目录
一、前言:
(1)本练,我们来完善一下对于数据的处理
(2)对于同一标签内的内容的遍历爬取
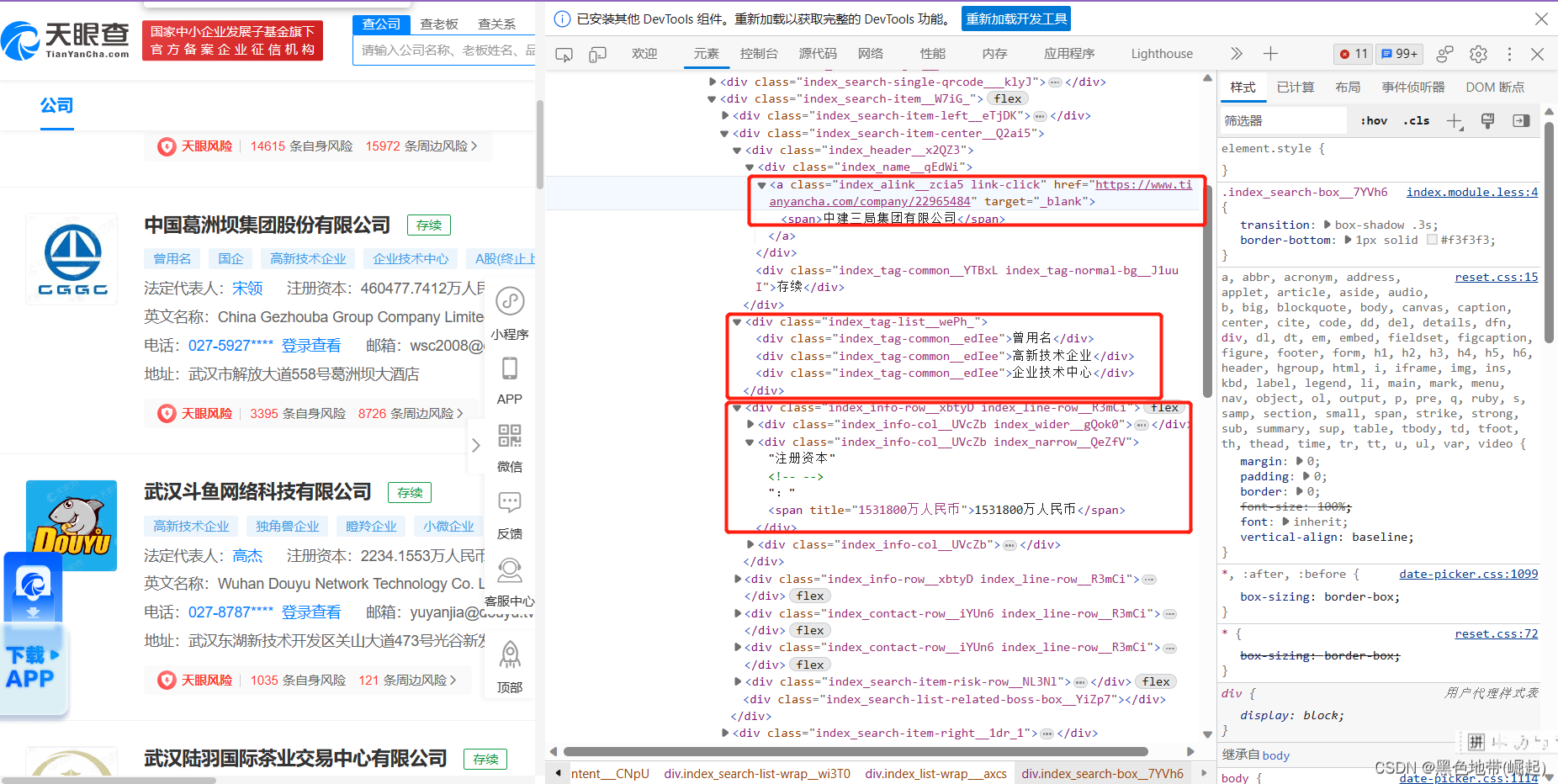
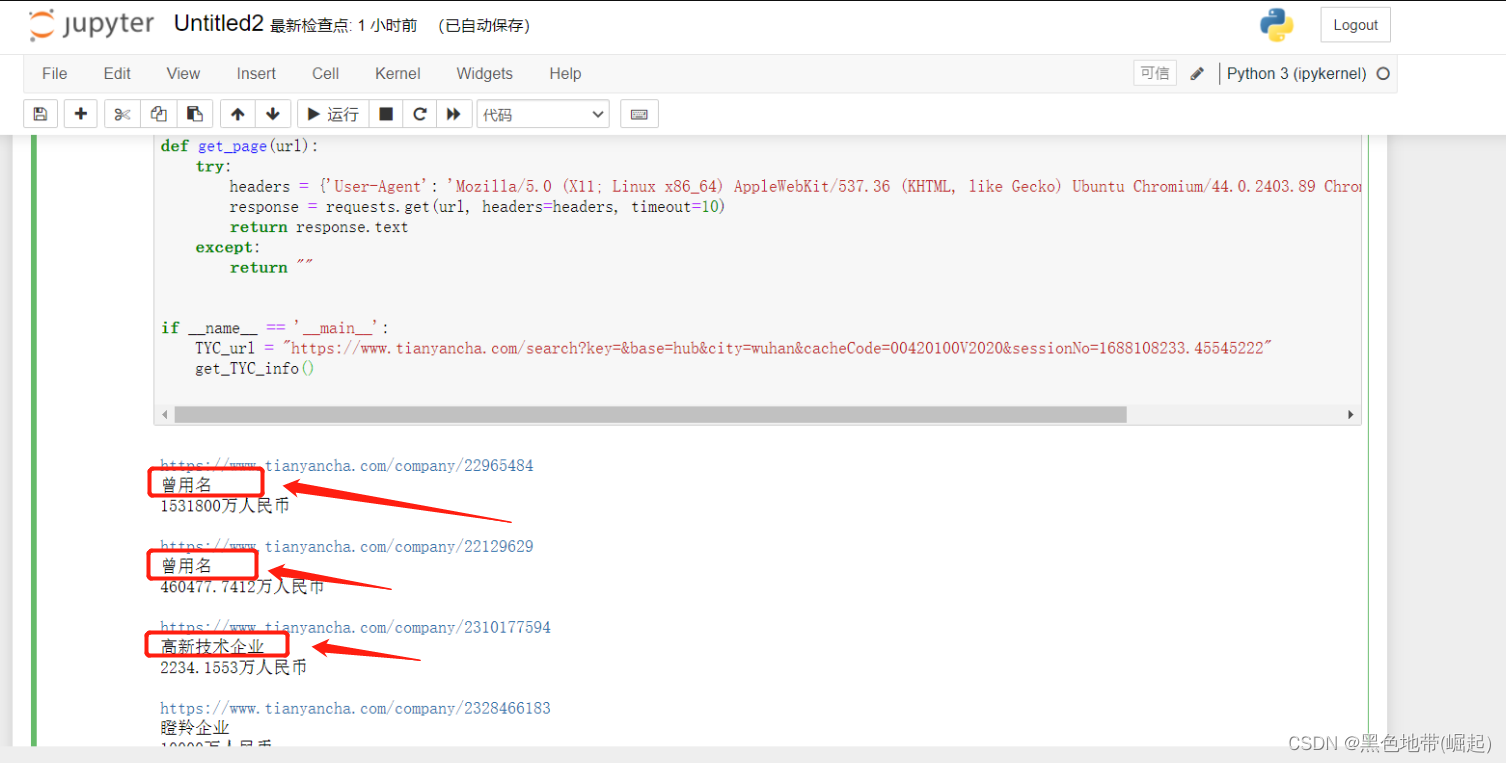
上一段代码的,我们是不是在那个曾用名、高新技术企业、企业技术中兴
(也就是对于的企业的描述那里,指爬取到第一个)
二、分析代码
上一段代码:
company_type = item.find('div', attrs={'class': 'index_tag-list__wePh_'}).find_all('div', attrs={'class': 'index_tag-common__edIee'})[0].text代码注释:
(1)item.find('div', attrs={'class': 'index_tag-list__wePh_'}) 表示在变量 item 所代表的HTML页面中查找具有 class 属性为 'index_tag-list__wePh_' 的 <div> 元素。这个方法返回的是第一个满足条件的 <div> 元素。
(2).find_all('div', attrs={'class': 'index_tag-common__edIee'}) 表示在前面找到的 <div> 元素内继续查找具有 class 属性为 'index_tag-common__edIee' 的所有 <div> 元素。这个方法返回的是一个列表,包含满足条件的所有元素。
(3)[0].text 表示从前面返回的列表中取出第一个元素,并获取其文本内容。.text 是 BeautifulSoup 库中的方法,用于提取元素的文本内容。
运行结果
三、完善代码
修改代码:
要获取class属性为index_tag-common__edIee的div元素中的所有文本内容
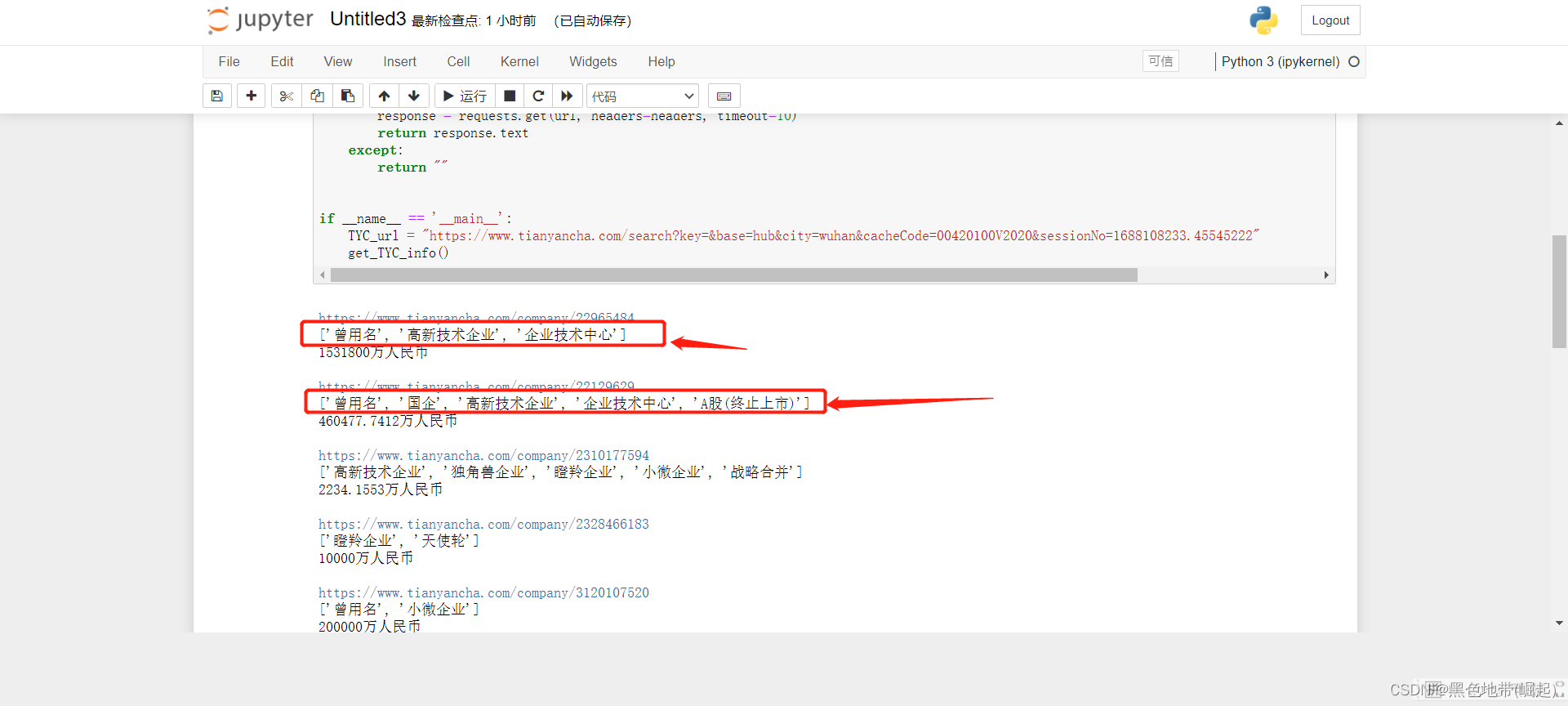
company_type = item.find('div', attrs={'class': 'index_tag-list__wePh_'}).find_all('div', attrs={'class': 'index_tag-common__edIee'})
tpye_texts = [element.text for element in company_type]这将返回一个包含所有匹配的div元素中的文本内容的列表。
注释:
(1)item.find('div', attrs={'class': 'index_tag-list__wePh_'}) 表示在变量 item 所代表的 HTML 页面中查找具有 class 属性为 'index_tag-list__wePh_' 的 <div> 元素。这个方法返回的是第一个满足条件的 <div> 元素。
(2).find_all('div', attrs={'class': 'index_tag-common__edIee'}) 表示在前面找到的 <div> 元素内继续查找具有 class 属性为 'index_tag-common__edIee' 的所有 <div> 元素。这个方法返回的是一个列表,包含满足条件的所有元素。
(3)type_texts = [element.text for element in company_type] 是一个列表推导式。它遍历名为 company_type 的列表中的每个元素,并使用 .text 方法获取每个元素的文本内容。这样就创建了一个新的列表 type_texts,其中包含了 company_type 列表中每个元素的文本内容。
结果展示:
网络安全小圈子
GitHub - BLACKxZONE/Treasure_knowledge![]() https://github.com/BLACKxZONE/Treasure_knowledge
https://github.com/BLACKxZONE/Treasure_knowledge