黑的世界。更相似的来说,假设x和y之间有着非常强的关联。那么x分布不均匀,则y也可能分布不均匀。假如x类间很相似,那么y类间也很相似。那么如何解释关联呢,关联不一定是直接的关系,我们可以假想成一种通路,比如某个类经过逐步的变化会变成另外一个类,如下面的两个例子。我们可以认为这两个类相关联,那么这种关系该如何表示呢?我们很自然得想到了图。节点与节点之间的连通是可以”传递“的。
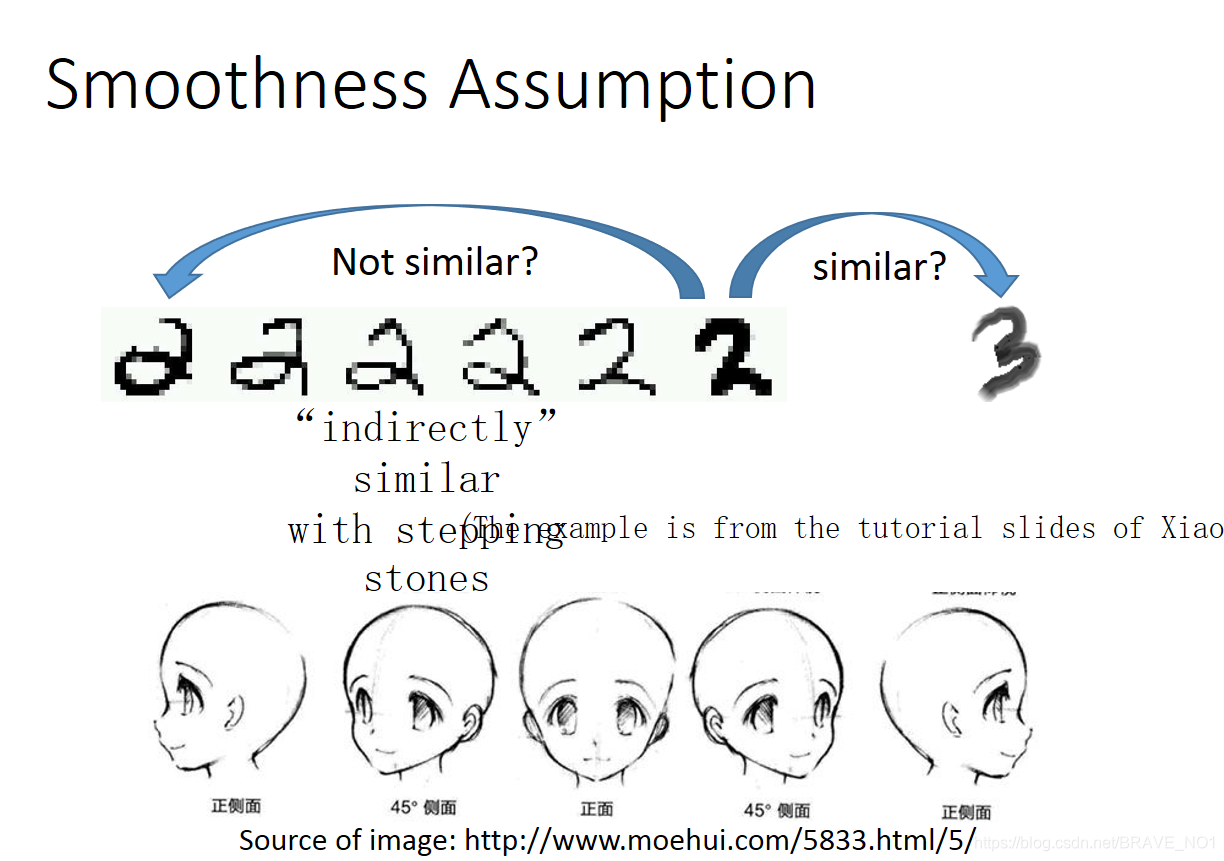
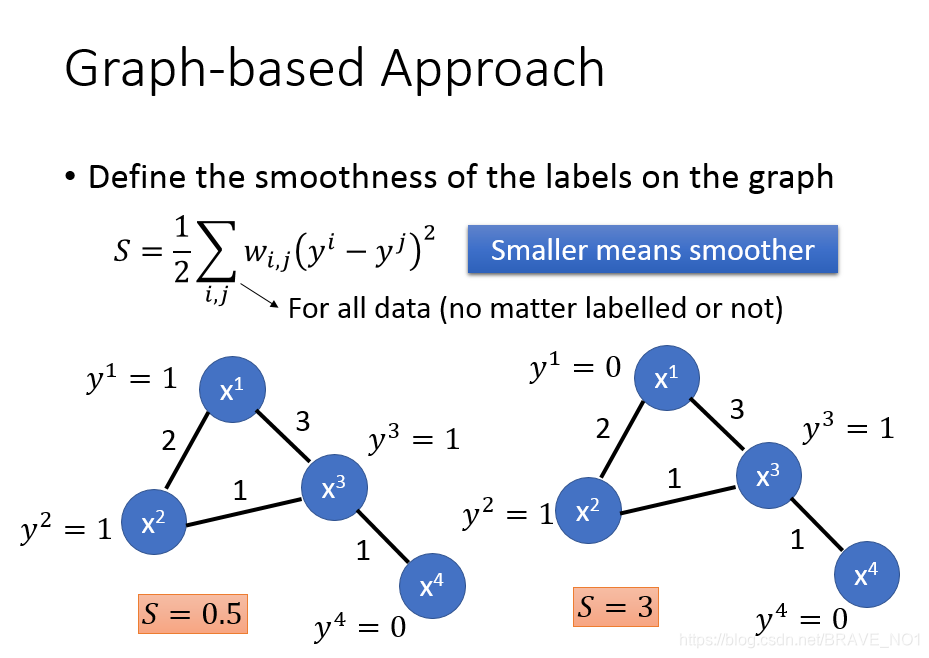
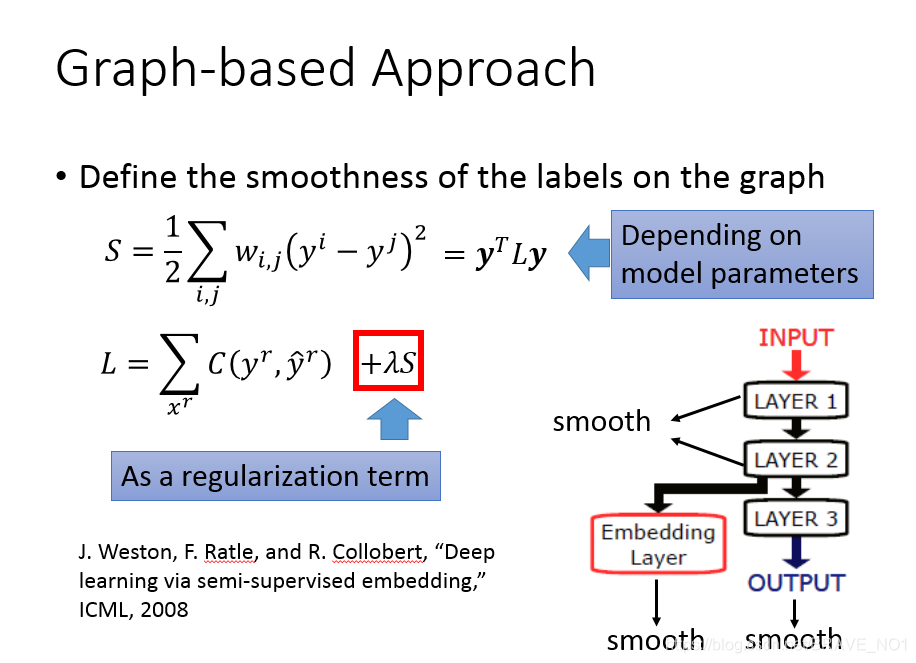
- step1:建立图。首先我们需要定义如何描述点与点之间的相似性 ,也就是如何“加边”的问题。我们可以采用k近邻等办法,也可以采用高斯径向基函数(Gaussian Radial Basis Function): 。在我们的公式中,这里的相似性S记作边的权重W。
- step2:在我们的图中,已经具备标签的类同类之间有边。如果这些点和一个没有标签的点相接,那么我们认为这个没有标签的点可能属于该类。我们定义一个图中标签的smoothness函数S,这个函数值越小越好,可以衡量分类的结果。如下:
向量化:
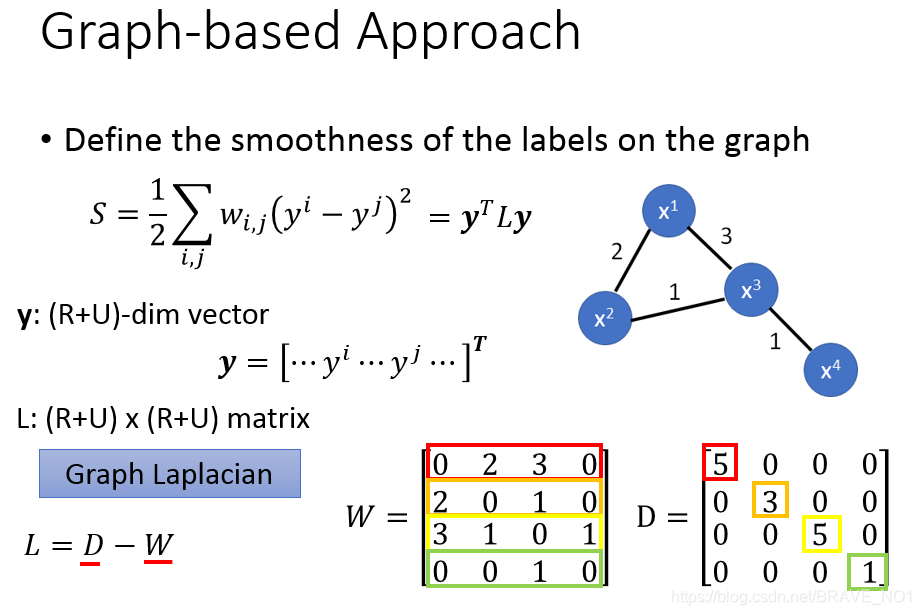
D中,5=2+3,3=2+1,也就是W每行的和作为主对角线元素。 - step3:定义最后的Loss函数,S作为正则项。这个loss总体来说,分为两部份。第一部分是针对有标签的数据,我们用C来衡量(训练标签与真实标签)的差距,第二部分针对无标签数据,用熵来衡量生成的标签。
更好的表示
我们可以从没有标签的数据中获得更好或者更简单的表示。

我们可以发现,武者的战斗虽然是胡子一直在动,并且变化比较多,但是事实上,胡子受到头的操控,并且头的变化比较好表示。所以我们可以用头的变化表示来代替胡子的变化表示。