目录
动态规划怎么学?
学习一个算法没有捷径,更何况是学习动态规划,
跟我一起刷动态规划算法题,一起学会动态规划!
1. 题目解析
题目链接:剑指 Offer 47. 礼物的最大价值 - 力扣(Leetcode)
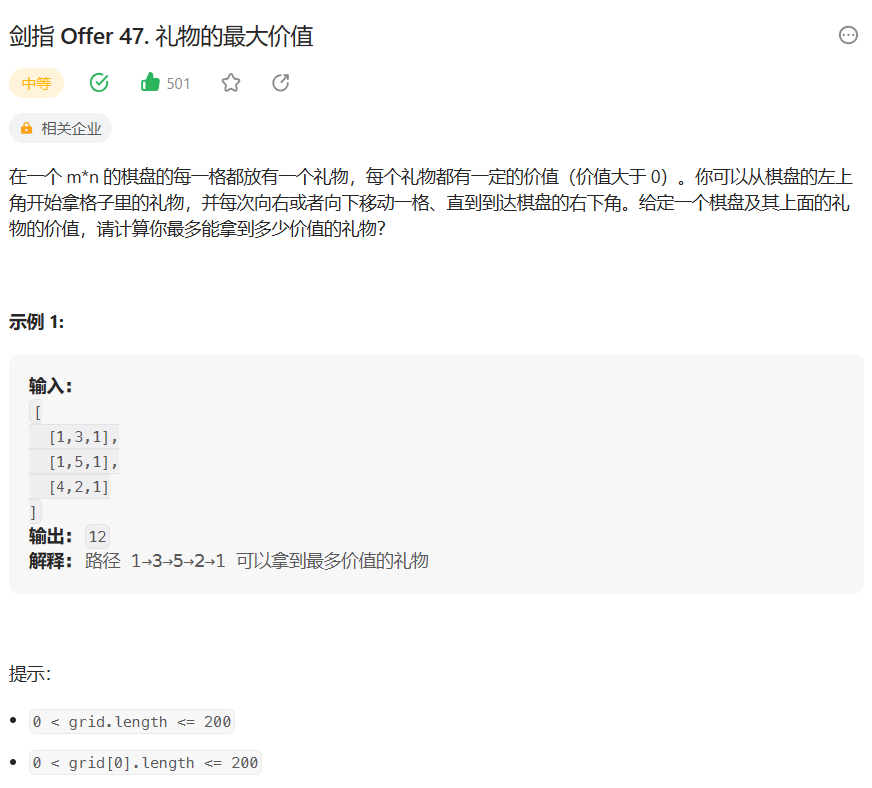
题目不难理解:总结来讲就是从左上角开始拿礼物,
只能往右或者往下找,在右下角结束,返回最大的礼物价值即可。
2. 算法原理
1. 状态表示
dp[ i ][ j ] 表示:到达[ i,j ]位置的时候,此时的最大价值
2. 状态转移方程
dp[ i ][ j ]有两种情况:
第一种是从上面来的礼物最大价值:dp[ i ][ j ] = dp[ i - 1 ][ j ] + g[ i ][ j ]
第二种是从左面来的礼物最大价值:dp[ i ][ j ] = dp[ i ][ j - 1 ] + g[ i ][ j ]
所以得出状态表达式:
dp[ i ][ j ] = max( dp[ i ][ j - 1 ],dp[ i - 1 ][ j ] ) + g[ i ][ j ]
3. 初始化
初始化的话,其实就是为了防止越界,
所以我们多创建一行和一列即可。
4. 填表顺序
从左往右,从上往下。
5. 返回值
根据题目要求,我们直接返回右下角的值就行。
3. 代码编写
class Solution {
public:
int maxValue(vector<vector<int>>& grid) {
int m = grid.size(), n = grid[0].size();
vector<vector<int>> dp(m + 1, vector<int>(n + 1));
for(int i = 1; i <= m; i++) {
for(int j = 1; j <= n; j++) {
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1]) + grid[i - 1][j - 1];
}
}
return dp[m][n];
}
};写在最后:
以上就是本篇文章的内容了,感谢你的阅读。
如果感到有所收获的话可以给博主点一个赞哦。
如果文章内容有遗漏或者错误的地方欢迎私信博主或者在评论区指出~