1.介绍
本文基本从《Generative Adversarial Nets》翻译总结的。
GAN(Generative Adversarial Nets),生成式对抗网络。包含两个模型,一个生成模型G,用来捕捉数据分布,一个识别模型D,用来评估采样是来自于训练数据而不是G的可能性。
这两个模型G与D是竞争关系、敌对关系。比如生成模型G就像是在制造假的货币,而识别模型D就像是警察,尝试检测这些假币。这两个模型间的竞争,使它们都在不断完善自己,直到假币和真币无法区分为止。
本论文的例子,训练两个模型时仅使用了反向传播和dropout 算法,在从生成模型中采样时,只使用的前向传播。近似推理或者Markov chain是不必要的。
2.相关方法
(1)定向图模型与非定向图模型,比如限制玻尔兹曼机(RBMs)、深度玻尔兹曼机(DBMs)、以及相关变体。这些模型使用了归一化处理,针对随机参数的所有状态。这些归一化比例函数以及他们的梯度是很难计算的,虽然可以采用Markov chain Monte Carlo(MCMC)方法进行估计。
(2)DBNs(Deep belief networks) 是组合模型,包括一个非定向层和一堆定向层。当一个快速近似逐层训练存在时,DBNs在集合非定向与定向模型时也会面临计算困难的问题。
(3)生成随机网络GSN, 使用了Markov chain。而GAN不需要Markov chain,因为在生成时,不需要反向传播。
3.对抗网络
p(z):带有噪声的输入;
G(z,θ):一个可微分的函数,带参数θ的多层感知机;
D(x):代表x是来自于data还是来自于生成函数的概率。
整体训练函数如下,最大化D,同时针对G来最小化log(1-D(G(z))):
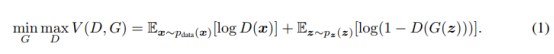
算法如下:

3.1命题1
如果G固定,最佳的D如下:

证明如下:

3.2定理1
C(G)=max V(G,D)。
只有生成数据的分布函数p和原数据data的分布函数p相等时,C(G)训练完成,其值等于-log4.
3.3算法的收敛
生成数据的分布函数p收敛于原数据data的分布函数p。
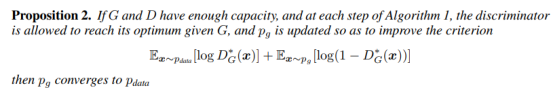
实际上,生成网络只有有限的生成数据分布函数P,因为函数G(z,θ)的存在,我们最终是最优化θ,而不用最优化生成数据分布函数P。
4.实验结果
使用Parzen窗估计,应用于G产生的样例。
核密度估计(kernel density estimation)是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,由Rosenblatt (1955)和Emanuel Parzen(1962)提出,又名Parzen窗(Parzen window)。
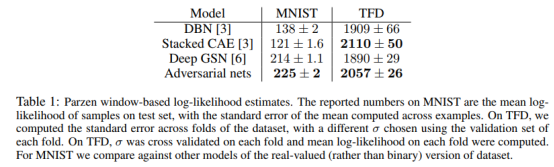
生成的示例,比如下图最右侧的图片是生成网络生成的。

5.总结
1.可以用于半监督学习,比如在标签数据较少时,识别器或者推理网络获得的特征可以改善分类效果。
2.训练效率提升,知道了G和D可以有效提升训练速度。
