目录
(说在前面,任何逻辑都有很多方法实现,我们先从最笨的讲起)
(注:其中的cookie需要填自己的)
一、翻页分析:
通过对比第一页与第二页的URL来看是否有差别
可以发现通过参数pageNum=来控制页面
(第一页pageNum参数被省略,如果下一面没有数据了,也可能出错)

二、代码逻辑
1、入口程序修改
if __name__ == '__main__':
with open('1.csv', 'a', encoding='utf-8', newline='') as f:
csv_w = csv.writer(f)
csv_w.writerow(('公司名', 'URL', '类型', '资金'))
for page in range(1, 6):
get_TYC_info(page)
print(f'第{page}页已爬完')
time.sleep(2)(1)if __name__ == '__main__':
一个条件语句,判断当前模块是否直接被运行。当该模块直接执行时,以下代码块将被执行。
(2)with open('1.csv', 'a', encoding='utf-8', newline='') as f:
打开名为"1.csv"的文件,并赋值给变量f。使用'a'模式打开文件,表示以追加方式写入文件内容。encoding='utf-8'表示以UTF-8编码打开文件,newline=''表示在写入时不插入额外的换行符。
(3)csv_w = csv.writer(f)
创建一个CSV写入器对象,并将文件对象f传递给它。这样可以通过该写入器对象来操作CSV文件。
(4)csv_w.writerow(('公司名', 'URL', '类型', '资金'))
使用CSV写入器对象csv_w将一个包含四个元素的元组写入CSV文件。这个元组表示CSV文件的表头,即第一行的内容。
(5)for page in range(1, 6):
这是一个循环语句,从1循环到5,将每个循环中的值赋给变量page。
(6)get_TYC_info(page)
调用名为get_TYC_info的函数,并传递当前循环的值page作为参数。这个函数用于爬取TYC网站上的信息。
(7)print(f'第{page}页已爬完')
打印当前循环的值page,并显示"第X页已爬完"的消息。这是一个简单的提示,用于显示程序的进度。
(8)time.sleep(2)
程序暂停执行2秒钟。这是为了避免过快地请求网页导致被屏蔽或限制访问。
2、page参数传入
def get_TYC_info(page):
TYC_url = f"https://www.tianyancha.com/search?key=&sessionNo=1688538554.71584711&base=hub&cacheCode=00420100V2020&city=wuhan&pageNum={page}"
1、将page参数传入进get_TYC_info()函数(页面的爬取函数)
2、f'URL……&pageNum={page}'
将URL中的page参数动态修改
三、完整代码
(代码在最后)
1、运行结果
(第1、2面都是可以爬的)
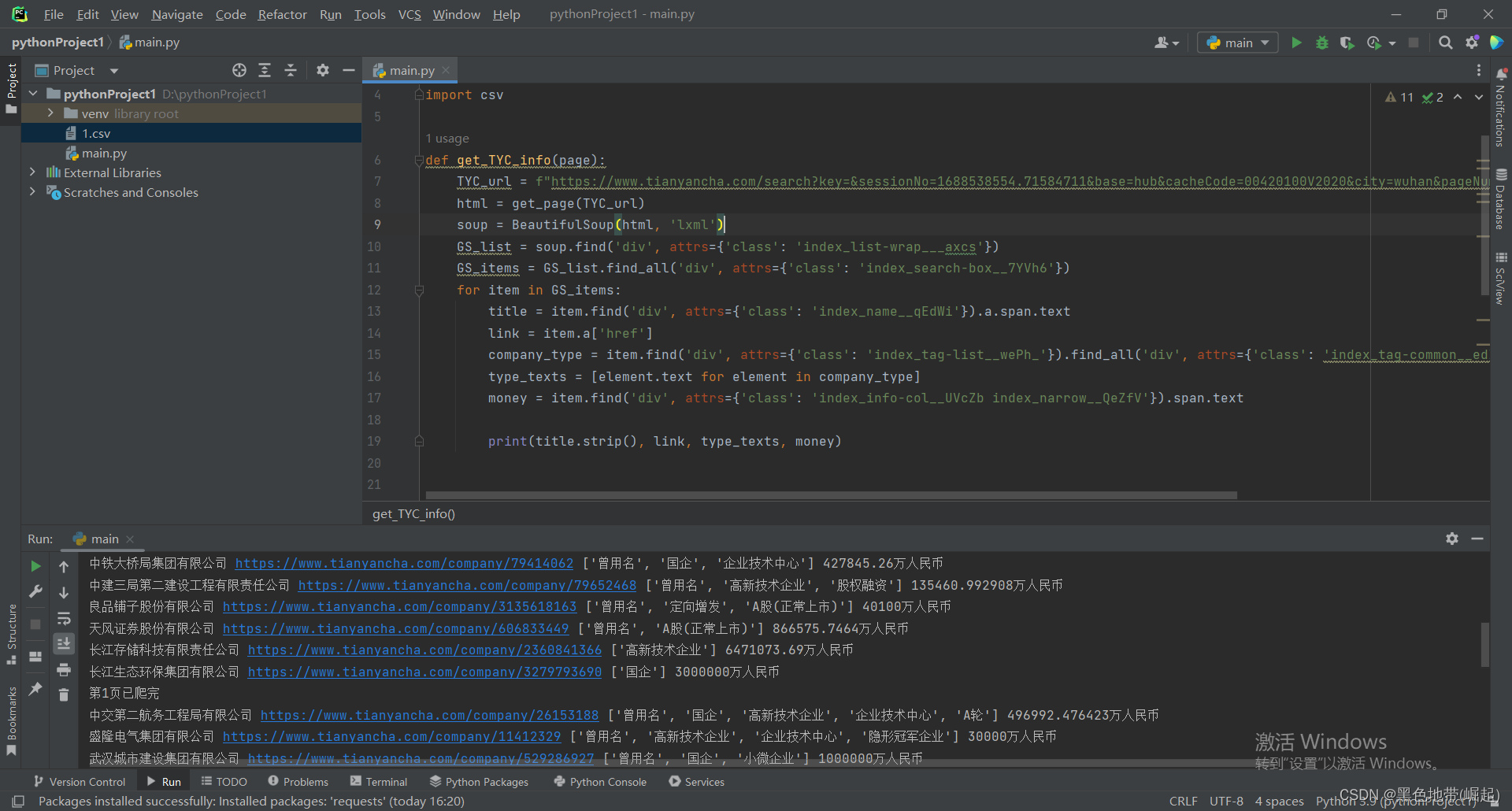
第2面开始有报错
(这个错误问题我们来分析一下)
其实就是爬取的列表为空,导致的错误

2、错误分析:
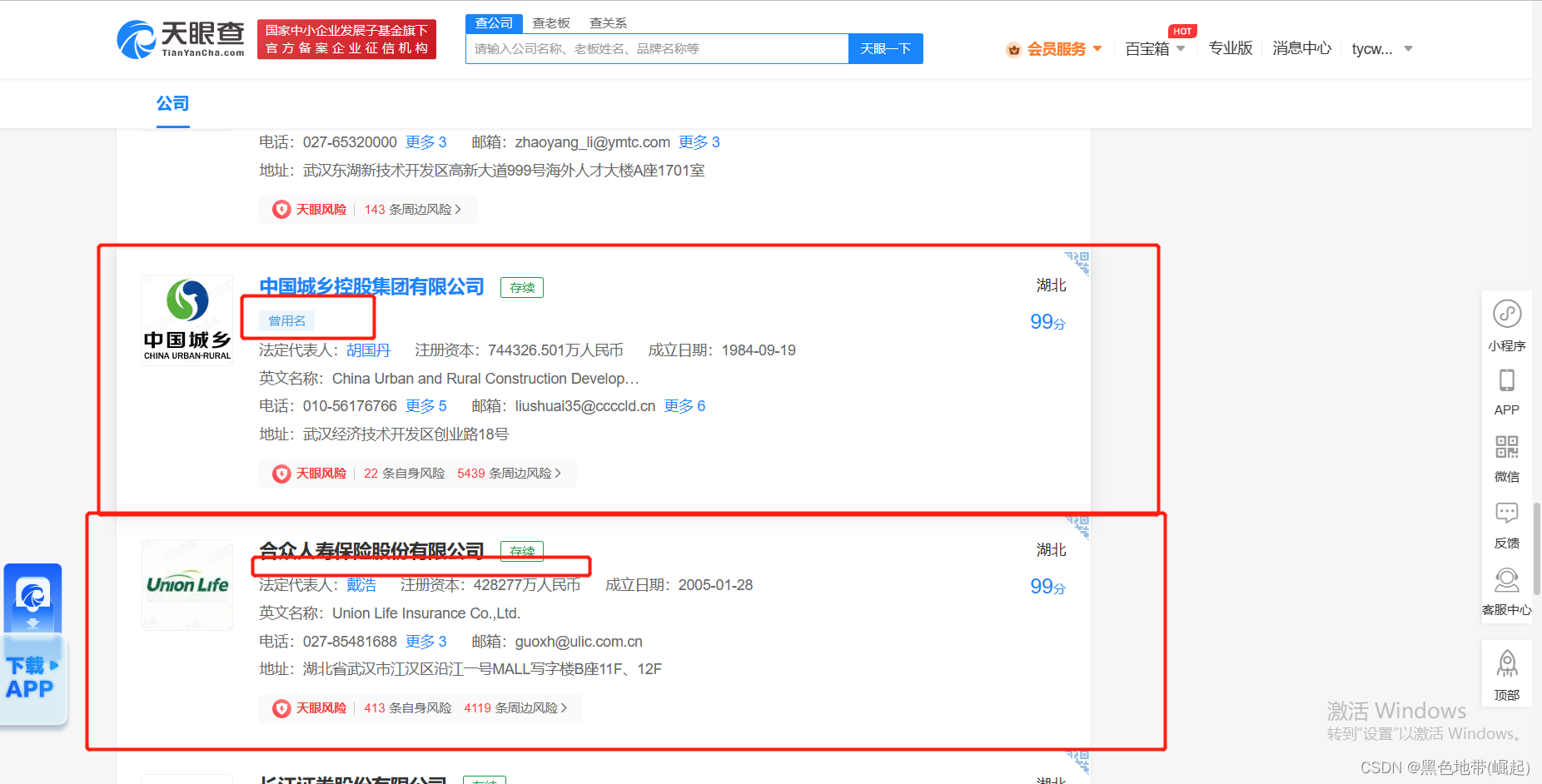
看图说话错误原因:
是不是到我们报错的位置这,下一个企业就没了相关类型了,对吧
所以爬取到的列表为空,从而导致了不能继续执行爬取下一级---->所以报错
3、缺陷代码:
import time
import requests
from bs4 import BeautifulSoup
import csv
def get_TYC_info(page):
TYC_url = f"https://www.tianyancha.com/search?key=&base=hub&city=wuhan&cacheCode=00420100V2020&sessionNo=1688108233.45545222&pageNum={page}"
html = get_page(TYC_url)
soup = BeautifulSoup(html, 'lxml')
GS_list = soup.find('div', attrs={'class': 'index_list-wrap___axcs'})
GS_items = GS_list.find_all('div', attrs={'class': 'index_search-box__7YVh6'})
for item in GS_items:
title = item.find('div', attrs={'class': 'index_name__qEdWi'}).a.span.text
link = item.a['href']
company_type = item.find('div', attrs={'class': 'index_tag-list__wePh_'}).find_all('div', attrs={'class': 'index_tag-common__edIee'})
type_texts = [element.text for element in company_type]
money = item.find('div', attrs={'class': 'index_info-col__UVcZb index_narrow__QeZfV'}).span.text
print(title.strip(), link, type_texts, money)
def get_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36',
'Cookie':'!!!!!!!!!!'
}
response = requests.get(url, headers=headers, timeout=10)
return response.text
except:
return ""
if __name__ == '__main__':
with open('1.csv', 'a', encoding='utf-8', newline='') as f:
csv_w = csv.writer(f)
csv_w.writerow(('公司名', 'URL', '类型', '资金'))
for page in range(1, 6):
get_TYC_info(page)
print(f'第{page}页已爬完')
time.sleep(2)
4、完善逻辑:
加上了一个if判断,第一个爬取点不为none才继续往后
if company_type_div is not None:
company_type = company_type_div.find_all('div', attrs={'class': 'index_tag-common__edIee'})
type_texts = [element.text for element in company_type]
else:
type_texts=''运行结果:
指定的5面全部爬取完了
5、完善代码:
(注:其中的cookie需要填自己的)
import time
import requests
from bs4 import BeautifulSoup
import csv
def get_TYC_info(page):
TYC_url = f"https://www.tianyancha.com/search?key=&sessionNo=1688538554.71584711&base=hub&cacheCode=00420100V2020&city=wuhan&pageNum={page}"
html = get_page(TYC_url)
soup = BeautifulSoup(html, 'lxml')
GS_list = soup.find('div', attrs={'class': 'index_list-wrap___axcs'})
GS_items = GS_list.find_all('div', attrs={'class': 'index_search-box__7YVh6'})
for item in GS_items:
title = item.find('div', attrs={'class': 'index_name__qEdWi'}).a.span.text
link = item.a['href']
company_type_div = item.find('div', attrs={'class': 'index_tag-list__wePh_'})
if company_type_div is not None:
company_type = company_type_div.find_all('div', attrs={'class': 'index_tag-common__edIee'})
type_texts = [element.text for element in company_type]
else:
type_texts=''
money = item.find('div', attrs={'class': 'index_info-col__UVcZb index_narrow__QeZfV'}).span.text
print(title.strip(), link, type_texts, money)
def get_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36',
'Cookie':'!!!!!!!!!!'
}
response = requests.get(url, headers=headers, timeout=10)
return response.text
except:
return ""
if __name__ == '__main__':
with open('1.csv', 'a', encoding='utf-8', newline='') as f:
csv_w = csv.writer(f)
csv_w.writerow(('公司名', 'URL', '类型', '资金'))
for page in range(1, 6):
get_TYC_info(page)
print(f'第{page}页已爬完')
time.sleep(2)
网络安全小圈子
GitHub - BLACKxZONE/Treasure_knowledge![]() https://github.com/BLACKxZONE/Treasure_knowledge
https://github.com/BLACKxZONE/Treasure_knowledge