目录
一、目标1:正则匹配图片的URL
URL位置
我们可以找到img都在这个标签里面
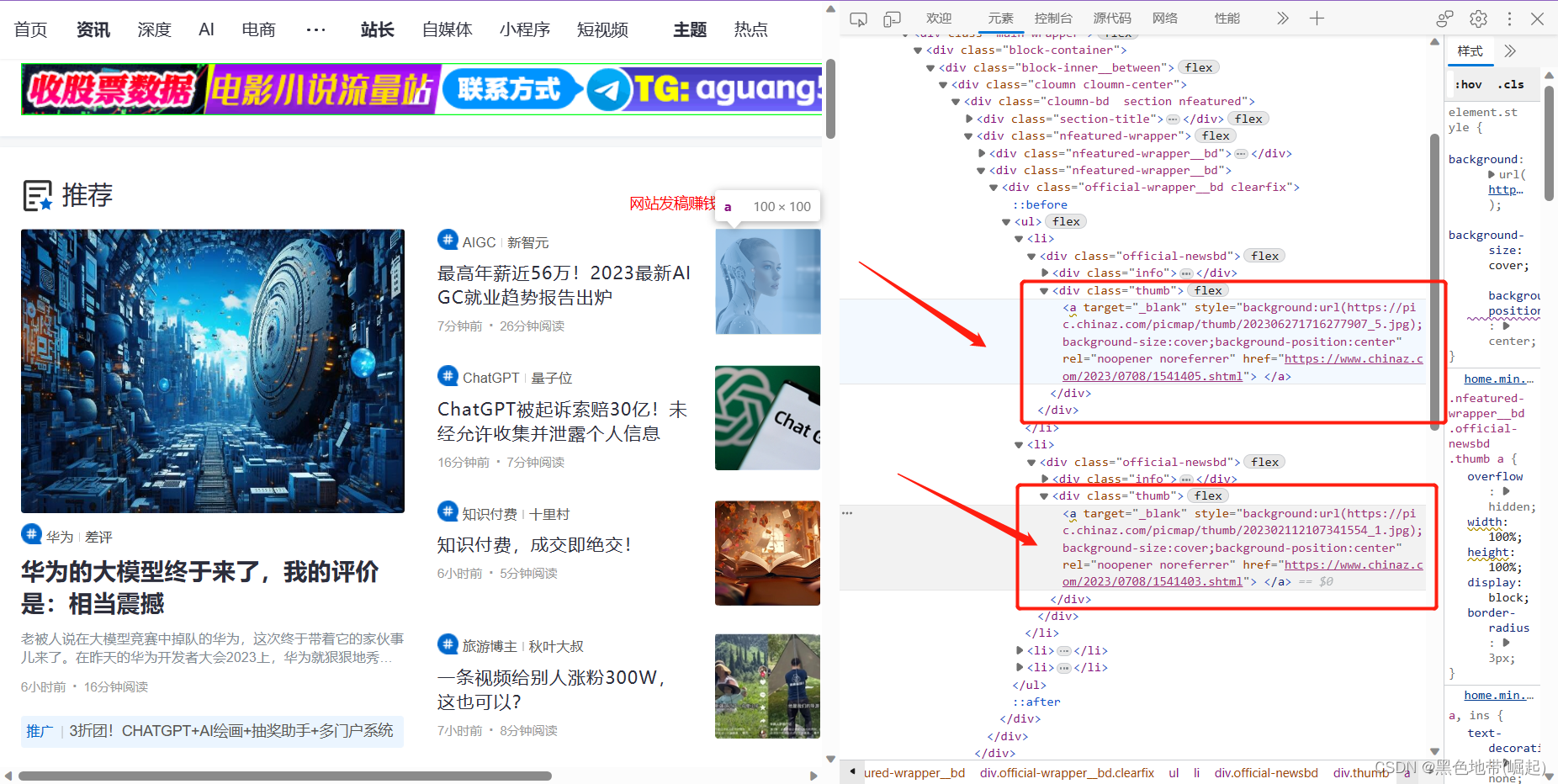
请求方法GET

提取URL位置
需要掌握的关键字
.*?
//表示匹配任意字符(除换行符)
(.*?)
//表示匹配任意字符(除换行符)0次或多次,尽可能少地匹配,并将这部分内容作为一个分组目标标签如下:
<div class="thumb">
<a target="_blank" style="background:url(https://pic.chinaz.com/picmap/thumb/202306271716277907_5.jpg);background-size:cover;background-position:center" rel="noopener noreferrer" href="https://www.chinaz.com/2023/0708/1541405.shtml">
</a>
</div>需要提取的内容如下:
(多加了一个\为转义字符)
img_url = <div class="thumb">.*?url\((.*?)).*?</div>爬取到所有的格式相符的图片内容
res:是一个正则表达式,用于匹配的模式。
img_url:是要进行匹配的字符串。
re.S:是re模块中的一个标志参数,表示将字符串视为单行,即将换行符也视为普通字符
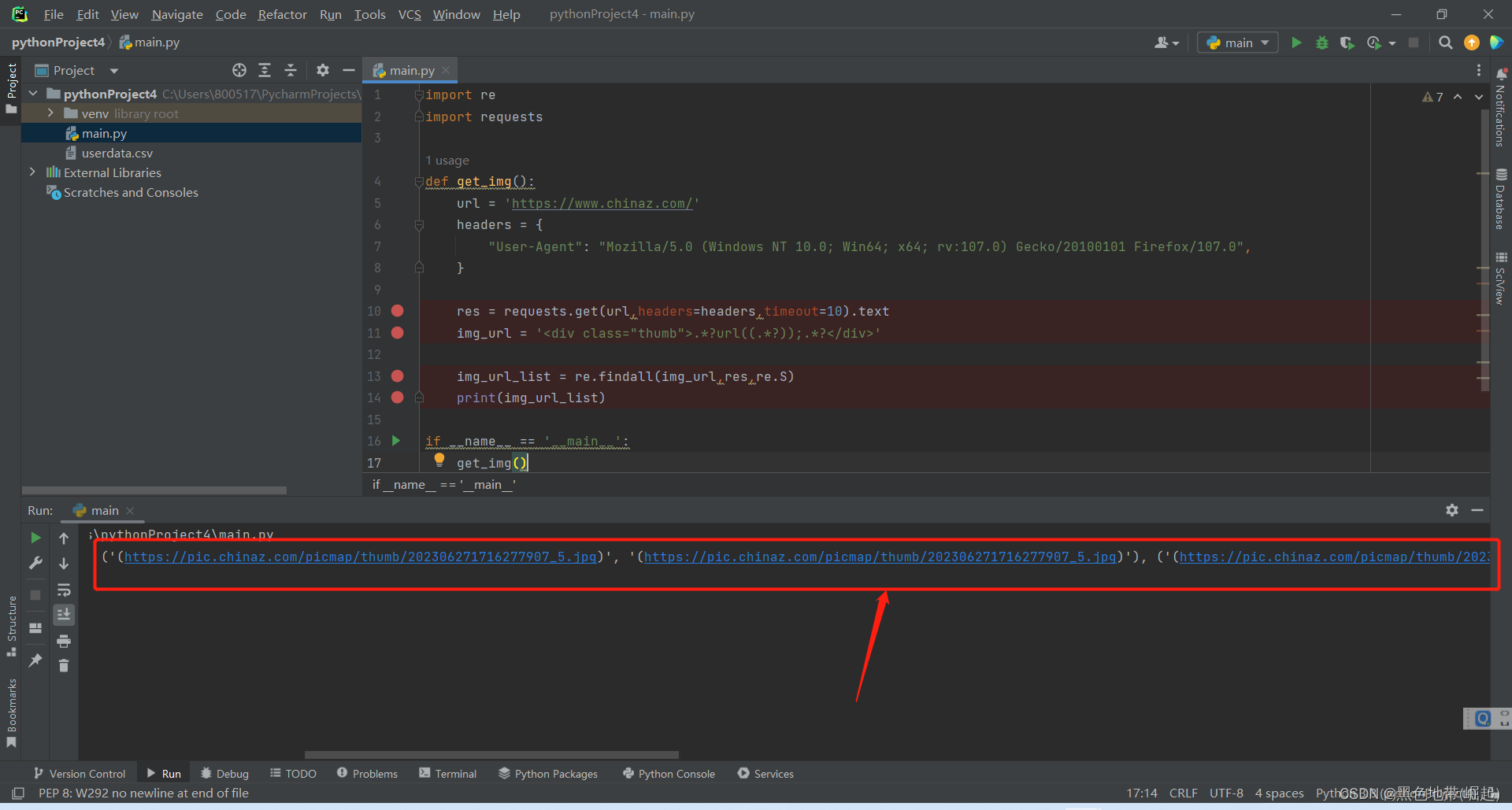
img_url_list = re.findall(res,img_url,re.S)运行结果:
将目标URL都爬取到了
完整代码:
import re
import requests
def get_img():
url = 'https://www.chinaz.com/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:107.0) Gecko/20100101 Firefox/107.0",
}
res = requests.get(url,headers=headers,timeout=10).text
img_url = '<div class="thumb">.*?url\((.*?));.*?</div>'
img_url_list = re.findall(img_url,res,re.S)
print(img_url_list)
if __name__ == '__main__':
get_img()二、目标2:创建文件夹
判断文件夹是否存在来决定是否创建文件夹,并使用os.makedirs()函数递归创建文件夹。如果文件夹已存在,则不会进行任何操作
('./test'也可以换为参数进行传值)
(os.mkdir()函数是不会递归创建文件夹)
import os
if not os.path.exists('./test'):
os.makedirs('./test')三、目标3:保存图片到test文件夹中
处理数据
首先依次遍历图片的URL,然后除去非必要的字符
使用replace()函数将非必要字符替换为空
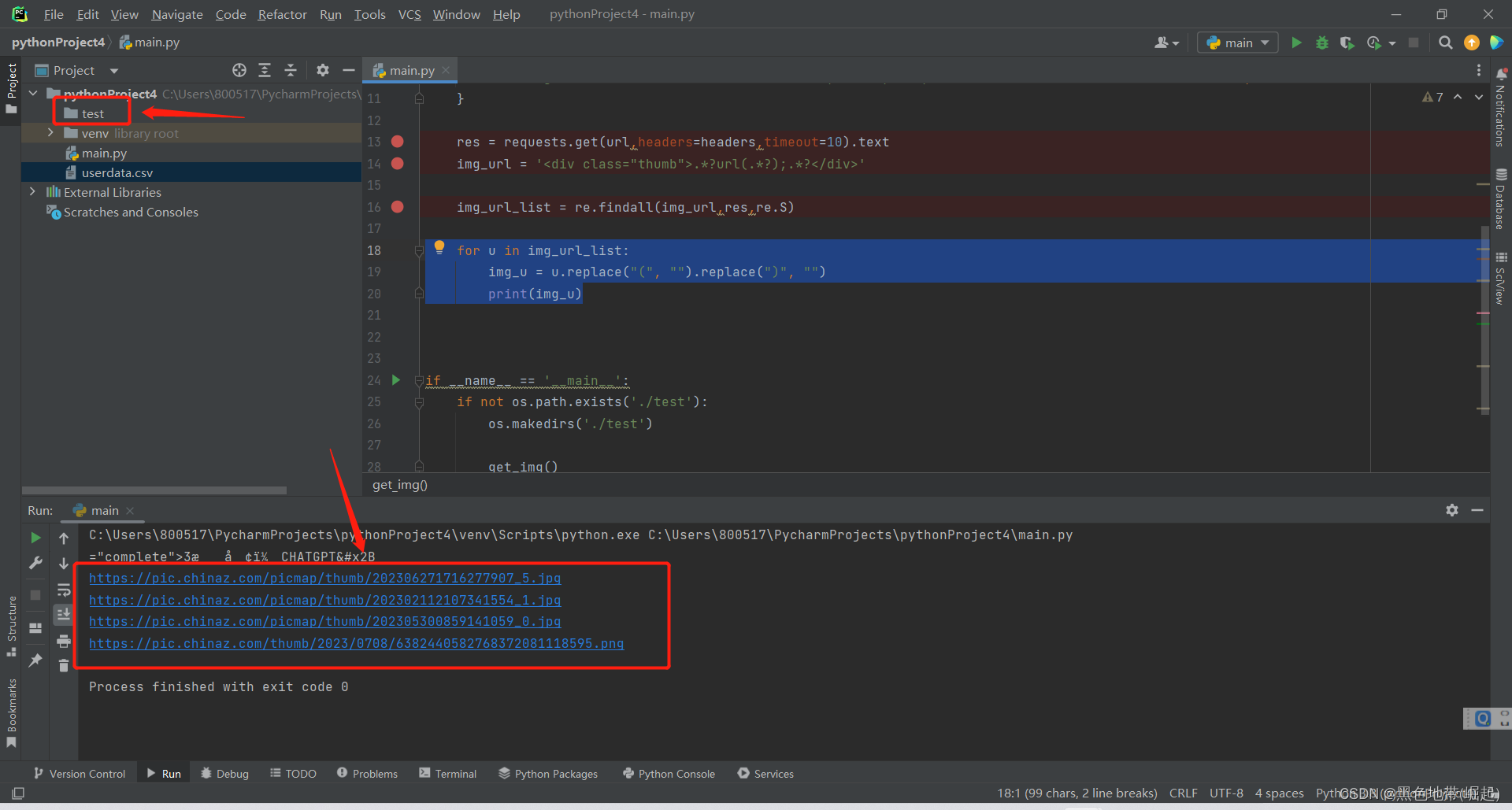
for u in img_url_list:
img_u = u.replace("(", "").replace(")", "")
print(img_u)运行后,文件夹已创建,URL也遍历成功
获取图片数据
有图片地址后get就可以请求到
.content返回二进制格式数据
image = requests.get(url=img_u,headers=headers,timeout=10).content
给文件命名
取url最后的那个为他的名字
也就是https://pic.chinaz.com/picmap/thumb/202306271716277907_5.jpg
{kind=link}
取 202306271716277907_5.jpg
以此类推
img_name = img_u.split('/')[-1]
将图片保存到本地
图片路径
下载图片到本地路径
img_path = './test/' + img_name
with open(img_path,'wb') as f:
f.write(img_data)
print(img_name + '下载成功!')运行结果:
发现还有一个杂数据进入了导致报错
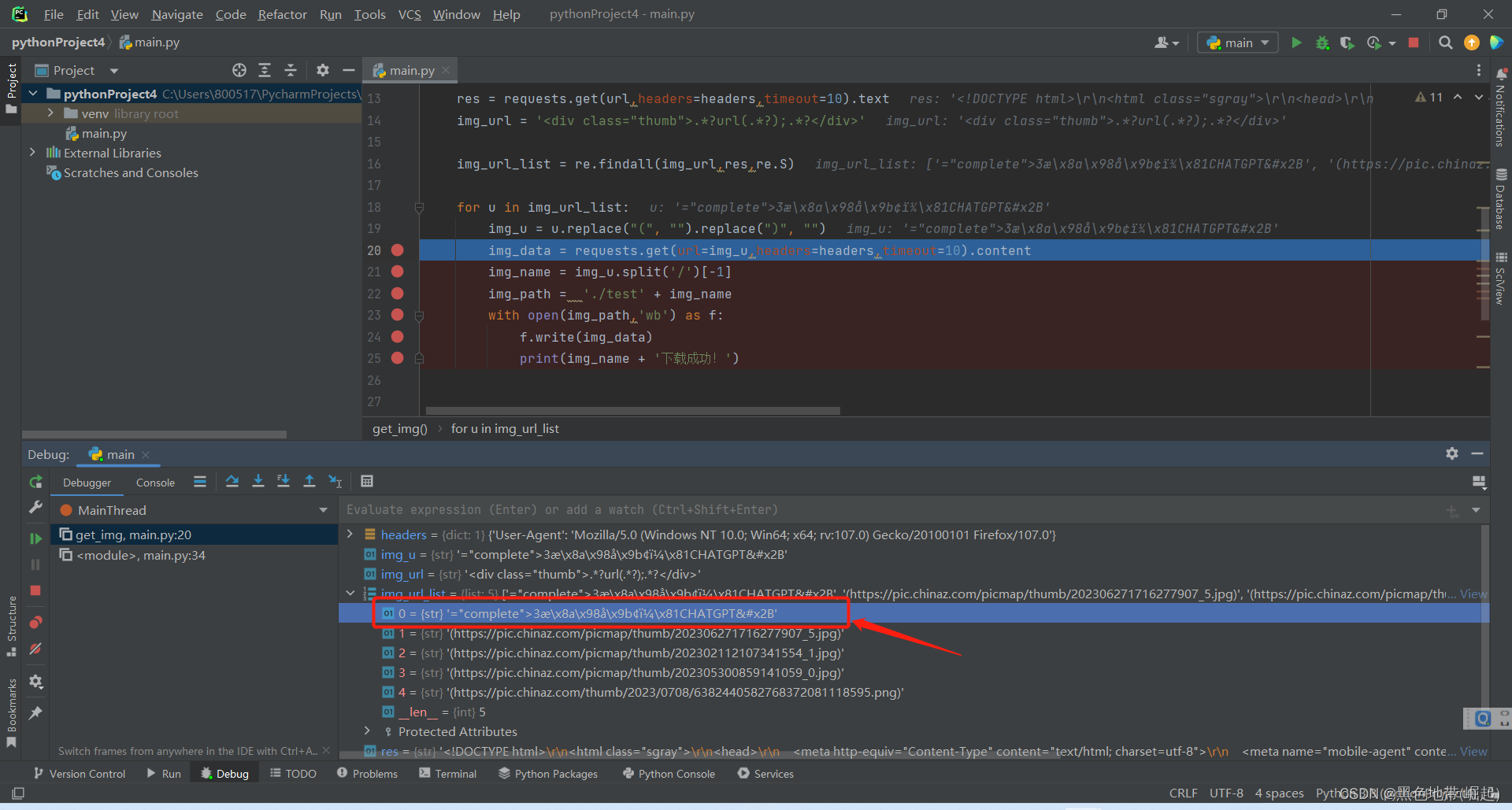
然后我果断加了一个if判断语句
if re.match(r'https?://', u):

最后下载成功了
完整代码:
import re
import requests
import os
def get_img():
url = 'https://www.chinaz.com/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:107.0) Gecko/20100101 Firefox/107.0",
}
res = requests.get(url, headers=headers, timeout=10).text
img_url = r'<div class="thumb">.*?url\((.*?)\);.*?</div>'
img_url_list = re.findall(img_url, res, re.S)
for u in img_url_list:
if re.match(r'https?://', u):
img_u = u.replace("(", "").replace(")", "")
img_data = requests.get(url=img_u, headers=headers, timeout=10).content
img_name = img_u.split('/')[-1]
img_path = './test/' + img_name
with open(img_path, 'wb') as f:
f.write(img_data)
print(img_name + '下载成功!')
else:
continue
if __name__ == '__main__':
if not os.path.exists('./test'):
os.makedirs('./test')
get_img()四、网络安全小圈子
GitHub - BLACKxZONE/Treasure_knowledge![]() https://github.com/BLACKxZONE/Treasure_knowledge
https://github.com/BLACKxZONE/Treasure_knowledge