Java集合框架概述
概览
Java 集合框架存放于 Java.util 包中,其主要包括两种类型的容器,一种是集合(Collection),存储一个集合元素,另一种是图(Map),存储键值对映射。Collection 又有三种子类型,List,Set,Queue, 再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
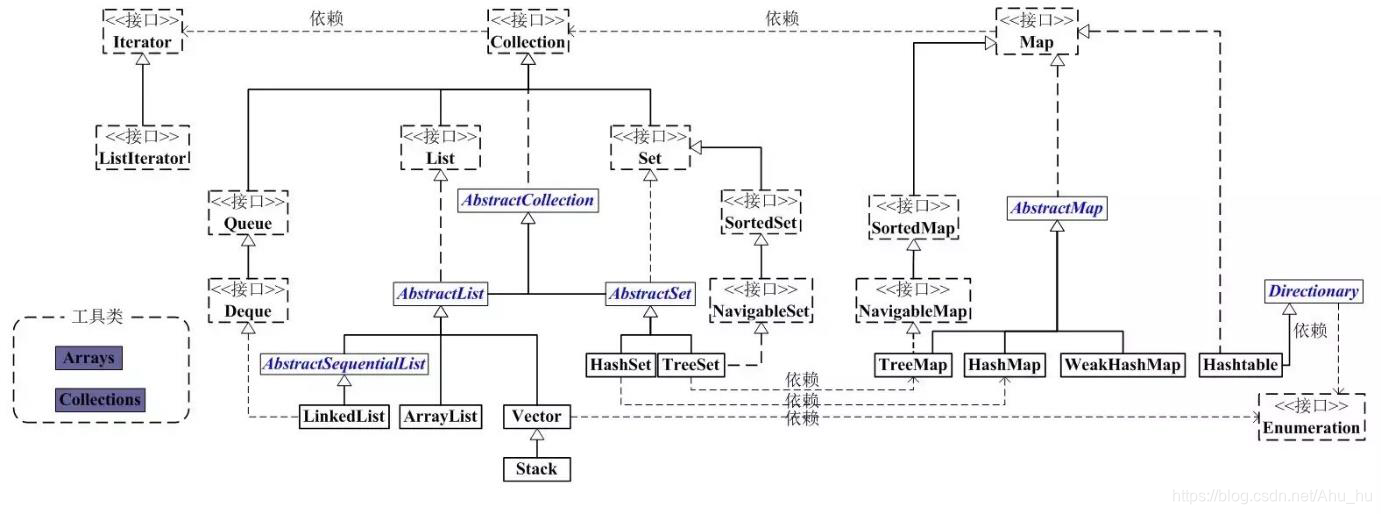
List、Set、Map 三者区别
-
List:存储元素有序,可重复。
具体类包括:ArrayList,Vector,LinkedList(双向链表)。
-
Set:存储元素无序,不可重复。
具体类包括:HashSet(基于HashMap实现),TreeSet(红黑树:自平衡的排序二叉树)。
-
Map:使用键值对(key - value)来存储数据,kessy 是无序的,不可重复;value是无序的,可重复。每个key映射一个value。
具体类包括:
-
HashMap( JDK1.8 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间 )
-
HashTable( 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的 )
-
TreeMap( 红黑树:自平衡的排序二叉树)
-
Iterator 迭代器
Iterator 对象称为迭代器,是设计模式的一种, 迭代器可以对集合进行遍历,但每一个集合内部的数据结构可能是不尽相同的,所以每一个集合存和取都很可能是不一样的,虽然我们可以人为地在每一个类中定义 hasNext() 和 next() 方法,但这样做会让整个集合体系过于臃肿。于是就有了迭代器。
迭代器的定义为:提供一种方法访问一个容器对象中各个元素,而又不需要暴露该对象的内部细节。
public interface Iterator<E> {
/**
* Returns {@code true} if the iteration has more elements.
* (In other words, returns {@code true} if {@link #next} would
* return an element rather than throwing an exception.)
*
* @return {@code true} if the iteration has more elements
*/
boolean hasNext();
/**
* Returns the next element in the iteration.
*
* @return the next element in the iteration
* @throws NoSuchElementException if the iteration has no more elements
*/
E next();
......
}
Iterator 主要是用来遍历集合,特点是更加安全,因为在当前遍历的集合元素被更改时,Iterator 会抛出 ConcurrentModificationException异常。
使用方法:
Map<Integer, String> map = new HashMap();
map.put(1, "LESS");
map.put(2, "IS");
map.put(3, "MORE.");
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
while (iterator.hasNext()) {
Map.Entry<Integer, String> entry = iterator.next();
System.out.println(entry.getKey() + entry.getValue());
}
线程安全集合
早期线程安全集合包括:Vector,HashTable,它们几乎给所有public方法都加上了synchronized关键字, 由于加锁导致性能降低,在不需要并发访问同一对象时,这种强制性的同步机制就显得多余,所以它们都因为性能原因被弃用了。
Vector和HashTable被弃用后,它们被ArrayList和HashMap代替,但它们不是线程安全的,所以Collections工具类中提供了相应的包装方法把它们包装成线程安全的集合。
List<Integer> synchronizedList = Collections.synchronizedList(new ArrayList<Integer>());
Set<Integer> synchronizedSet = Collections.synchronizedSet(new HashSet<Integer>());
Map<Integer, String> synchronizedMap = Collections.synchronizedMap(new HashMap<Integer, String>());
...
Collections针对每种集合都声明了一个线程安全的包装类,在原集合的基础上添加了锁对象,集合中的每个方法都通过这个锁对象实现同步 。
java.util.concurrent包中的集合提供了很多线程安全的并发容器: ConcurrentHashMap, CopyOnWriteArrayList, ConcurrentLinkedQueue, BlockingQueue, ConcurrentSkipListMap。
List
List一共有三个实现类组成:ArrayList,LinkedList和Vector。
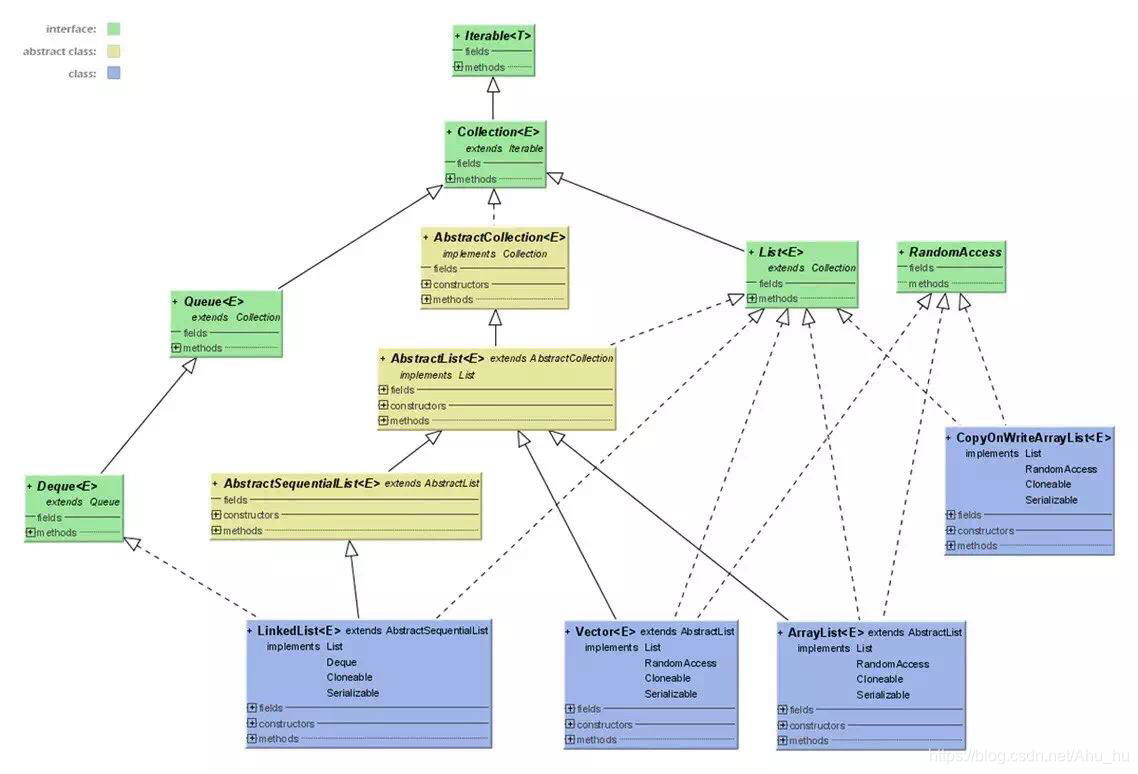
ArrayList
是最常用的List实现类,内部由数组实现(object[]),允许对元素的快速随机访问。但当数组大小不满足增加新元素时,需要对数组进行扩容,将数组中已有元素复制到新的存储空间中。由于数组的特点,对ArrayList的中间位置进行增删元素时,要对数组进行移动,代价较高。所以 ArrayList 适合随即查找和遍历,不适合插入和删除。
Vector
与 ArrayList 一样,vector 是由数组实现的,不同的是vector是线程安全的,支持线程同步,即某一时刻只能有一个线程对其读写,同时也降低了vector的效率。
LinkedList
底层采用双向链表数据结构,很适合数据的动态插入和删除。对于要在指定位置增删元素,时间复杂度近似为O(n),LinkedList 不支持高效的随机元素访问。
ArrayList 扩容机制
//下面是ArrayList的扩容机制
//ArrayList的扩容机制提高了性能,如果每次只扩充一个,
//那么频繁的插入会导致频繁的拷贝,降低性能,而ArrayList的扩容机制避免了这种情况。
/**
* 如有必要,增加此ArrayList实例的容量,以确保它至少能容纳元素的数量
* @param minCapacity 所需的最小容量
*/
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 获取默认的容量和传入参数的较大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
//判断是否需要扩容,上面两个方法都要调用
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 如果说minCapacity也就是所需的最小容量大于保存ArrayList数据的数组的长度的话,就需要调用grow(minCapacity)方法扩容。
//这个minCapacity到底为多少呢?举个例子在添加元素(add)方法中这个minCapacity的大小就为现在数组的长度加1
if (minCapacity - elementData.length > 0)
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
/**
* ArrayList扩容的核心方法。
*/
private void grow(int minCapacity) {
//elementData为保存ArrayList数据的数组
///elementData.length求数组长度elementData.size是求数组中的元素个数
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//再检查新容量是否超出了ArrayList所定义的最大容量,
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
参考:https://juejin.im/post/5c66c47851882562e5443491
https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList.md
Set
Set 存储的元素是无序且独一无二的。对象相等的本质是对象的hashcode(根据对象的内存地址计算出来的序号值)相等,要想让两个不同的对象视为相等的话,必须覆盖Object的hashcode方法和equal方法。
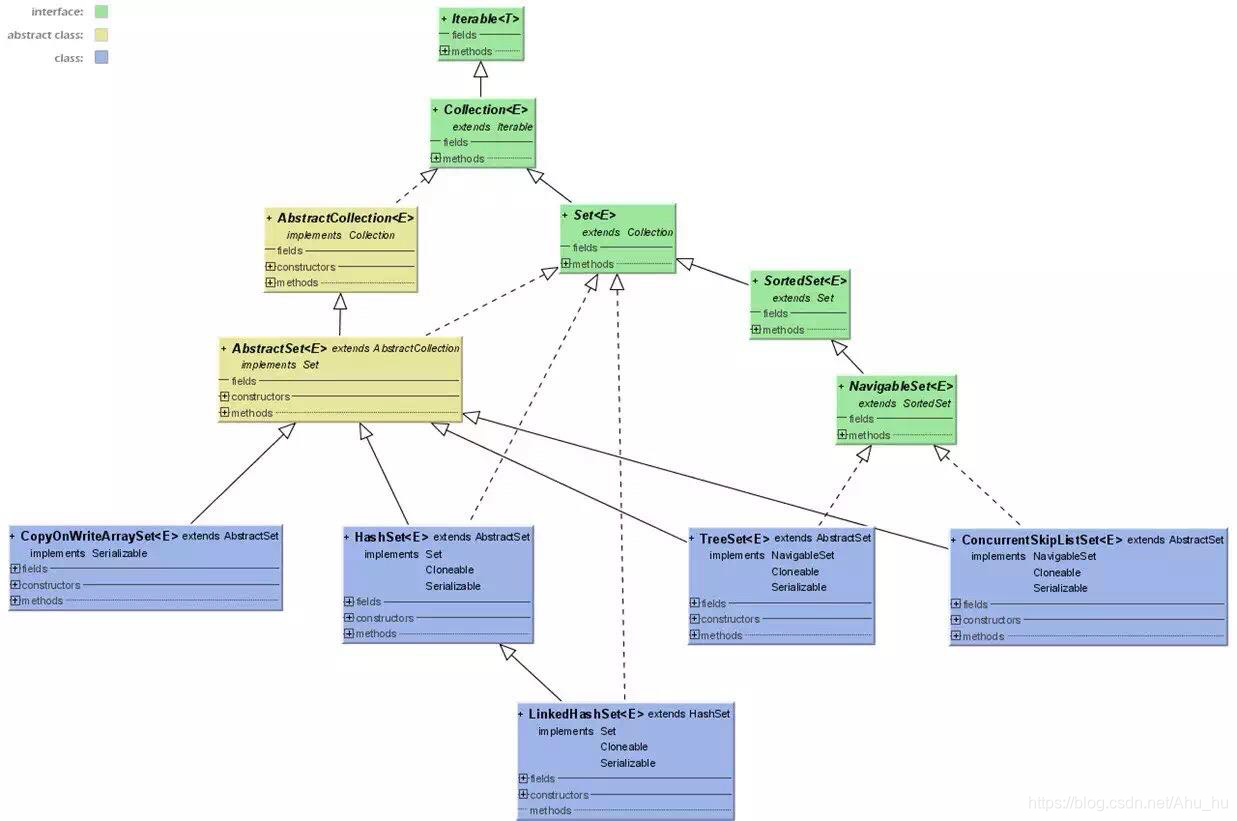
HashSet
HashSet 实现Set接口,底层是由HashMap实现的,为哈希表结构 。
在向HashSet添加元素时,有下面的源码可知,add()调用了HashMap的put()。 在向HashMap中添加元素时,先判断key的hashCode值是否相同,如果相同,则调用equals()、==进行判断,若相同则覆盖原有元素;如果不同,则直接向Map中添加元素;
// HashSet
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
// HashMap
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
HashSet 有以下特点:不允许出现重复元素;允许插入null;元素无序(添加元素和遍历元素顺序不一致);线程不安全。
TreeSet
与HashSet集合类似,TreeSet也是基于Map来实现,具体实现TreeMap,其底层结构为红黑树(特殊的二叉查找树);
TreeSet有以下特点: 对插入的元素进行排序,是一个有序的集合(主要与HashSet的区别); 底层使用的时红黑树结构;允许插入null值;不允许插入重复元素;线程不安全。
TreeSet具有排序功能,分为自然排序(123456)和自定义排序两类,默认是自然排序;在程序中,我们可以按照任意顺序将元素插入到集合中,等到遍历时TreeSet会按照一定顺序输出–倒序或者升序;
自然排序容易实现,只要实例化一个TreeSet对象,添加元素,使用toString方法输出即为升序排列。那如何实现自定义排序呢?
Comparator 定制排序和重写 compareTo 方法实现排序
comparable接口实际上是出自java.lang包 它有一个compareTo(Object obj)方法用来排序comparator接口实际上是出自 java.util 包它有一个compare(Object obj1, Object obj2)方法用来排序
一般我们需要对一个集合使用自定义排序时,我们就要重写compareTo()方法或compare()方法,当我们需要对某一个集合实现两种排序方式,比如一个 song 对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写compareTo()方法和使用自制的Comparator方法或者以两个 Comparator 来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的 Collections.sort()。
- 重写compareTo方法
/* person对象没有实现Comparable接口,所以必须实现,这样才不会出错,才可以使treemap中的数据按顺序排列前面一个例子的String类已经默认实现了Comparable接口,详细可以查看String类的API文档,另外其他像Integer类等都已经实现了Comparable接口,所以不需要另外实现了*/
public class Person implements Comparable<Person> {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
/**
* T重写compareTo方法实现按年龄来排序
*/
@Override
public int compareTo(Person o) {
if(this.age > o.getAge()){
return 1;
}
if(this.age < o.getAge()){
return -1;
}
return 0;
}
- Comparator 定制排序
//自定义App类的比较器:
public class AppComparator implements Comparator<App> {
//比较方法:先比较年龄,年龄若相同在比较名字长度;
public int compare(App app1, App app2) {
int num = app1.getAge() - app2.getAge();
return num == 0 ? app1.getName().length() - app2.getName().length() : num;
}
}
// 此时,App不用在实现Comparerable接口了,单纯的定义一个类即可;
public class App{
private String name;
private Integer age;
public App(){}
public App(String name,Integer age){
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public static void main(String[] args ){
System.out.println( "Hello World!" );
}
}
public class TreeSetTest {
public static void main(String[] agrs){
customComparatorSort();
}
//自定义比较器:升序
public static void customComparatorSort(){
TreeSet<App> treeSet = new TreeSet<App>(new AppComparator());
//排序对象:
App app1 = new App("hello",10);
App app2 = new App("world",20);
App app3 = new App("my",15);
App app4 = new App("name",25);
//添加到集合:
treeSet.add(app1);
treeSet.add(app2);
treeSet.add(app3);
treeSet.add(app4);
System.out.println("TreeSet集合顺序为:"+treeSet);
}
}
LinkedHashSet
LinkedHashSet = HashSet + LinkedHashMap
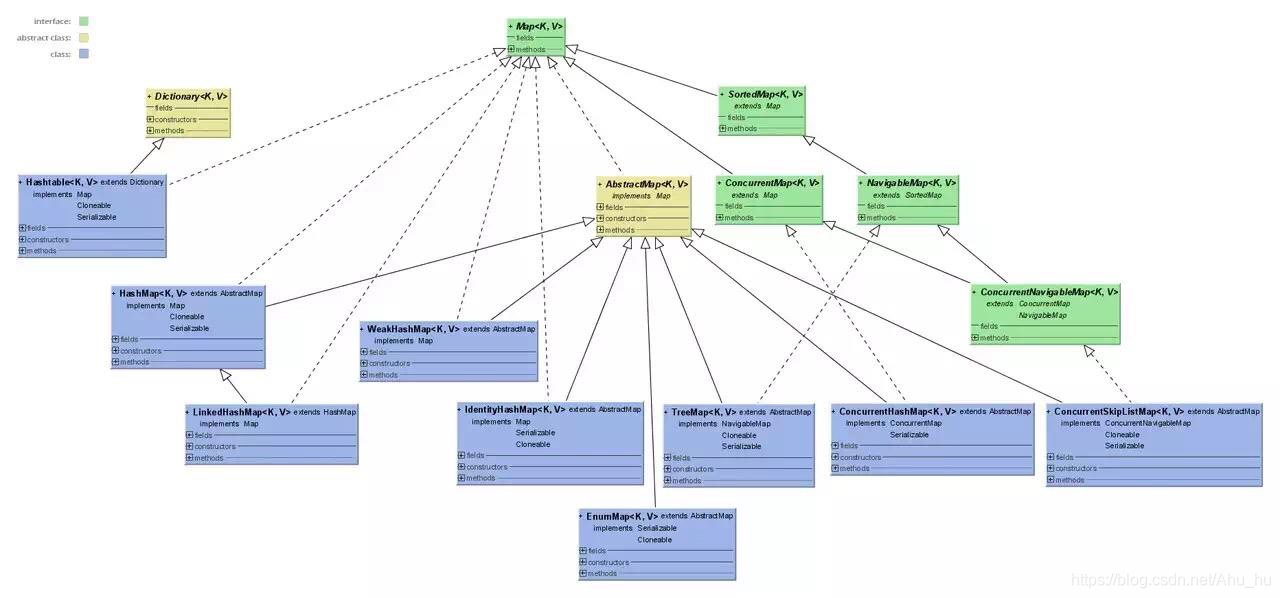
Map
Map类型的集合是采用键值对的形式来存储数据的, 一个映射不能包含重复的键,每个键最多只能映射到一个值。
常用方法:
添加功能
V put(K key, V value) :添加元素。
如果键是第一次存储,就直接存储元素,返回null。如果键不是第一次存储,就用值把以前的值替换掉,返回以前的值。
删除功能
void clear():移除所有的键值对元素。
V remove(Object key) :根据键删除键值对元素,返回删除的值。
判断功能
boolean containsKey(Object key) :判断集合是否包含指定的键
boolean containsValue(Object value):判断集合是否包含指定的值
boolean isEmpty():判断集合是否为空
获取功能
V get(Object key):根据键获取值
Set keySet():获取集合中所有键的集合
Collection values():获取集合中所有值得集合
长度功能
int size() :返回集合中键值对的对数
Map集合遍历方法
HashMap
HashMap是一个散列表,它存储的内容是键值对(key-value)映射,它是基于哈希表的 Map 接口的非同步实现。
HashMap和HashTable的区别:
- 线程安全:HashMap时线程不安全的,如果要保证线程安全,可以用ConcurrentHashMap,HashTable 时线程安全的,方法经过synchronized修饰;
- 效率:HashMap效率较Hashtable高。 另外,HashTable 基本被淘汰,不要在代码中使用它;
- 对 Null key 和 Null value 的支持 : HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;HashTable 不允许有 null 键和 null 值,否则会抛出 NullPointerException。
- 初始容量大小和每次扩充容量大小的不同 : ① 创建时如果不指定容量初始值,Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为 2 的幂次方大小(HashMap 中的
tableSizeFor()方法保证)。也就是说 HashMap 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。 - 底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
HashMap底层实现
在 JDK 1.7 中 HashMap 是以数组加链表的形式组成的,JDK 1.8 之后新增了红黑树的组成结构,当链表大于 8 并且容量大于 64 时,链表结构会转换成红黑树结构。
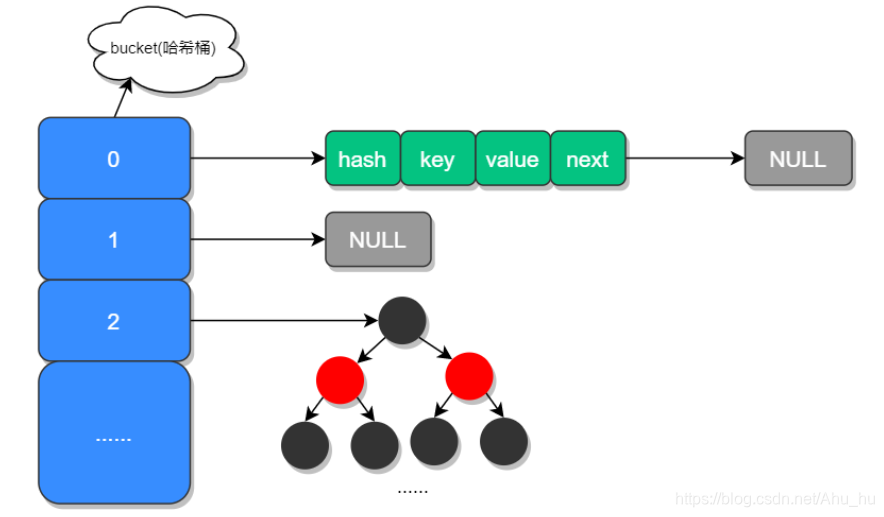
JDK 1.8 之所以添加红黑树是因为一旦链表过长,会严重影响 HashMap 的性能,而红黑树具有快速增删改查的特点,这样就可以有效的解决链表过长时操作比较慢的问题。
HashMap源码分析
// HashMap 初始化长度
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// HashMap 最大长度
static final int MAXIMUM_CAPACITY = 1 << 30; // 1073741824
// 默认的加载因子 (扩容因子)
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当链表长度大于此值且容量大于 64 时
static final int TREEIFY_THRESHOLD = 8;
// 转换链表的临界值,当元素小于此值时,会将红黑树结构转换成链表结构
static final int UNTREEIFY_THRESHOLD = 6;
// 最小树容量
static final int MIN_TREEIFY_CAPACITY = 64;
加载因子
加载因子又叫扩容因子或负载因子,用来判断什么时候进行扩容的。假设加载因子是 0.5,HashMap 的初始化容量是 16,那么当 HashMap 中有 16*0.5=8 个元素时,HashMap 就会进行扩容。
出于性能和容量之间的平衡考虑,扩容因子设置为0.75:
- 当加载因子设置比较大的时候,扩容的门槛就被提高了,扩容发生的频率比较低,占用的空间会比较小,但此时发生 Hash 冲突的几率就会提升,因此需要更复杂的数据结构来存储元素,这样对元素的操作时间就会增加,运行效率也会因此降低;
- 而当加载因子值比较小的时候,扩容的门槛会比较低,因此会占用更多的空间,此时元素的存储就比较稀疏,发生哈希冲突的可能性就比较小,因此操作性能会比较高。
HashMap常用方法:查询、新增、数据扩容
查询源码:
public V get(Object key) {
Node<K,V> e;
// 对 key 进行哈希操作
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 非空判断
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 判断第一个元素是否是要查询的元素
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 下一个节点非空判断
if ((e = first.next) != null) {
// 如果第一节点是树结构,则使用 getTreeNode 直接获取相应的数据
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do { // 非树结构,循环节点判断
// hash 相等并且 key 相同,则返回此节点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
新增方法:
public V put(K key, V value) {
// 对 key 进行哈希操作
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 哈希表为空则创建表
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 根据 key 的哈希值计算出要插入的数组索引 i
if ((p = tab[i = (n - 1) & hash]) == null)
// 如果 table[i] 等于 null,则直接插入
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 如果 key 已经存在了,直接覆盖 value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果 key 不存在,判断是否为红黑树
else if (p instanceof TreeNode)
// 红黑树直接插入键值对
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 为链表结构,循环准备插入
for (int binCount = 0; ; ++binCount) {
// 下一个元素为空时
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 转换为红黑树进行处理
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// key 已经存在直接覆盖 value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 超过最大容量,扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
新增方法的执行流程,如下图所示:
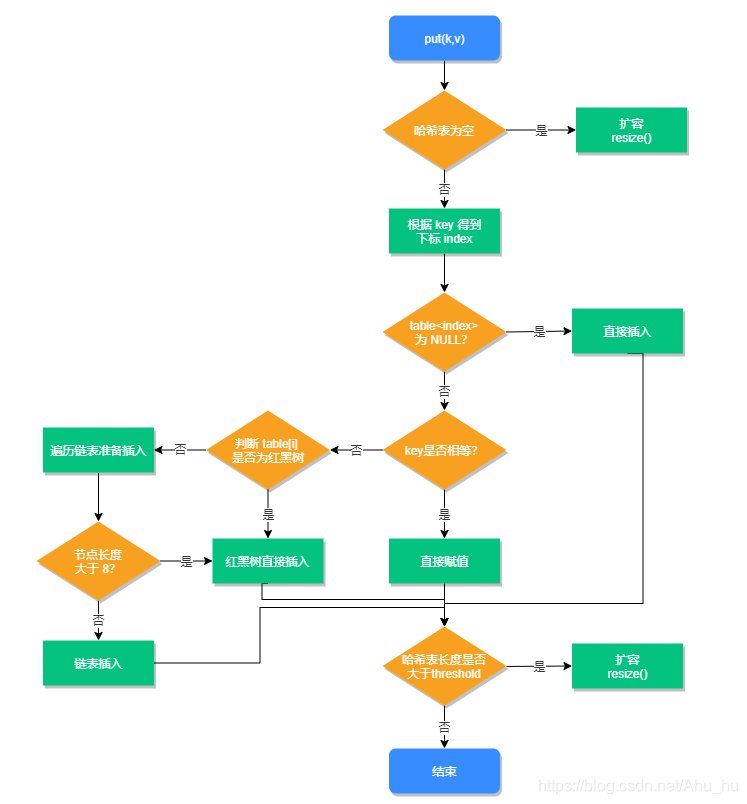
扩容方法:
final Node<K,V>[] resize() {
// 扩容前的数组
Node<K,V>[] oldTab = table;
// 扩容前的数组的大小和阈值
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
// 预定义新数组的大小和阈值
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩容了
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 扩大容量为当前容量的两倍,但不能超过 MAXIMUM_CAPACITY
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
// 当前数组没有数据,使用初始化的值
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
// 如果初始化的值为 0,则使用默认的初始化容量
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 如果新的容量等于 0
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
// 开始扩容,将新的容量赋值给 table
table = newTab;
// 原数据不为空,将原数据复制到新 table 中
if (oldTab != null) {
// 根据容量循环数组,复制非空元素到新 table
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果链表只有一个,则进行直接赋值
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
// 红黑树相关的操作
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 链表复制,JDK 1.8 扩容优化部分
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引 + oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 将原索引放到哈希桶中
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 将原索引 + oldCap 放到哈希桶中
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap死循环分析
主要原因在于并发下的 Rehash 会造成元素之间会形成一个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap 。
详情请查看:https://coolshell.cn/articles/9606.html
ConcurrentHashMap
后期补充。。。
HashTable
Hashtable 是遗留类,很多映射的常用功能与 HashMap 类似,不同的是它承自 Dictionary 类,并且是线程安全的,并发性不如 ConcurrentHashMap。HashTable不建议在新代码中使用,不需要线程安全的场合可以用HashMap替换,需要线程安全的场合可以用 ConcurrentHashMap。
TreeMap(可排序)
TreeMap实现SortedMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。
如果使用排序的映射,建议使用TreeMap。
在使用TreeMap时,key必须实现Comparable接口或者在构造TreeMap传入自定义的Comparator,否则会在运行时抛出java.lang.ClassCastException类型的异常。
参考:https://www.ibm.com/developerworks/cn/java/j-lo-tree/index.html
红黑树???
LinkedHashMap(记录插入顺序)
LinkedHashMap是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的,也可以在构造时带参数,按照访问次序排序。
参考
- https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/Java%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6%E5%B8%B8%E8%A7%81%E9%9D%A2%E8%AF%95%E9%A2%98.md
- https://www.runoob.com/java/java-collections.html
- https://blog.csdn.net/lixiaobuaa/article/details/79689338
- https://www.jianshu.com/p/b48c47a42916
- https://blog.csdn.net/qq_36748278/article/details/77126935
- https://kaiwu.lagou.com/course/courseInfo.htm?courseId=59#/detail/pc?id=1762