目录
一、多线程分析:
当涉及到多线程爬虫数据包时,有几个流行的Python库可以用来构建强大的多线程爬虫。
实现功能:
使用requests库发送HTTP请求并获取响应数据。
使用beautifulsoup4库解析HTML或XML响应内容。
使用threading模块创建和管理线程。
使用queue模块创建任务队列,用于存储待爬取的URL。
使用互斥锁 (Lock) 进行线程同步,避免数据竞争。
示例代码:
import requests
from bs4 import BeautifulSoup
import threading
from queue import Queue
# 创建任务队列
url_queue = Queue()
# 设置要爬取的URL列表
urls = ['http://example.com/page1', 'http://example.com/page2', 'http://example.com/page3']
# 将URL加入任务队列
for url in urls:
url_queue.put(url)
# 互斥锁
lock = threading.Lock()
# 爬取函数
def crawl():
while True:
# 从队列中获取URL
url = url_queue.get()
# 发送HTTP请求
response = requests.get(url)
# 解析HTML响应
soup = BeautifulSoup(response.text, 'html.parser')
# 在这里进行你需要的数据提取和处理操作
# ...
# 使用互斥锁输出结果
with lock:
print(f"URL: {url}, Data: {data}")
# 标记任务完成
url_queue.task_done()
# 创建并启动多个线程
num_threads = 4 # 设置线程数量
for _ in range(num_threads):
t = threading.Thread(target=crawl)
t.daemon = True # 设置为守护线程
t.start()
# 阻塞,直到队列中的所有任务完成
url_queue.join()
上述代码创建了一个具有多个线程的爬虫,每个线程从任务队列中获取URL并进行爬取操作。注意,在实际使用中,您可能需要根据实际情况进行适当的修改和优化,比如添加异常处理、设置合理的线程数量等。

二、代码实现
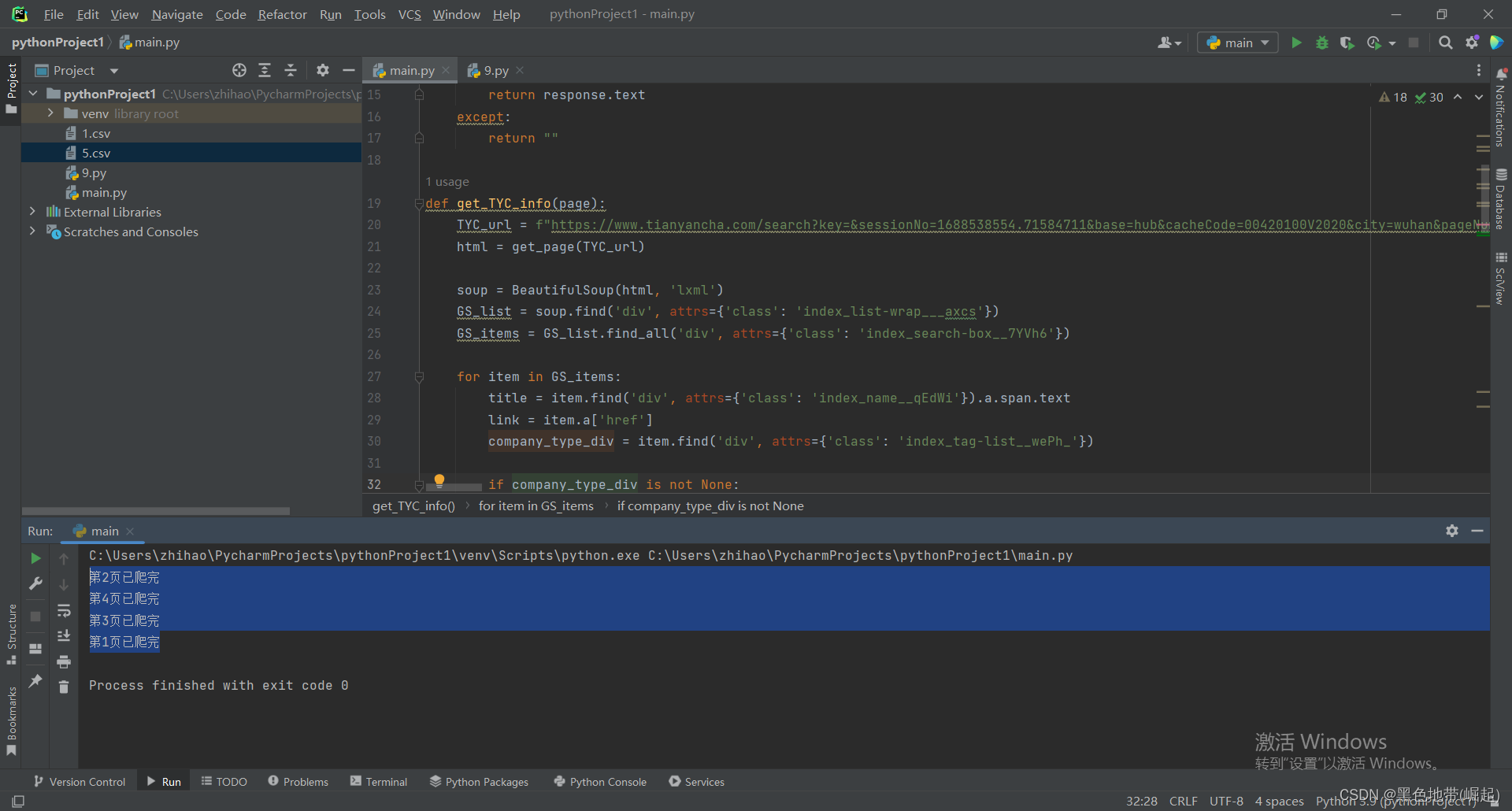
运行结果
爬取完成,可以看见爬取的页数也不是按照顺序来的,因为他是多线程
单账号/ip多线程的后果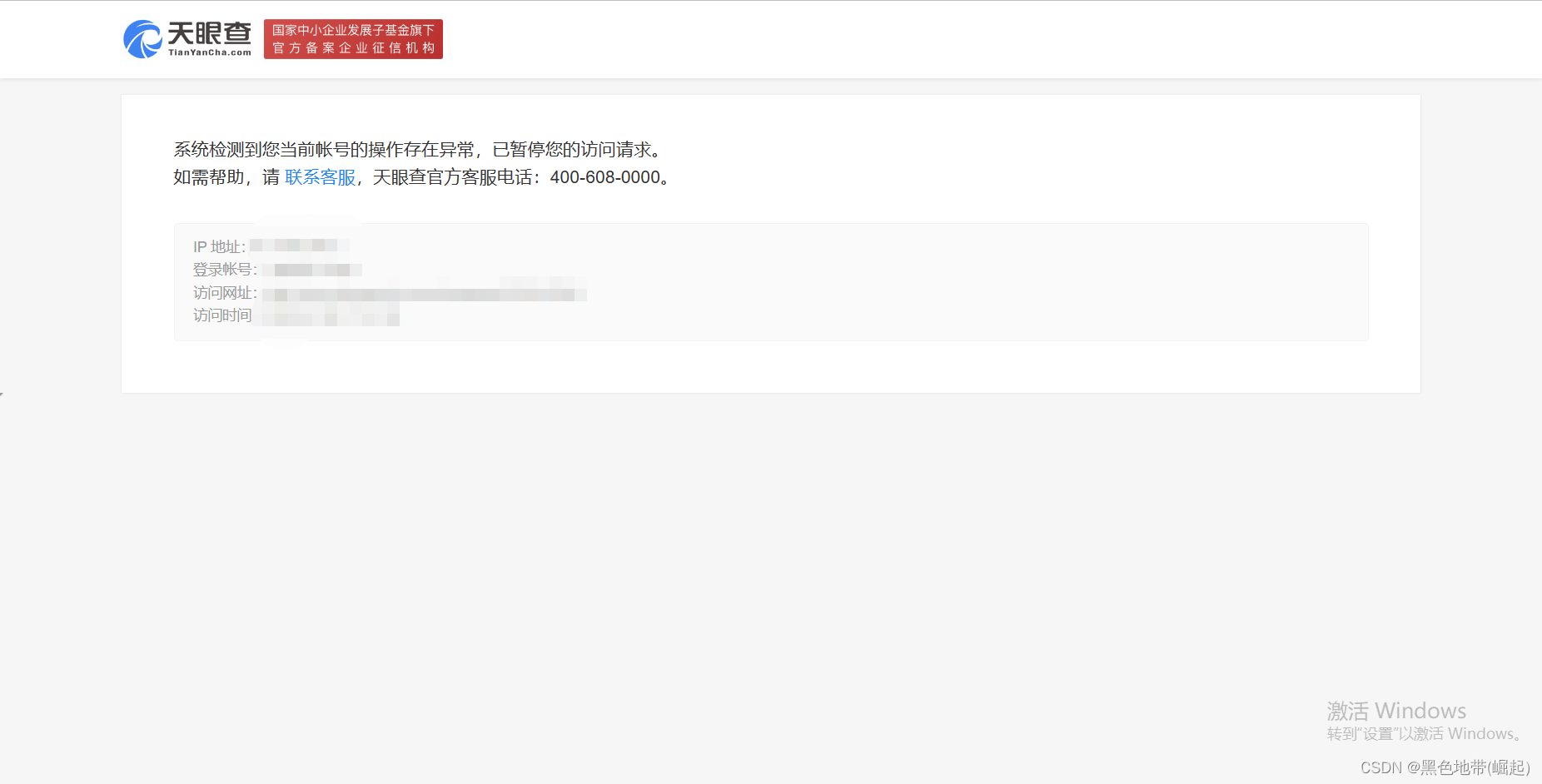
目标1:创建对象锁
所定义的位置,保证操作资源时能使用到这个锁
csv_lock = threading.Lock()创建一个线程锁对象csv_lock。线程锁用于保护共享资源,确保在同一时间只有一个线程可以访问该资源,避免出现竞态条件
目标2:实现操作资源时锁定资源
在操作对象的前后实现锁定和释放
csv_lock.acquire()
csv_w.writerow((title.strip(), link, type_texts, money, email, phone))
csv_lock.release()(1)csv_lock.acquire():获取线程锁,表示当前线程要开始对共享资源进行操作,其他线程需要等待
(2)csv_w.writerow((title.strip(), link, type_texts, money, email, phone)):对共享资源进行操作,这里是向CSV文件中写入一行数据。csv_w是一个CSV写入器对象,writerow()方法用于写入一行数据,参数是一个元组,元组中的每个元素对应一列的数据
(3)csv_lock.release():释放线程锁,表示当前线程已经完成对共享资源的操作,其他线程可以继续竞争获取锁
目标3:实现多线程
threads = []
for page in range(1, 5):
thread = threading.Thread(target=crawl_page, args=(page,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()(1)threads = []:创建一个空列表threads,用于存放创建的线程对象
(2)for page in range(1, 5)::通过循环迭代,page依次取值为1、2、3、4,表示要爬取的页码。这里假设要爬取4页的内容。
(3)thread = threading.Thread(target=crawl_page, args=(page,)):创建一个线程对象thread,指定要执行的函数为crawl_page,并传入参数page。
(4)threads.append(thread):将创建的线程对象thread添加到列表threads中,用于后续操作。
(5)thread.start():启动线程,使其开始执行crawl_page函数。
(6)for thread in threads::通过循环遍历列表threads中的线程对象。
(7)thread.join():调用线程对象的join()方法,让主线程等待该线程执行完毕。这样可以确保所有线程都执行完毕后再继续执行后续的代码
代码实现:
注:填上自己的cookie
(不填cookie有一定的机会可能爬到)
import time
import requests
import csv
from bs4 import BeautifulSoup
import threading
def get_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/44.0.2403.89 Chrome/44.0.2403.89 Safari/537.36',
'Cookie':'!!!!!!!!!!!!!'
}
response = requests.get(url, headers=headers, timeout=10)
return response.text
except:
return ""
def get_TYC_info(page):
TYC_url = f"https://www.tianyancha.com/search?key=&sessionNo=1688538554.71584711&base=hub&cacheCode=00420100V2020&city=wuhan&pageNum={page}"
html = get_page(TYC_url)
soup = BeautifulSoup(html, 'lxml')
GS_list = soup.find('div', attrs={'class': 'index_list-wrap___axcs'})
GS_items = GS_list.find_all('div', attrs={'class': 'index_search-box__7YVh6'})
for item in GS_items:
title = item.find('div', attrs={'class': 'index_name__qEdWi'}).a.span.text
link = item.a['href']
company_type_div = item.find('div', attrs={'class': 'index_tag-list__wePh_'})
if company_type_div is not None:
company_type = company_type_div.find_all('div', attrs={'class': 'index_tag-common__edIee'})
type_texts = [element.text for element in company_type]
else:
type_texts = ''
money = item.find('div', attrs={'class': 'index_info-col__UVcZb index_narrow__QeZfV'}).span.text
for u in [link]:
html2 = get_page(u)
soup2 = BeautifulSoup(html2, 'lxml')
email_phone_div = soup2.find('div', attrs={'class': 'index_detail__JSmQM'})
if email_phone_div is not None:
phone_div = email_phone_div.find('div', attrs={'class': 'index_first__3b_pm'})
email_div = email_phone_div.find('div', attrs={'class': 'index_second__rX915'})
if phone_div is not None:
phone_element = phone_div.find('span', attrs={'class': 'link-hover-click'})
if phone_element is not None:
phone = phone_element.find('span',attrs={'class':'index_detail-tel__fgpsE'}).text
else:
phone = ''
else:
phone = ''
if email_div is not None:
email_element = email_div.find('span', attrs={'class': 'index_detail-email__B_1Tq'})
if email_element is not None:
email = email_element.text
else:
email = ''
else:
email = ''
else:
phone = ''
email = ''
csv_lock.acquire()
csv_w.writerow((title.strip(), link, type_texts, money, email, phone))
csv_lock.release()
def crawl_page(page):
get_TYC_info(page)
print(f'第{page}页已爬完')
if __name__ == '__main__':
with open('5.csv', 'a', encoding='utf-8', newline='') as f:
csv_w = csv.writer(f)
csv_w.writerow(('公司名', 'URL', '类型', '资金', '电子邮件', '电话号码'))
csv_lock = threading.Lock()
threads = []
for page in range(1, 5):
thread = threading.Thread(target=crawl_page, args=(page,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
time.sleep(2)
三、网络安全小圈子
GitHub - BLACKxZONE/Treasure_knowledge![]() https://github.com/BLACKxZONE/Treasure_knowledge
https://github.com/BLACKxZONE/Treasure_knowledge