文章目录
1. 分布式计算概述
- 计算与分布式计算
- 计算:对数据进行处理,使用统计分析等手段得到需要的结果
- 分布式计算:多台服务器协同工作,共同完成一个计算任务
- 分布式计算的两种工作模式
- 分散→汇总(MapReduce)
- 中心调度→步骤执行(Spark、Flink)
2. MapReduce概述
- MapReduce
- Hadoop中分布式计算组件
- 分散→汇总模式
- 主要接口
- map接口:“分散”功能
- reduce接口:“汇总”功能
- 运行机制
- 将执行的需求分解为多个 Map Task 和 Reduce Task
- 将 Map Task 和 Reduce Task 分配到对应的服务器去执行
3. YARN概述
- YARN
- Hadoop一个组件
- 用于集群的资源调度
- MapReduce与YARN的关系
- YARN用来调度资源给MapReduce分配和管理运行资源
- MapReduce需要YARN才能执行
4. YARN架构
4.1 核心架构
- 核心架构角色
- 主:ResourceManager
- 从:NodeManager
- 功能
- ResourceManager: 管理、统筹并分配整个集群的资源
- NodeManager:管理、分配单个服务器的资源,即创建管理容器,由容器提供资源供程序使用
4.2 辅助架构
- ProxyServer:保障web UI访问的安全性
- JobHistoryServer:记录历史程序运行信息和日志
5. MapReduce & YARN的部署
5.1 集群规划
- node1:ResourceManager、NodeManager、ProxyServer、JobHistoryServer
- node2:NodeManager
- node3:NodeManager
5.2 MapReduce配置文件
- 在 $HADOOP_HOME/etc/hadoop文件夹内,修改:
- mapred-env.sh文件
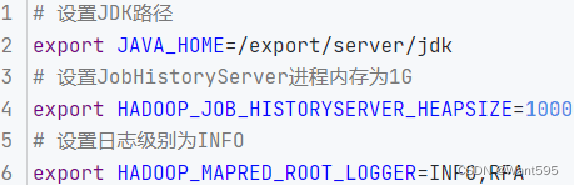
- mapred-site.xml文件
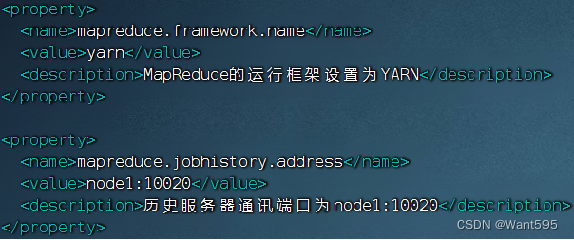
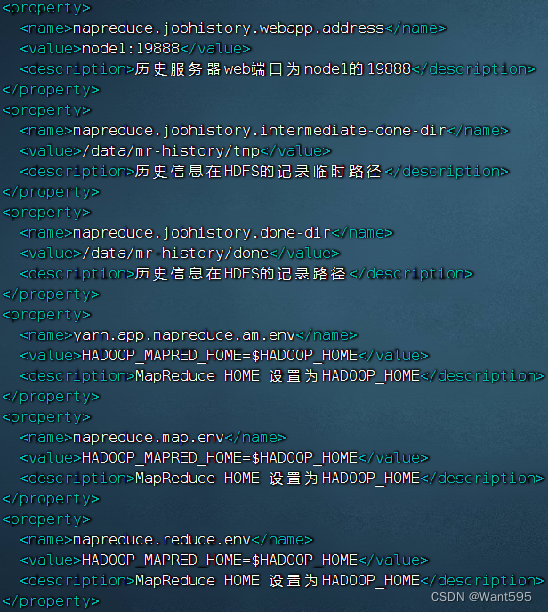
- yarn-env.sh文件

- yarn-site.xml文件
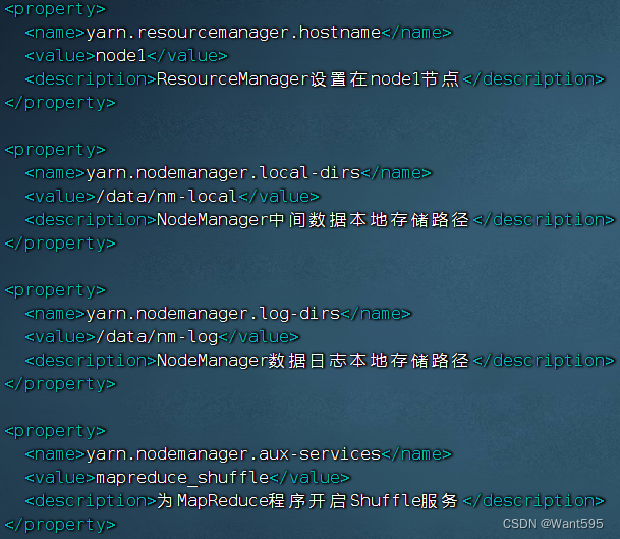
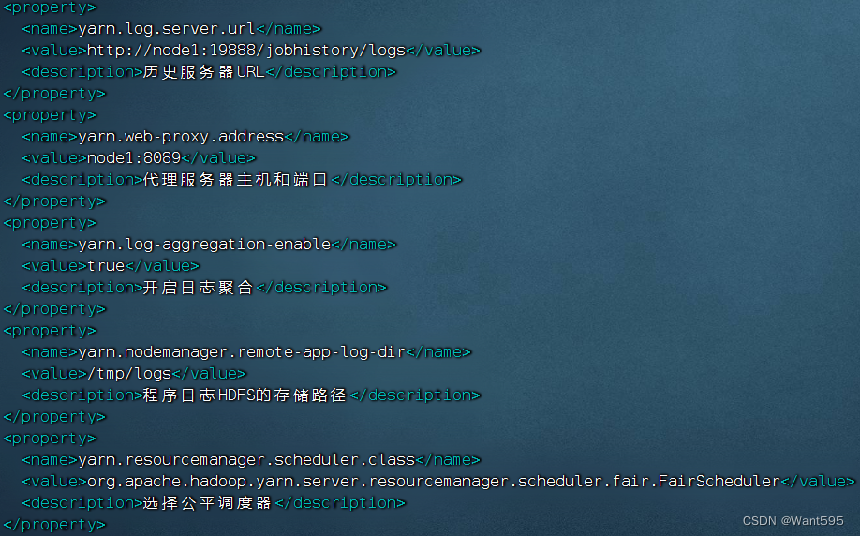
5.3 分发配置文件

5.4 集群启动命令介绍
- 一键启动YARN集群:$HADOOP_HOME/sbin/start-yarn.sh
- 一键停止YARN集群:
$HADOOP_HOME/sbin/stop-yarn.sh
5.5 开启YARN集群
在node1服务器,以hadoop用户执行
- start-yarn.sh
- mapred --daemon start historyserver
查看YARN的运行
- http://node1:8088
6. MapReduce & YARN初体验
6.1 集群启停命令
- 启动
- start-yarn.sh
- mapred --daemon start historyserver
- 停止
- stop-yarn.sh
- mapred --daemon stop historyserver
6.2 提交MapReduce任务到YARN执行
略