目录
LeNet
lenet很经典的网络结构,在1998年由大佬LeCun提出,仅仅只有七层网络(对于今天来说肯定是洒洒水蜡)
两层卷积层+两层下采样层(池化层)+三层全连接层:
话说,这不应该算是 5层吗?(应该是带参数的才算,池化层不算进去的吧),怎么是7层网络的,我也不知道怎么回事,有知道的可以告诉我原因吗?
下面是网络的结构图
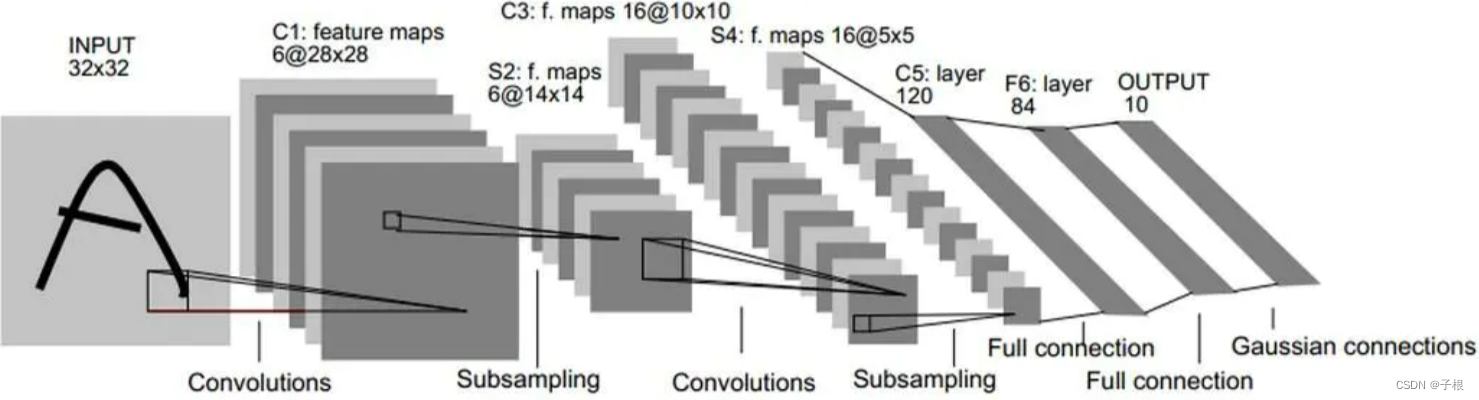
图片截自论文,非本人所有
如果看不清,这里高清无码图:
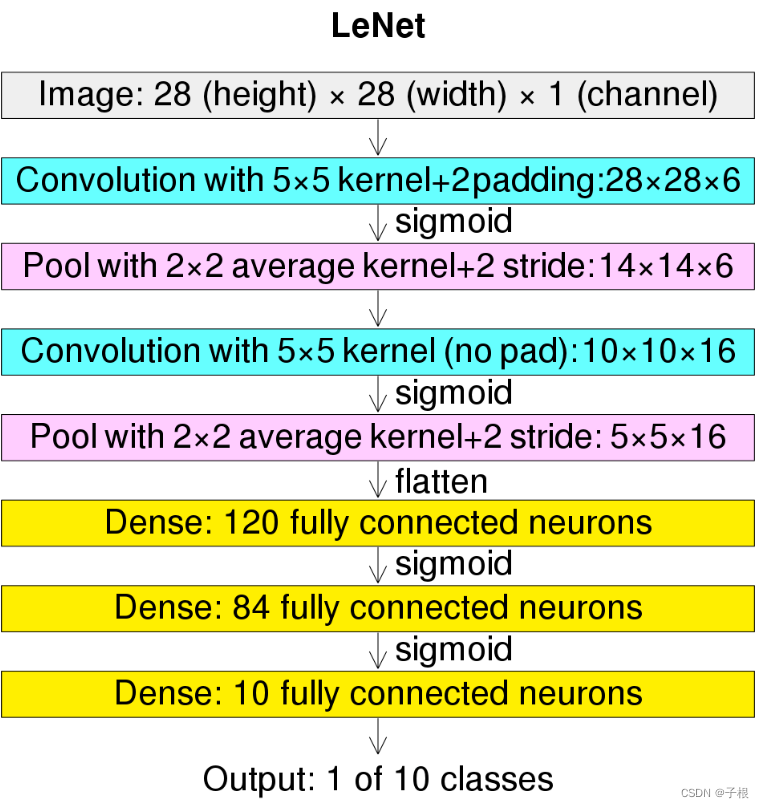
图片截自WIKI,非本人所有
pytorch代码:
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
layer1 = nn.Sequential()
layer1.add_module('conv1', nn.Conv2d(1, 6, 5, 1, 0)) ##28
layer1.add_module('pool1', nn.MaxPool2d(2,2)) ##14
self.layer1 = layer1
layer2 = nn.Sequential()
layer2.add_module('conv2', nn.Conv2d(6, 16, 5, 1, 0)) ##10
layer2.add_module('pool2', nn.MaxPool2d(2, 2)) ##5
self.layer2 = layer2
layer3 = nn.Sequential()
layer3.add_module('fc1', nn.Linear(400, 120))
layer3.add_module('fc2', nn.Linear(120, 84))
layer3.add_module('fc3', nn.Linear(84, 10))
self.layer3 = layer3
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = torch.reshape(x, (x.shape[0], -1))
x = self.layer3(x)
return xAlexNet
AlexNet网络在2012年提出,在ImageNet比赛当中以领先第二名10%精确度的成绩夺得冠军,相对于LeNet,层数更深,同时第一次引入了激活层ReLU,在全连接层引人了Dropout层防止过拟合。

详细图解:

pytorch代码如下:
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 96, 11, 4, 1), #54
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2), #26
nn.Conv2d(96, 256, 5, 1, 2), # 26
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2), # 12
nn.Conv2d(256, 384, 3, 1, 1), # 12
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, 3, 1, 1), # 12
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, 3, 1, 1), # 12
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2) # 5
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256*5*5, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, 10) #10 为分类的数量
)
def forward(self, x):
x = self.features(x)
x = torch.reshape(x, (x.shape[0], -1))
x = self.classifier(x)
return xVggNet
是2014年Image大赛的亚军,层数比AlexNet更深(有16层),卷积核更小,它之所以使用很多小的滤波器、是因为层叠很多小的滤波器的感受野和一个大的滤波器的感受野是相同的,还能减少参数,同时有更深的网络结构。、
网络结构图:
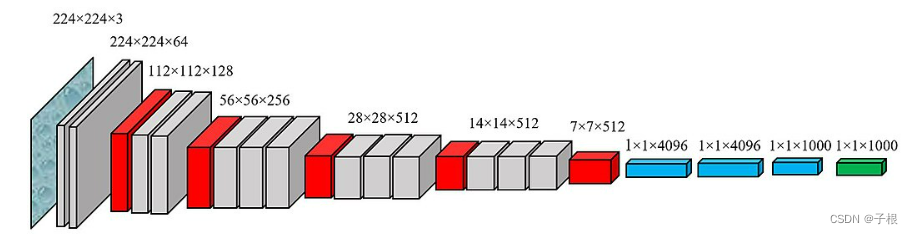
详细图:

pytorch代码:
class VGG(nn.Module):
def __init__(self):
super(VGG, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(1, 64, 3, 1, 1), #224
nn.ReLU(True),
nn.Conv2d(64, 64, 3, 1, 1), #224
nn.ReLU(True),
nn.MaxPool2d(2,2), ##112
nn.Conv2d(64, 128, 3, 1, 1), #112
nn.ReLU(True),
nn.Conv2d(128, 128, 3, 1, 1), #112
nn.ReLU(True),
nn.MaxPool2d(2, 2), ##56
nn.Conv2d(128, 256, 3, 1, 1), # 56
nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), # 56
nn.ReLU(True),
nn.Conv2d(256, 256, 3, 1, 1), # 28
nn.ReLU(True),
nn.MaxPool2d(2, 2), ##28
nn.Conv2d(256, 512, 3, 1, 1), # 28
nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), # 28
nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), # 28
nn.ReLU(True),
nn.MaxPool2d(2,2), # 14
nn.Conv2d(512, 512, 3, 1, 1), # 14
nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), # 14
nn.ReLU(True),
nn.Conv2d(512, 512, 3, 1, 1), # 14
nn.ReLU(True),
nn.MaxPool2d(2, 2), # 7
)
self.clifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 10)
)
def forward(self, x ):
x = self.features(x)
x = torch.reshape(x, (x.shape[0], -1))
x = self.clifier(x)
return xGoogLeNet
GoogLeNet比起VGG网络具有更深的网络结构具有22层(话说,你们怎么这么喜欢比深度呀),在2014年ILSVRC大赛提出,也叫lnceptionN,是谷歌团队为了参加ILSVRC 2014比赛而精心准备的,为了达到最佳的性能,除了使用上述的网络结构外,还做了大量的辅助工作:包括训练多个model求平均、裁剪不同尺度的图像做多次验证等等
GoogLeNet采取了比 VGGNet更深的网络结构,一共有22层,但是它的参数却比AlexNet少了12倍,同时有很高的计算效率,因为它采用了一种很有效的Inception模块,而且它也没有全连接层,因为其去掉了后面的全连接层,所以参数大大减少,同时有了很高的计算效率,是2014年比赛的冠军。
Inception模块设计了一个局部的网络拓扑结构,然后将这些模块堆叠在一起形成一个抽象层网络结构。具体来说就是运用几个并行的滤波器对输入进行卷积和池化,这些滤波器有不同的感受野,最后将输出的结果按深度拼接在一起形成输出层
如下是Inception的图解:4个1*1卷积,1个3*3卷积,1个5*5卷积,1个3*3最大池化
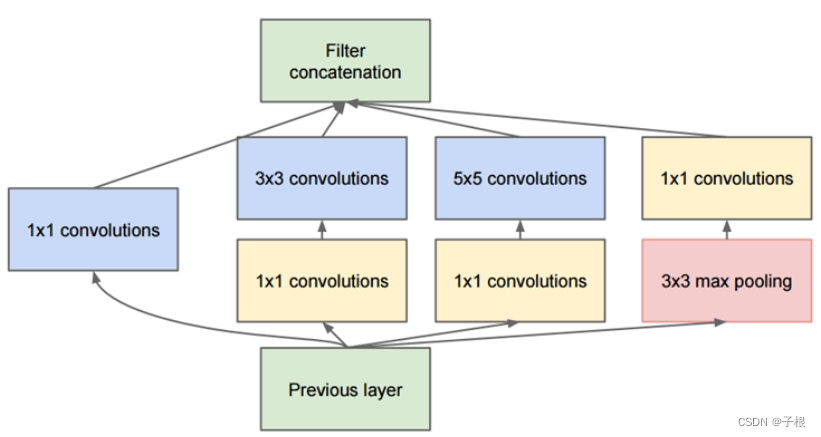
Inception代码:
class BasicConv2d(nn.Module):
def __init__(self,in_channels, out_channels, kernel, stride=1, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels,
kernel_size=kernel, stride=stride, padding=padding,
bias=False)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
'''
in_channels 输入数据的通道
out_channels_1x1 1*1卷积深度
out_channels_1x1_3 3*3前面的1*1卷积深度
out_channels_3x3 3*3卷积深度
out_channels_1x1_5 5*5前面的1*1卷积深度
out_channels_5x5 5*5卷积深度
out_channels_pool 池化后面的1*1卷积深度
'''
class Inception(nn.Module):
def __init__(self, in_channels, out_channels_1x1,
out_channels_1x1_3, out_channels_3x3,
out_channels_1x1_5, out_channels_5x5,
out_channels_pool ):
super(Inception, self).__init__()
##第一条线
self.branch1x1 = BasicConv2d(in_channels, out_channels_1x1, 1)
##第二条线
self.branch3x3 = nn.Sequential(
BasicConv2d(in_channels, out_channels_1x1_3, 1),
BasicConv2d(out_channels_1x1_3, out_channels_3x3, 3, 1, 1)
)
##第三条线
self.branch5x5 = nn.Sequential(
BasicConv2d(in_channels, out_channels_1x1_5, 1),
BasicConv2d(out_channels_1x1_5, out_channels_5x5, 5, 1, 2)
)
##第四条线
self.branch_pool = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, out_channels_pool, 1)
)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3(x)
branch5x5 = self.branch5x5(x)
branch_pool = self.branch_pool(x)
output = [branch1x1, branch3x3, branch5x5, branch_pool]
return torch.cat(output, 1)注意:当卷积核尺寸大小为1时,想让卷积后的大小不变,padding应为=1
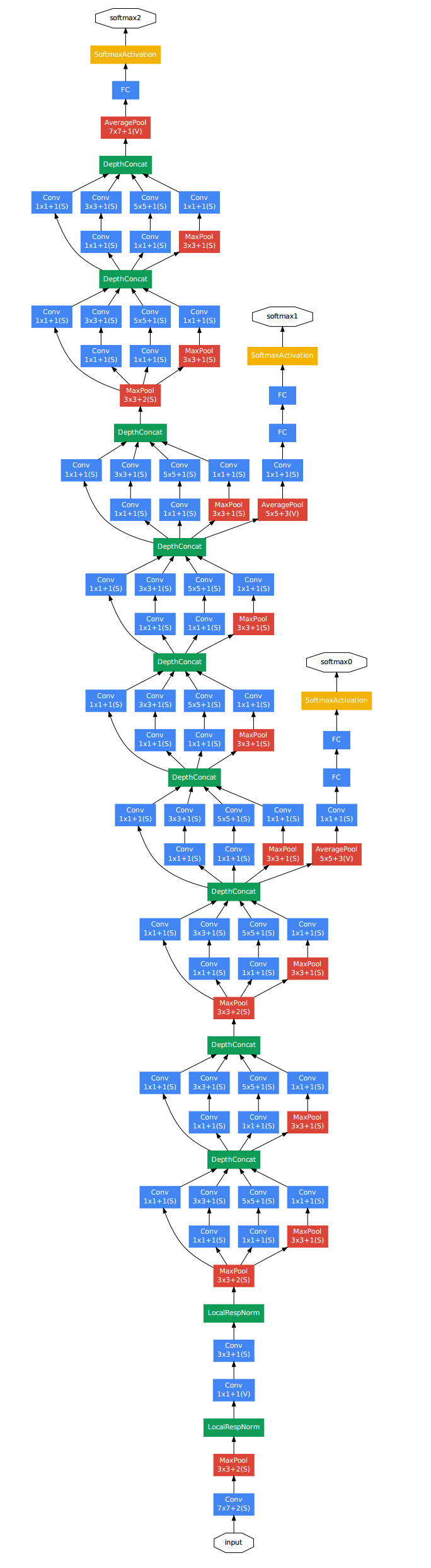
详细表解:
表里右侧上的reduce则是加入的1*1卷积核
这里有几篇篇挺好的博客有详细介绍
完整版pytorch代码:
class BasicConv2d(nn.Module):
def __init__(self,in_channels, out_channels, kernel, stride=1, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels,
kernel_size=kernel, stride=stride, padding=padding,
bias=False)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
'''
in_channels 输入数据的通道
out_channels_1x1 1*1卷积深度
out_channels_1x1_3 3*3前面的1*1卷积深度
out_channels_3x3 3*3卷积深度
out_channels_1x1_5 5*5前面的1*1卷积深度
out_channels_5x5 5*5卷积深度
out_channels_pool 池化后面的1*1卷积深度
'''
class Inception(nn.Module):
def __init__(self, in_channels, out_channels_1x1,
out_channels_1x1_3, out_channels_3x3,
out_channels_1x1_5, out_channels_5x5,
out_channels_pool ):
super(Inception, self).__init__()
##第一条线
self.branch1x1 = BasicConv2d(in_channels, out_channels_1x1, 1)
##第二条线
self.branch3x3 = nn.Sequential(
BasicConv2d(in_channels, out_channels_1x1_3, 1),
BasicConv2d(out_channels_1x1_3, out_channels_3x3, 3, 1, 1)
)
##第三条线
self.branch5x5 = nn.Sequential(
BasicConv2d(in_channels, out_channels_1x1_5, 1),
BasicConv2d(out_channels_1x1_5, out_channels_5x5, 5, 1, 2)
)
##第四条线
self.branch_pool = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels, out_channels_pool, 1)
)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3(x)
branch5x5 = self.branch5x5(x)
branch_pool = self.branch_pool(x)
output = [branch1x1, branch3x3, branch5x5, branch_pool]
return torch.cat(output, 1)
class GoogLeNet(nn.Module):
def __init__(self, in_channels, out_channels):
super(GoogLeNet, self).__init__()
##第 1 个模块
self.block1 = nn.Sequential(
nn.Conv2d(in_channels, 64, 7, 2, 3),
nn.MaxPool2d(3, 2, 1)
)
##第 2 个模块
self.block2 = nn.Sequential(
nn.Conv2d(64, 192, 3, 1, 1),
nn.Conv2d(192, 192, 3, 1, 1),
nn.MaxPool2d(3, 2, 1)
)
##第 3 个模块
self.block3 = nn.Sequential(
Inception(192, 64, 96, 128, 16, 32, 32),
Inception(256, 128, 128, 192, 32, 96, 64),
nn.MaxPool2d(3, 2, 1)
)
##第 4 个模块
self.block4 = nn.Sequential(
Inception(480, 192, 96, 208, 16, 48, 64),
Inception(512, 160, 112, 224, 24, 64, 64), #这里究极体会输出
Inception(512, 128, 128, 256, 24, 64, 64),
Inception(512, 112, 144, 288, 32, 64, 64),
Inception(528, 256, 160, 320, 32, 128, 128), #这里究极体会输出
nn.MaxPool2d(3, 2, 1)
)
##第 4 个模块
self.block5 = nn.Sequential(
Inception(832, 256, 160, 320, 32, 128, 128),
Inception(832, 384, 192, 384, 48, 128, 128),
nn.AvgPool2d(7, 1)
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(1024, out_channels),
# nn.Sigmoid(1024,out_channels)
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = torch.reshape(x, (x.shape[0], -1))
x = self.classifier(x)
return xResNet
ResNet是2015年 ImageNet竞赛的冠军,由微软研究院提出,通过残差模块能够成功地训练高达152层深的神经网络。
其原理就是某个神经网络的输入是x,期望输是H(x),如果直接把输入x传到输出作为初始结果,那么此时需要学习的目标是F(x)= H(x)-x,

residual block的pytorch代码如下:
##如果in_channels == out_channels,则same_shape为TRUE
##如果in_channels != out_channels,则same_shape为FALSE
class BasicBloch(nn.Module):
def __init__(self,in_channels, out_channels, same_shape=True):
super(BasicBloch, self).__init__()
self.same_shape = same_shape
stride = 1 if self.same_shape else 2
self.conv1 = nn.Conv2d(in_channels, out_channels, 3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(True)
self.conv2 = nn.Conv2d(out_channels, out_channels, 3, 1, 1)
self.bn2 = nn.BatchNorm2d(out_channels)
if not self.same_shape:
self.conv3 = nn.Conv2d(in_channels, out_channels, 1, stride=stride)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if not self.same_shape:
x = self.conv3(x)
out += x
out = self.relu(out)
return out网络完整代码
class ResNet(nn.Module):
def __init__(self, in_channel):
super(ResNet, self).__init__()
self.verbose = None
self.block1 = nn.Conv2d(in_channel, 64, 7, 2)
self.block2 = nn.Sequential(
nn.MaxPool2d(3, 2),
BasicBloch(64, 64),
BasicBloch(64, 64)
)
self.block3 = nn.Sequential(
BasicBloch(64, 128, False),
BasicBloch(128, 128)
)
self.block4 = nn.Sequential(
BasicBloch(128, 256, False),
BasicBloch(256, 256)
)
self.block5 = nn.Sequential(
BasicBloch(256, 512, False),
BasicBloch(512, 512),
nn.AvgPool2d(3)
)
self.classifier = nn.Linear(2048, 10)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = x.view(x.shape[0], -1)
x = self.classifier(x)
return xUnet
unet网络其实是FCN(全卷积网络)变过来的,是像素分割型网络。
深度卷积网络擅长处理分类问题,将图片卷积得到的特征,也就说由输入多(图片像素)得到输出少(分类的概率),然后分类。但是分割的话,是原图片大小输入,输出也是原大小才对的。所以对此,我们转化思维对像素进行分类的话,就能得到输出后的分割图片了。所以说到底语义分割还是分类问题
下面是Unet的网络结构
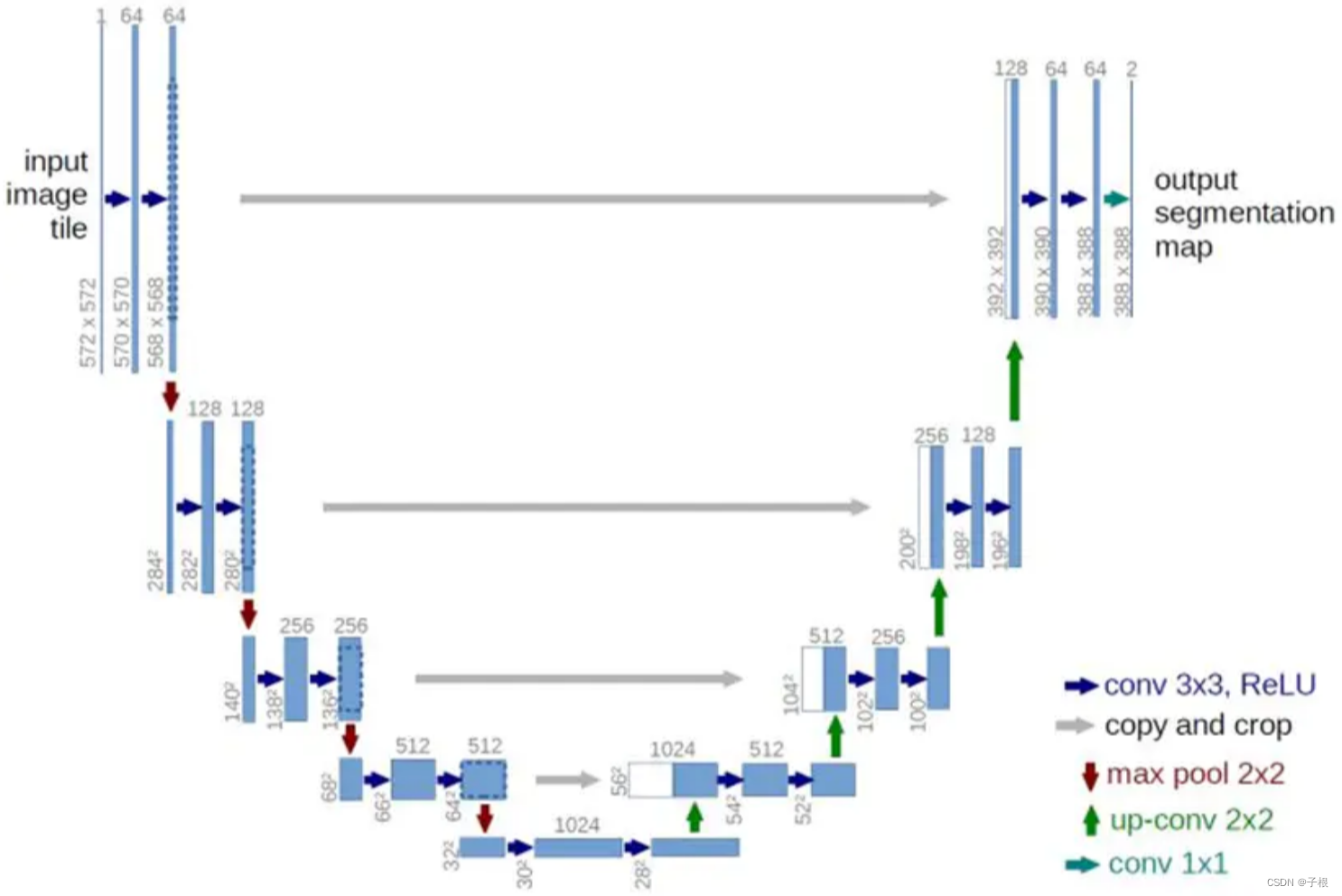
网络结构的代码:
import torch
import torch.nn as nn
from torch.nn import functional as F
class conv(nn.Module):
def __init__(self, c_in, c_out):
super(conv, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(c_in, c_out, 3, 1, 1),
nn.BatchNorm2d(c_out),
# 防止过拟合
nn.Dropout(0.3),
nn.LeakyReLU(),
nn.Conv2d(c_out, c_out, 3, 1, 1),
nn.BatchNorm2d(c_out),
# 防止过拟合
nn.Dropout(0.3),
nn.LeakyReLU(),
)
def forward(self, x):
return self.layer(x)
## 下采样
class DownSampling(nn.Module):
def __init__(self, channel):
super(DownSampling, self).__init__()
self.Done = nn.Sequential(
nn.Conv2d(channel, channel, 3, 2, 1)
)
def forward(self, x):
return self.Done(x)
class UpSampling(nn.Module):
def __init__(self, channel):
super(UpSampling, self).__init__()
self.up = nn.Conv2d(channel, channel//2, 1, 1)
self.conv_tf = nn.ConvTranspose2d(channel//2, channel//2, 4, 2, 1)
def forward(self, x, r):
x = self.up(x)
# x = F.interpolate(x, scale_factor=2, mode="nearest")
x = self.conv_tf(x)
return torch.cat((x, r), 1) ## 只是通道相加
class Unet(nn.Module):
def __init__(self):
super(Unet, self).__init__()
# self.c1 = nn.Conv2d(3, 64, 3, 1, 1)
self.layer1 = conv(3, 64)
self.layer2 = nn.Sequential(
DownSampling(64),
conv(64, 128),
)
self.layer3 = nn.Sequential(
DownSampling(128),
conv(128, 256),
)
self.layer4 = nn.Sequential(
DownSampling(256),
conv(256, 512),
)
self.layer5 = nn.Sequential(
DownSampling(512),
conv(512, 1024),
)
self.layer6 = nn.Sequential(
DownSampling(1024),
conv(1024, 2048),
)
self.layer_up_1 = UpSampling(2048)
self.c1 = conv(2048, 1024)
self.layer_up_2 = UpSampling(1024)
self.c2 = conv(1024, 512)
self.layer_up_3 = UpSampling(512)
self.c3 = conv(512, 256)
self.layer_up_4 = UpSampling(256)
self.c4 = conv(256, 128)
self.layer_up_5 = UpSampling(128)
self.c5 = conv(128, 64)
self.layer_up_6 = nn.Sequential(
nn.Conv2d(64, 3, 3, 1, 1),
nn.Sigmoid()
)Unet++
这是Unet++的结构
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, middle_channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(middle_channels)
self.conv2 = nn.Conv2d(middle_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return out
class NestedUNet(nn.Module):
def __init__(self, num_classes, input_channels=3, deep_supervision=False, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
print('input:',input.shape)
x0_0 = self.conv0_0(input)
print('x0_0:',x0_0.shape)
x1_0 = self.conv1_0(self.pool(x0_0))
print('x1_0:',x1_0.shape)
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1))
print('x0_1:',x0_1.shape)
x2_0 = self.conv2_0(self.pool(x1_0))
print('x2_0:',x2_0.shape)
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1))
print('x1_1:',x1_1.shape)
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1))
print('x0_2:',x0_2.shape)
x3_0 = self.conv3_0(self.pool(x2_0))
print('x3_0:',x3_0.shape)
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], 1))
print('x2_1:',x2_1.shape)
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], 1))
print('x1_2:',x1_2.shape)
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1))
print('x0_3:',x0_3.shape)
x4_0 = self.conv4_0(self.pool(x3_0))
print('x4_0:',x4_0.shape)
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
print('x3_1:',x3_1.shape)
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], 1))
print('x2_2:',x2_2.shape)
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], 1))
print('x1_3:',x1_3.shape)
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1))
print('x0_4:',x0_4.shape)
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output最后,老婆压场
喜欢的话,给我老婆点个赞吧☺
