一、 Collection
1、 List
a、 ArrayList
b、 Vector
c、 LinkedList
首先要对List的三种实现进行一个简单的异同比较:
同:
*ArrayList和Vector都可以看做是一个可变的数组;
*ArrayList和LinkedList都属于线程不安全的类型;
*但是ArrayList和LinkedList都可以通过调用Colletions类里的SynchronizedList()来进行ArrayList和LinkedList的调用来保证线程的安全性;
异:
*ArrayList和Vector虽然都可以看做是一个可变的数组,但是Vector类中大部分函数都包含了Synchronized关键字保证了线程的安全性;
*ArrayList和LinkedList虽然都属于线程不安全的类型,但是LinkedList实际上是一种双向链表的存储集合,而ArrayList实际上是数组;
*ArrayList和Vector因为都是可变的数组,所以在数据查找上的效率是跟数组差不多,因为数组存储过程中会有明确的下表同时保存起来所以相对速度会更快一些,但是在数据插入的时候,在数组中插入数据实际上是牵扯到了内存的调动所以在数据插入时是相对较慢的,而Vector因为大部分方法都考虑了线程安全的问题,所以效率相对ArrayList更加缓慢一些;
*LinkedList因为是双向链表方式,所以实际上是通过<Node>节点来进行数据的存储的,并在存储一个节点的同时,记录它的前一个及后一个节点,并且在集合中标识出了首节点first和终节点last。所以在数据添加的时候实际上只要在对应节点添加指向并记录前后节点即可,在效率上远远高于ArrayList,但是在查询是,当LinkedList需要查询某一个下标的节点数据时,需要遍历整个集合,计算相对应的下标才可以查询出来,所以LinkedList的查询相对更加缓慢一些。
ArrayList的add方法表明是数组添加:
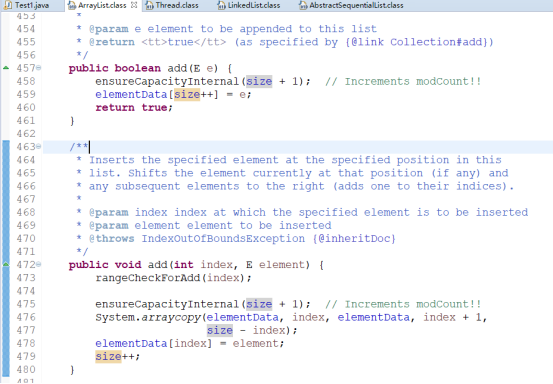
Vector的函数实现,表明是线程安全的:
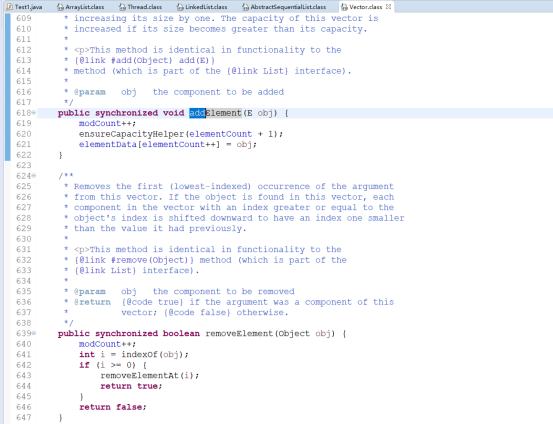
LinkedList源码展示,表现是双向链表:
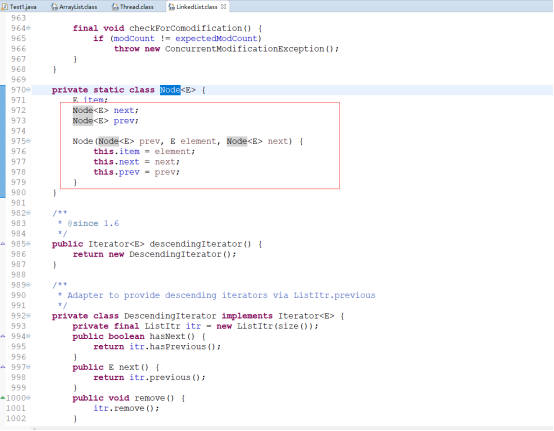
代码展示ArrayList和LinkedList插入和查询效率比较:
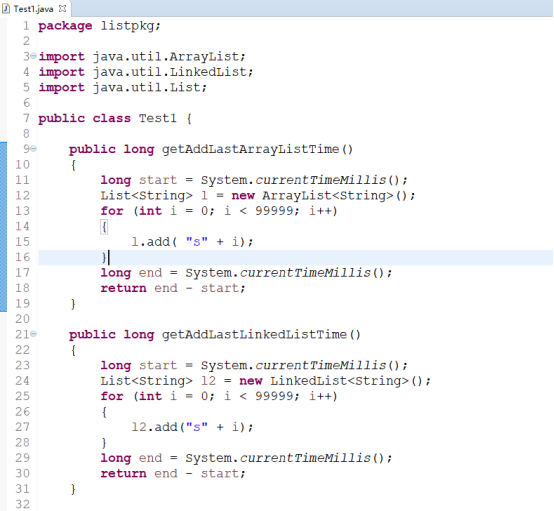
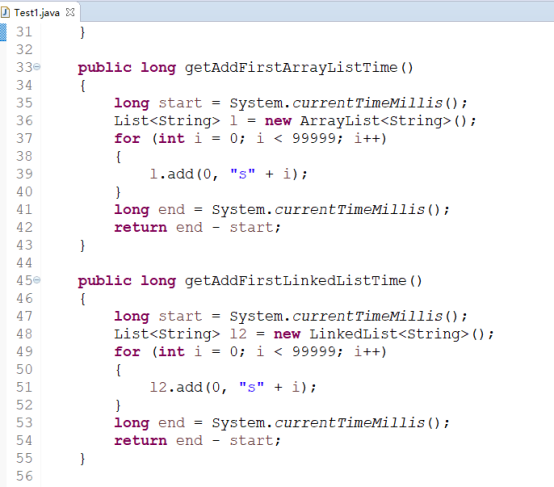
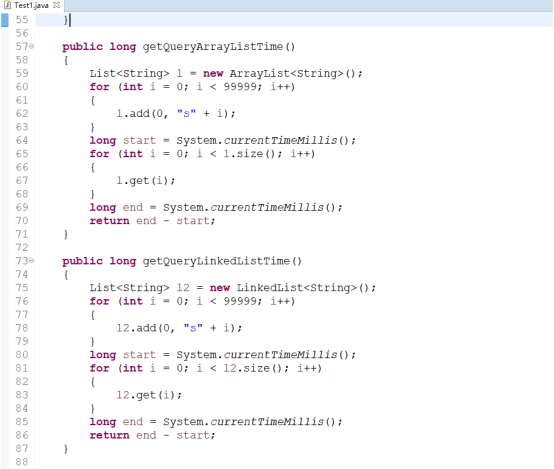

输出结果为:

这个结果有没有很惊讶呢?
2、 Set
a、 HashSet
b、 TreeSet
简单分析一下HashSet和TreeSet的异同
同:
*都是基于Map来进行数据的存储的
*都是线程不同步的
*都不能存储重复数据(因为都是通过Map的key值进行数据存储的,所以不允许存在重复数据)
*都只能通过Iterator来进行遍历
异:
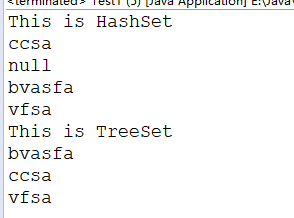
*HashSet是一个无序的集合,TreeSet是一个有序的集合,并且可根据自然排序或者TreeSet创建时的Comparator进行排序;
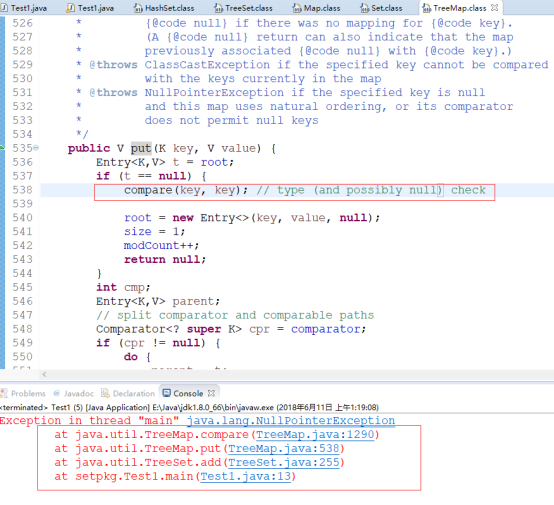
*HashSet可以存储Null,TreeSet不允许存储Null(因为需要compareTo函数,Null值无法比较,所以会抛空指针异常)
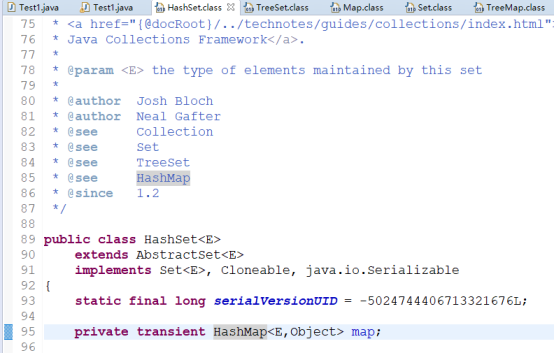
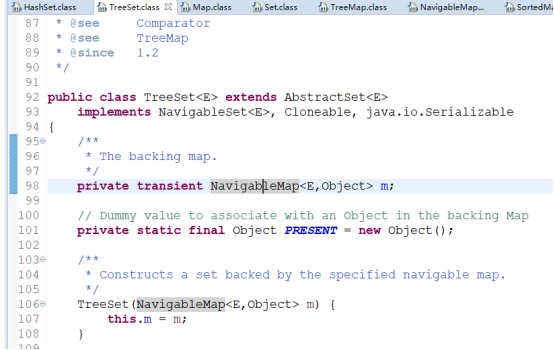
*HashSet是基于HashMap实现的,TreeSet是基于TreeMap实现的
HashSet基本源码及相关继承:
TreeSet基本源码及相关继承:
TreeSet,add null时源码跟踪:
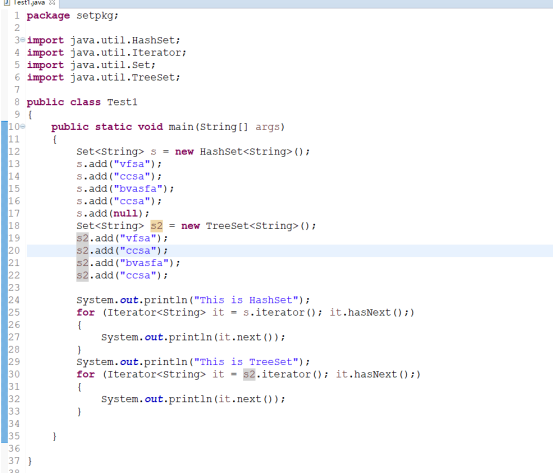
HashSet及TreeSet的基本遍历:
输出结果为:
二、 Map
以下等多种map的实现类,主要有一下共同点就是,实现了Map接口,并且都是通过Key-Value键值对形式存储数据。接下来单独说一下他们各自的特点
1、 Hashtable
首先Hashtable继承于Dictionary,实现了Map、Cloneable、Serializable接口,并且其中大部分方法都是通过synchronized关键字修饰意味着,Hashtable是线程同步的。
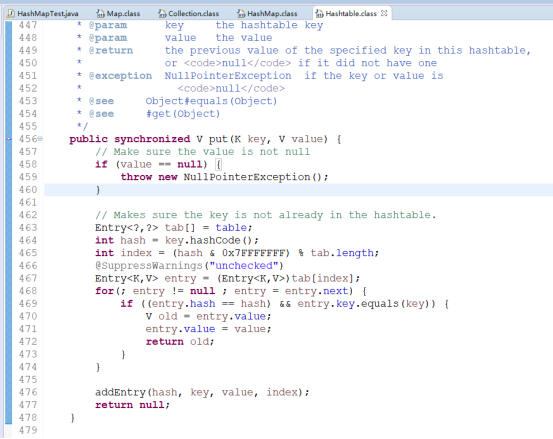
并且Hashtable的key-value值都不可以存储null值因为在put函数中,校验了value如果为null直接抛空指针,并且需要计算key值的hashcode值,所以hashtable是不允许存储null的,并且其实Hashtable也是通过Entry<K, V>对象的数组来进行数据存储的:
2、 HashMap
首先HashMap继承于AbstractMap,实现了Map、Cloneable、Serializable接口,但是hashMap并不是线程同步的,当然从另一种角度来说,HashMap的效率就要高于Hashtable了。
其次HashMap并不禁止key-value值存储null值,因为其实Map也是通过node节点进行参数存储的,如下代码:
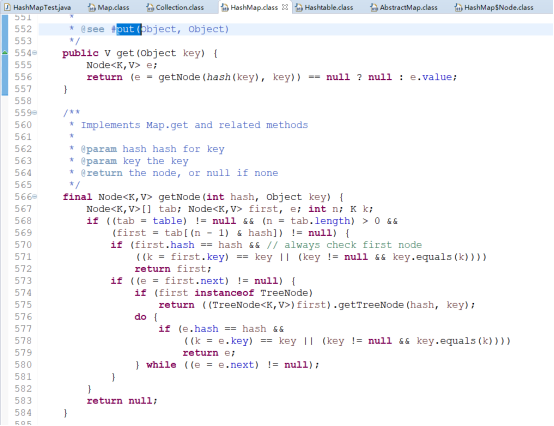
另外,HashMap的存储方式其实类似excel一样的空间,在HashMap的存储空间中就是一列列小格子,每一列都代表着一个hash值,我们在将参数存储至HashMap后,在我们需要查找的时候,我们会先根据key值的hash值快速定位出那一列,然后通过equals方法快速定位出我们需要的键值对。另外需要补充说明的一点是HashMap使用的是散列算法,会尽量分散key值得hash值范围,以此保证尽量在‘同一列’不会保存过多的键值对。
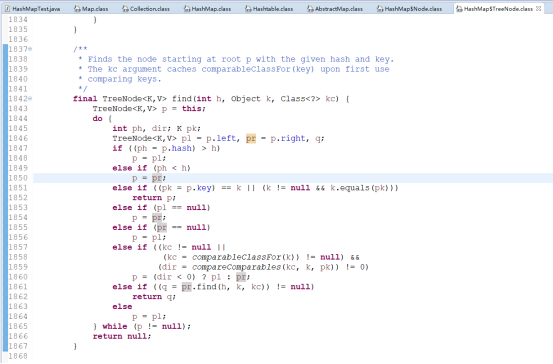
源码有兴趣可以跟一下HashMap的get方法,最底层是一个find的递归函数:
3、 TreeMap
首先TreeMap继承于AbstractMap,实现了NavigableMap、Cloneable、Serializable接口,但是TreeMap并不是线程同步的,但是TreeMap是有序的。
另外需要说明一下的是TreeMap的key值是不允许存储null的,因为在TreeMap的存储过程中是需要通过key值调用compare方法来进行一个比较排序的,所以在TreeMap存储的过程中如果key值为null是会报空指针异常的。
还有一点要注意的是TreeMap和HashTable一样是通过Entry<K, V>对象来存储数据的,但是和Hashtable不一样的是,TreeMap的存储方式更接近与一个树装链表一样的存在,在存储一个Entry节点的过程中还会将这个Entry节点的左右及父节点一起保存下来。
如图,PS:如果需要更详细的了解TreeMap的相关实现方式可以查询一下红黑树,因为TreeMap就是基于红黑树(Red-Black tree)实现的。
4、 WeakHashMap
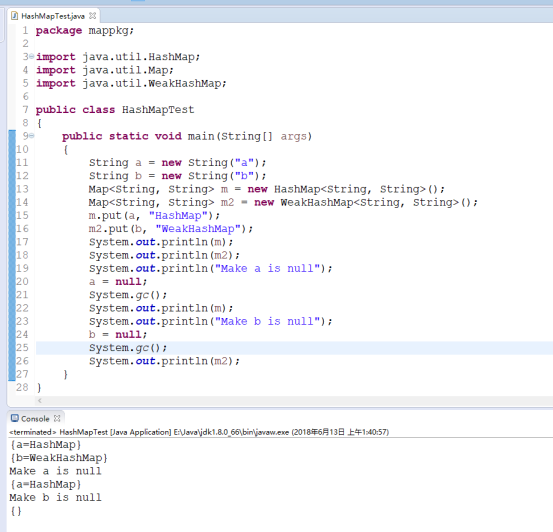
基本功能与HashMap相同,与HashMap最核心的不同即WeakHashMap是一个弱键值对,意思大致解释说当WeakHashMap的key值失去引用时,当发生了java的垃圾回收时,WeakHashMap的对应键值对会被清除:
5、 简单展示一些HashMap、Hashtable的遍历方式
a、 HashMap的遍历:
HashMap与TreeMap、WeakHashMap一样都有以下四种遍历方式:
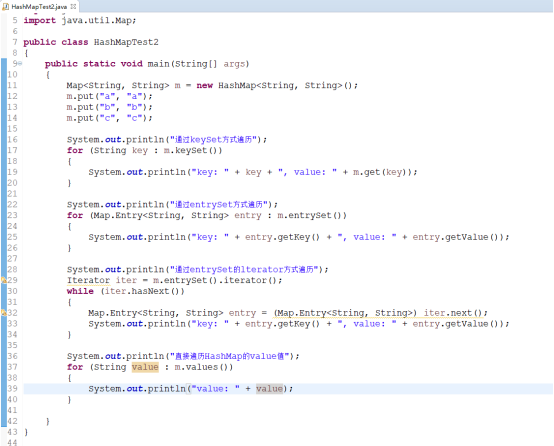
输出结果如下:

PS: HashMap的keySet也可以通过iterator方式遍历就不在此展示了。
b、 Hashtable的遍历:
Hashtable除了和HashMap同样的四种遍历方式外,还有一种相对独有的遍历方式接下来进行展示一下:
代码依然是照片,手敲有益身心健康,没事还是可以多读一读jdk源码有很多值得学习的地方