原创文章第235篇,专注“个人成长与财富自由、世界运作的逻辑与投资"。
昨天有朋友留言说,L2R效果不好,当然我不知道这位兄弟的场景。
pybroker vs qlib
pybroker的结构里,有一个特别的地方:
无论是规则型策略,还是机器学习,它默认是按symbol独立分开的。
每个函数的context是当前这个symbol的。
我的积木式是使用了它的add_before_exec来完成的,这个传入的所有的ctxs。所以,我没有调用它的add_exec_fn函数还使用onbar这个函数。
机器模型也是,它是针对每个symbol,训练一个模型,我在想,如果4000支股票,这就训练了4000个模型。——它的思路就是每个symbol都是各玩各人。但这里不是对的。比如我们想整合排序学习,就是把所有symbol统一训练,然后对它们进行综合排序。
pybroker本身号称要兼容机器学习与传统量化,确实也是这么做的,还实现了WFA模式。可是竟然变成一个symbol一个model的模式,看来作者确实不太理解AI机器学习如何落地量化金融。
而qlib相反,它的传统规则量化非常弱,基本不支持写规则,ai模型出来之后,就一个topK轮动,比如要加一些择时就非常难。二者比较互补。我的计划就是取长补短,取它们优点的地方。
DataSource vs DataSet
pybroker的DataSource非常轻,我自己实现了一个从本地加载csv的,后续可以轻松扩展从hdf5,或者mongo的。pybroker近期还实现了akshare的DataSource,非常实用。
qlib使用了自己的“数据格式”,基本就是冲着高频去的,说实话,比较“鸡肋”。日频的数据量相对下,用不着。若真是高频场景,可以使用专业的解决方案,比如flink或spark等。
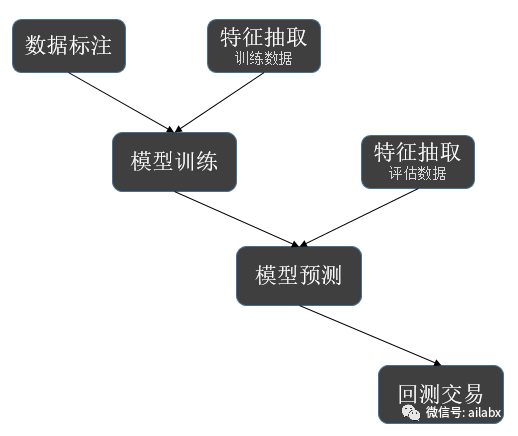
由于pybroker是一个symbol一个model,它没有qlib的dataset,可以直接提供数据给机器训练使用,因此,我们借用一下qlib的dataset相关的代码,包括预处理等。
我们的目标,就是数据实现自动标注,包括label,提供给模型训练之用。
参考qlib的Alpha158库。158个因子精简为15个因子,超额收益仍然接近10%
下面的alpha相当于是一个因子库:
所有代码已经发布至星球:我的开源项目及知识星球
class Alpha:
def __init__(self):
pass
def get_feature_config(self):
return self.parse_config_to_fields()
def get_label_config(self):
return ["shift(close, -2)/shift(close, -1) - 1"], ["label"]
@staticmethod
def parse_config_to_fields():
# ['CORD30', 'STD30', 'CORR5', 'RESI10', 'CORD60', 'STD5', 'LOW0',
# 'WVMA30', 'RESI5', 'ROC5', 'KSFT', 'STD20', 'RSV5', 'STD60', 'KLEN']
fields = []
names = []
windows = [5, 10, 20, 30, 60]
fields += ["corr(close/shift(close,1), log(volume/shift(volume, 1)+1), %d)" % d for d in windows]
names += ["CORD%d" % d for d in windows]
return fields, names
dataset使用它来对数据进行标注。
class DataSet:
def __init__(self, handler=None):
self.handler = handler
def _process(self, df):
if not self.handler:
return df
fields, names = self.handler.get_feature_config()
label_fields, label_names = self.handler.get_label_config()
for field, name in zip(fields, names):
ind = to_indicator(name, field)
df[name] = ind(df)
for field, name in zip(label_fields, label_names):
ind = to_indicator(name, field)
df[name] = ind(df)
return df
def load(self, symbols, start_date='20100101', end_date=datetime.now().strftime('%Y%m%d')):
dfs = []
for s in symbols:
# dirname去掉文件名,返回目录
path = os.path.dirname(__file__)
# print(path)
df = pd.read_csv('{}/data/{}.csv'.format(path, s), dtype={'date': str})
for col in ['open', 'high', 'low', 'close']:
df[col] = df[col] / df[col][0]
df.set_index('date', inplace=True)
df.index = pd.to_datetime(df.index)
df.sort_index(ascending=True, inplace=True)
df = self._process(df) # 如果有handler,同使用handler标注
dfs.append(df)
df = pd.concat(dfs)
# df['date'] = pd.to_datetime(df['date'])
df['swing'] = 1
df.sort_index(ascending=True, inplace=True)
return df[(df.index >= start_date) & (df.index <= end_date)]
使用Alpha这个handler,自动把因子和lable都标注好了。

机器模型
泛泛而言,机器学习在金融应用,效果可能很多时候不及一个简单的roc_20——动量策略在单边市被证明是真实有效的。而且规则型策略,我分分钟可以做一个出来,回测效果还不错的。
考虑机器学习多因子模型,是考虑它整合因子的能力,动态跟进市场的能力。当然不太可能,拿一个sklearn的demo fit一下,predict一样就可以得到一个高夏普的策略,那市场不就乱套了。金融数据低信噪比的特性,让其应用于金融投资尤其难。
从逻辑上讲,我觉得L2R是一个方面,另一个方向就是深度强化学习。而其它的提升就是找更多优质的数据,然后挖掘出更好的因子,如此而已。
StockRanker = 选股 + 排序学习 + 梯度提升树。按公开资料,bigquant是使用list wise learning to rank算法。
我们需要开发一个自己的“StockRanker”。
今天准备好数据,明天写模型——StockRanker。
今日策略——创业板布林带
今天写一个创业板布林带策略。
作为示例,规则也比较简单:
收盘价突破布林带上轨做多,突破下轨平仓。
这里我们需要扩展两个函数:cross_up, cross_down,向上突破和向上突破。
def cross_up(left, right):
left = pd.Series(left)
right = pd.Series(right)
diff = left - right
diff_shift = diff.shift(1)
return (diff >=0) & (diff_shift <0)
def cross_down(left, right):
left = pd.Series(left)
right = pd.Series(right)
diff = left - right
diff_shift = diff.shift(1)
return (diff <= 0) & (diff_shift > 0)
定义好的指标,策略一如继往的简单:

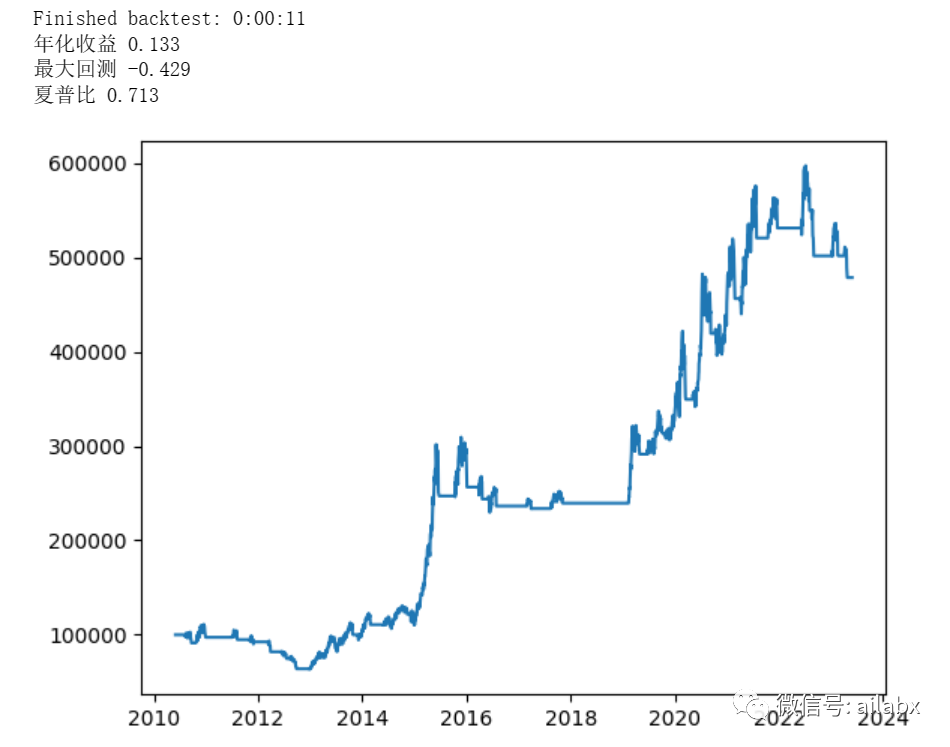
今天代码已经同步到星球。我的开源项目及知识星球
小结:
1、机器学习特征工程dataset。
2、创业板布林带突破策略