一、介绍
Prometheus提供了本地存储(TSDB)时序型数据库的存储方式,在2.0版本之后,压缩数据的能力得到了大大的提升(每个采样数据仅仅占用3.5byte左右空间),单节点情况下可以满足大部分用户的需求,但本地存储阻碍了prometheus集群化的实现,因此在集群中应当采用 其他时序性数据来替代,比如influxdb。
Prometheus分为三个部分,分别是:抓取数据、存储数据和查询数据。
在早期有一个单独的项目叫做 TSDB,但是,在2.1.x的某个版本,已经不单独维护这个项目了,直接将这个项目合并到了prometheus的主干上了。
Prometheus存储缺陷:
- 不支持跨集群聚合
- 比如,当前我们K8S的环境,应用可能部署在多个集群,这样就会创建多个prometheus实例(项目+集群创建一个Prometheus实例),假设每个集群都有QPS这个指标,我现在想对三个集群的QPS进行求平均(这是很正常的需求),则无法去做到,需要你自己代码中封装下
- 解决:可通过部署联邦集群解决
- 不支持长时间的存储(我们默认qke存储90天)
二、Promretheus 长期存储方案
来源:教你通俗易懂学会长期存储Prometheus主流技术_JKX_geek的博客-CSDN博客
在 Prometheus 长期存储出现之前,用户若需要跨集群聚合计算数据时,社区提供 Federation 方式实现。
在多个 Prometheus 实例的上一层有一个 Global Prometheus,它负责在各个实例中抓取数据并进行计算,以此解决跨集群聚合计算的问题。但如果各个集群的数据量较大,单实例的 GlobalPrometheus 也会遇到瓶颈。

2017 年,Prometheus 加⼊ Remote Read/Write API,自此之后社区涌现出大量长期存储的方案,如 Thanos、Grafana Cortex/Mimir、VictoriaMetrics、Wavefront、Splunk、Sysdig、SignalFx、InfluxDB、Graphite 等。
目前 Prometheus 社区也提供了部分对于第三方数据库的 Remote Storage 支持:

总结:
- 数据持久化到硬盘的方案里,VictoriaMetrics 是更好的选择,但需要注意的是 VictoriaMetrics 并没有开源 Downsampling 降采样功能,如需跨较长时间范围进行聚合及查询,耗时会比较久。
- 数据持久化到对象存储的方案中,Thanos 更受欢迎,Grafana Mimir 更有潜力。
- Thanos可以不使用对象存储,用本地盘存数据(Cortex/Mimir 待验证)。
- Grafana Fork了Cortex,创建了 Mimir 并修改 License 为 AGPL-3.0。后续 Grafana 及社区的投⼊程度成疑,不建议继续采用 Cortex。
- Thanos/Cortex/Mimir 互相借鉴,架构类似。Cortex/Mimir 借鉴了 Thanos 的对象存储访问及持久化。Thanos 借鉴了 Cortex 的 QueryFrontend。Mimir 作为 Grafana Cloud 的开源版本,其基于 Thanos 和 Cortex 的架构做了更多的优化。
总体来说,在不介意许可证的情况下,可以采⽤ Mimir,若在意更宽松许可证,CNCF 孵化项目的 Thanos 是更好的选择。
没有对象存储,推荐使用 VictoriaMetrics(有些重要功能没开源),有对象存储尽量用 Thanos 或 Mimir。
没有特殊原因尽量不要采用 M3。
三、Grafana Mimir
来源:【Grafana】Grafana Mimir在海量时间序列指标中的优化_风灵动铭的博客-CSDN博客
Grafan给出了一些使用Mimir的原因:
- 100%和prometheus兼容;
- 多副本高可用
- 水平拓展、分片实现快速查询
- 多租户及资源隔离
- 分布式架构,动态拓展
由于 Grafana Mimir Fork 了 Cortex,所以其架构和 Cortex 及 Thanos 非常相似。
虽然 Grafana Mimir 同样借鉴了 Thanos 的 store-gateway、compactor 和 ruler,但与 Cortex 不同之处在于 querier 和 query frontend 之间加了一个额外的组件 query scheduler,更好地满足了查询组件的可扩展性。
Mimir 各组件(包括 compactor、store-gateway、query、ruler 等)的水平可扩展性较好,值得一提的是 Mimir 对 Alertmanage 做了多租户和水平扩展的支持。
弊端:
- 许可证:Grafana Mimir是基于AGPL v3 许可证,不够友好,因为该许可证要求:如果项目引入了此开源组件且修改了源代码,那么你的软件也得开源
- 性能相关未得到充分验证、开源时间较晚
四、VictoriaMetrics
来源:
使用VictoriaMetrics 对Prometheus的数据进行分布式存储_叱咤少帅(少帅)的博客-CSDN博客
为什么要用时序数据库,influxDB 和 VictoriaMetrics 谁才是王者?_victoriametrics 和influxdb 哪一个比较好_surfirst的博客-CSDN博客
介绍
VictoriaMetrics是一个快速、高效和可扩展的时序数据库,可作为prometheus的长期存储。
VictoriaMetrics有如下优点:
- 提供高数据压缩
- 与 Prometheus、Thanos 或 Cortex 相比,所需的存储空间最多减少 7 倍。
- 光速查询
- 它有效地利用所有可用的 CPU 内核进行每秒数十亿行的并行处理。
- 它比 InfluxDB 和 TimescaleDB 高出 20 倍。
- 提供全局查询视图
- 多个 Prometheus 实例或任何其他数据源可能会将数据提取到 VictoriaMetrics。稍后可以通过单个查询查询此数据。
- 更低内存使用率
- 它使用的 RAM 比 InfluxDB 少 10 倍 ,比 Prometheus、Thanos 或 Cortex 少 7 倍。
- VictoriaMetrics 是 Prometheus 长期存储的理想解决方案
- 它实现了类似 PromQL 的查询语言——MetricsQL ,它在 PromQL 之上提供了改进的功能。
组件
集群版的victoriametrics有3类进程,即3类微服务组成:
- vmstorage: 数据存储节点,负责存储时序数据;
- vmselect: 数据查询节点,负责接收用户查询请求,向vmstorage查询时序数据;
- 无状态,可横向扩展
- vminsert: 数据插入节点,负责接收用户插入请求,向vmstorage写入时序数据;
- 无状态,可横向扩展
在部署时可以按照需求,不同的微服务部署不同的副本,以应对业务需求:
- 若数据量比较大,部署较多的vmstorage副本;
- 若查询请求比较多,部署较多的vmselect副本;
- 若插入请求比较多,部署较多的vminsert副本;
部署
单节点版
直接运行一个二进制文件,既可以运行,官方建议采集数据点(data points)低于100w/s,推荐VM单节点版,简单好维护,但不支持告警。
集群版
支持数据水平拆分,把功能拆分为vmstorage、 vminsert、vmselect,如果要替换Prometheus,还需要vmagent、vmalert。
集群版主要特点:
- 支持单节点版本的所有功能。
- 性能和容量水平扩展。
- 支持时间序列数据的多个独立命名空间(多租户)。
- 支持多副本。
- 图表功能比Proms强大
架构
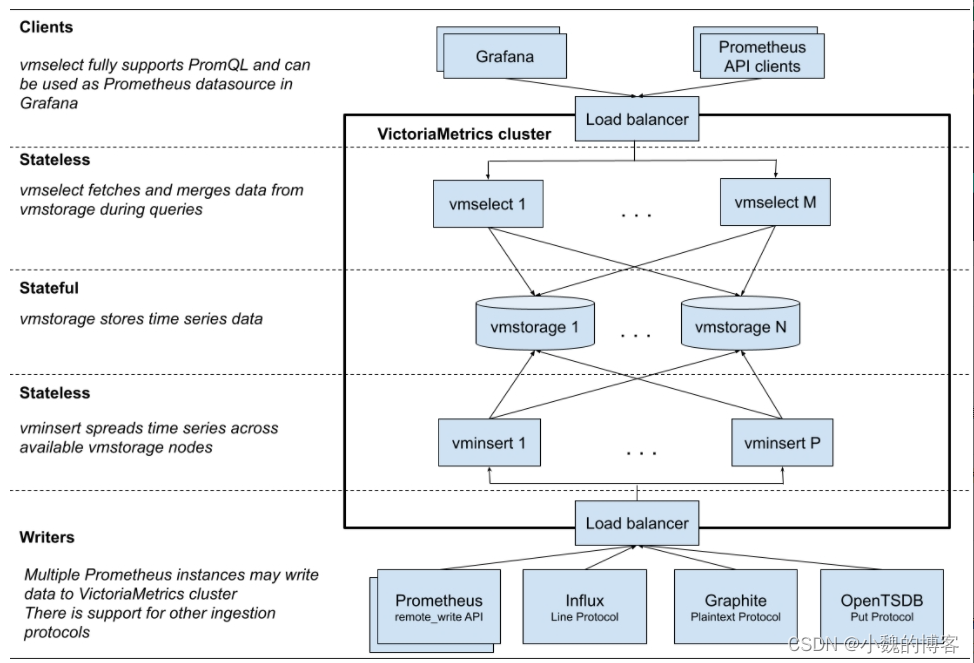
VictoriaMetrics查询数据
来源:prometheus - VictoriaMetrics集群原理 - 个人文章 - SegmentFault 思否
以PromQL查询数据为例,结合源码分析victoriametrics集群版本查询数据数据的流程。
查询数据在vmselect服务中处理,假设--replicationFactor=2,即数据副本=2:

五、Prometheus 集群与高可用
来源:【Prometheus】Prometheus 集群与高可用_prometheus集群_Young丶的博客-CSDN博客
Prometheus内置了一个基于本地存储的时间序列数据库。在Prometheus设计上,使用本地存储可以降低Prometheus部署和管理的复杂度同时减少高可用(HA)带来的复杂性。
在默认情况下,用户只需要部署多套Prometheus,采集相同的Targets即可实现基本的HA。同时由于Promethus高效的数据处理能力,单个Prometheus Server基本上能够应对大部分用户监控规模的需求。
当然本地存储也带来了一些不好的地方:
- 首先:就是数据持久化的问题,特别是在像Kubernetes这样的动态集群环境下,如果Promthues的实例被重新调度,那所有历史监控数据都会丢失。
- 其次:本地存储也意味着Prometheus不适合保存大量历史数据(一般Prometheus推荐只保留几周或者几个月的数据)。最后本地存储也导致Prometheus无法进行弹性扩展。
为了适应这方面的需求,Prometheus提供了remote_write和remote_read的特性,支持将数据存储到远端和从远端读取数据。通过将监控与数据分离,Prometheus能够更好地进行弹性扩展。
除了本地存储方面的问题,由于Prometheus基于Pull模型,当有大量的Target需要采样本时,单一Prometheus实例在数据抓取时可能会出现一些性能问题。
- 联邦集群的特性可以让Prometheus将样本采集任务划分到不同的Prometheus实例中,并且通过一个统一的中心节点进行聚合,从而可以使Prometheuse可以根据规模进行扩展。
远程存储
Prometheus的本地存储设计可以减少其自身运维和管理的复杂度,同时能够满足大部分用户监控规模的需求。但是本地存储也意味着Prometheus无法持久化数据,无法存储大量历史数据,同时也无法灵活扩展和迁移。
为了保持Prometheus的简单性,Prometheus并没有尝试在自身中解决以上问题,而是通过定义两个标准接口(remote_write/remote_read),让用户可以基于这两个接口对接将数据保存到任意第三方的存储服务中,这种方式在Promthues中称为Remote Storage。
Remote Write
用户可以在Prometheus配置文件中指定Remote Write(远程写)的URL地址,一旦设置了该配置项,Prometheus将采集到的样本数据通过HTTP的形式发送给适配器(Adaptor)。而用户则可以在适配器中对接外部任意的服务。外部服务可以是真正的存储系统,公有云的存储服务,也可以是消息队列等任意形式。
Remote Read
Promthues的Remote Read(远程读)也通过了一个适配器实现。在远程读的流程当中,当用户发起查询请求后,Promthues将向remote_read中配置的URL发起查询请求(matchers,ranges),Adaptor根据请求条件从第三方存储服务中获取响应的数据。同时将数据转换为Promthues的原始样本数据返回给Prometheus Server。
联邦集群
通过Remote Storage可以分离监控样本采集和数据存储,解决Prometheus的持久化问题。
这一部分会重点讨论如何利用联邦集群特性对Promthues进行扩展,以适应不同监控规模的变化。
对于大部分监控规模而言,我们只需要在每一个数据中心(例如:EC2可用区,Kubernetes集群)安装一个Prometheus Server实例,就可以在各个数据中心处理上千规模的集群。同时将Prometheus Server部署到不同的数据中心可以避免网络配置的复杂性。
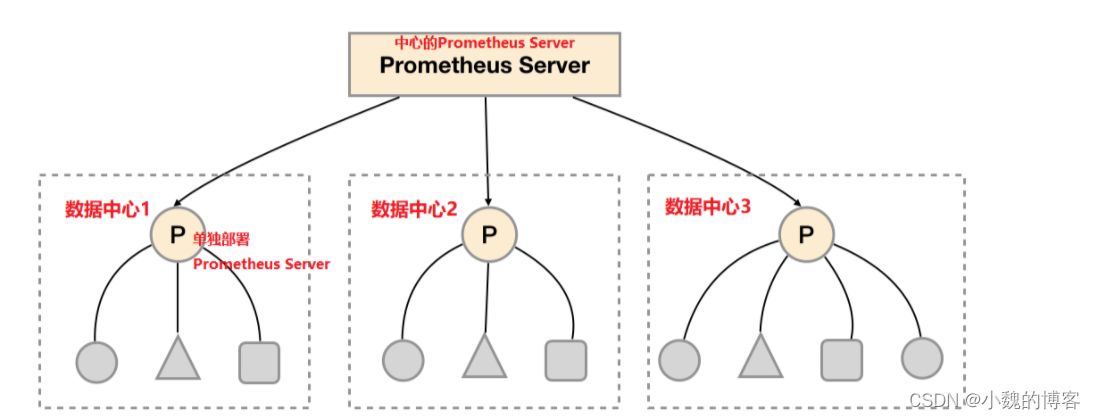
如上图所示,在每个数据中心部署单独的Prometheus Server,用于采集当前数据中心监控数据。并由一个中心的Prometheus Server负责聚合多个数据中心的监控数据。这一特性在Promthues中称为联邦集群。
联邦集群的核心在于每一个Prometheus Server都包含一个用于获取当前实例中监控样本的接口/federate。对于中心Prometheus Server而言,无论是从其他的Prometheus实例还是Exporter实例中获取数据实际上并没有任何差异。
scrape_configs:
- job_name: 'federate'
scrape_interval: 15s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job="prometheus"}'
- '{__name__=~"job:.*"}'
- '{__name__=~"node.*"}'
static_configs:
- targets:
- '192.168.77.11:9090'
- '192.168.77.12:9090'联邦集群的特性可以帮助用户根据不同的监控规模对Promthues部署架构进行调整。例如如下所示,可以在各个数据中心中部署多个Prometheus Server实例。每一个Prometheus Server实例只负责采集当前数据中心中的一部分任务(Job),例如可以将不同的监控任务分离到不同的Prometheus实例当中,再有中心Prometheus实例进行聚合。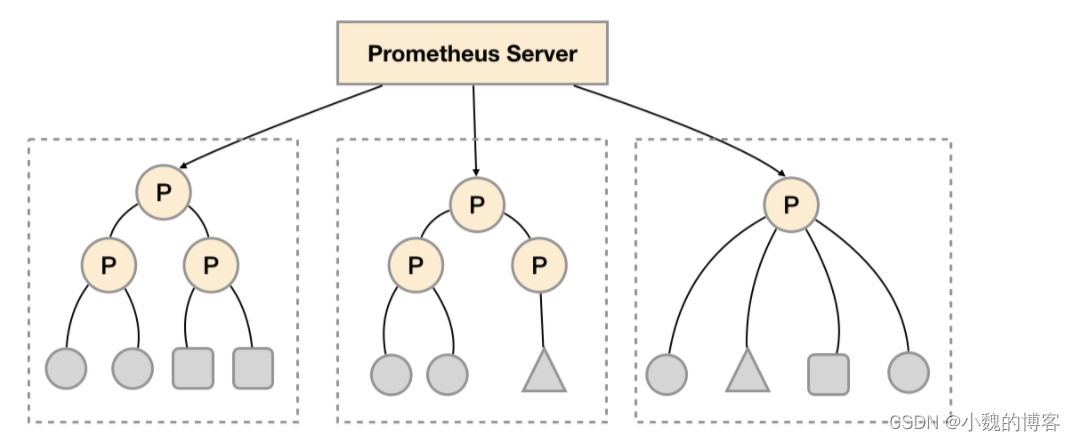
功能分区,即通过联邦集群的特性在任务级别对Prometheus采集任务进行划分,以支持规模的扩展。
联邦集群适用场景:
- 场景一:单数据中心 + 大量的采集任务
- 这种场景下Promthues的性能瓶颈主要在于大量的采集任务,因此用户需要利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Promthues子服务中,从而实现功能分区。
- 场景二:多数据中心
- 当Promthues Server无法直接与数据中心中的Exporter进行通讯时,可用联邦
- 场景三:数据聚合
- 当一个应用部署到多个Prometheus集群时,需要查询应用数据时,需要对数据进行聚合
Prometheus高可用总结
Prometheus的本地存储给Prometheus带来了简单高效的使用体验,可以让Promthues在单节点的情况下满足大部分用户的监控需求。
但是本地存储也同时限制了Prometheus的可扩展性,带来了数据持久化等一系列的问题。通过Prometheus的Remote Storage特性可以解决这一系列问题,包括Promthues的动态扩展,以及历史数据的存储。
而除了数据持久化问题以外,影响Promthues性能表现的另外一个重要因素就是数据采集任务量,以及单台Promthues能够处理的时间序列数。因此当监控规模大到Promthues单台无法有效处理的情况下,可以选择利用Promthues的联邦集群的特性,将Promthues的监控任务划分到不同的实例当中。
- 用户只需要部署多套Prometheus,采集相同的Targets即可实现基本的HA
- 通过Prometheus的Remote Storage特性可以解决数据持久化与Prometheus的可扩展性
- 利用联邦集群特性对Promthues进行扩展,监控处理大规模数据量,实现Promthues数据处理能力无限提升
这一部分将重点讨论Prometheus的高可用架构,并且根据不同的使用场景介绍了一种常见的高可用方案。
六、案例
我们的prometheus目前申请了三个文件系统NFS,托管集群存在一个文件系统,QKE集群存在另一个文件系统,单都是存储到云端(StorageClass)。
存储的方式:每个prometheus实例对应一个目录,如果有多个prometheus实例,则对应多个目录。
另外,注意,每个文件系统对应一个StorageClass自由对象。
以prometheus托管集群为例,如下是创建StorageClass
关键的两个文件:
创建StorageClass资源对象:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: prometheus-data-03
provisioner: prometheus-data-03/nfs
reclaimPolicy: Retain
创建StorageClass后,还需要K8S存储插件进行真正的存储工作:
nfs-client-provisioner 可动态为kubernetes提供pv卷,是Kubernetes的简易NFS的外部provisioner,本身不提供NFS,需要现有的NFS服务器提供存储。持久卷目录的命名规则为:${namespace}-${pvcName}-${pvName}。
树莓派k8s集群安装nfs-client-provisioner_崔一凡的技术博客_51CTO博客
kind: Deployment
apiVersion: apps/v1
metadata:
name: nfs-provisioner-03
spec:
selector:
matchLabels:
app: nfs-provisioner-03
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-provisioner-03
spec:
serviceAccount: nfs-provisioner
containers:
- name: nfs-provisioner
image: docker-registry.xxx.virtual/hubble/nfs-client-provisioner:v3.1.0-k8s1.11
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: prometheus-data-03/nfs
- name: NFS_SERVER
value: hubble-587ceb02-5e85e802.cnhz1.qfs.xxx.storage
- name: NFS_PATH
value: /hubble-wuhan-lkg
volumes:
- name: nfs-client-root
nfs:
server: hubble-587ceb02-5e85e802.cnhz1.qfs.xxx.storage
path: /hubble-wuhan-lkg
上面的server地址其实就是云存储那边提供的地址:
部署prometheus:
kind: Service
apiVersion: v1
metadata:
name: prometheus-headless
namespace: example-nfs
labels:
app.kubernetes.io/name: prometheus
spec:
type: ClusterIP
clusterIP: None
selector:
app.kubernetes.io/name: prometheus
ports:
- name: web
protocol: TCP
port: 9090
targetPort: web
- name: grpc
port: 10901
targetPort: grpc
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: example-nfs
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus-example-nfs
subjects:
- kind: ServiceAccount
name: prometheus
namespace: example-nfs
roleRef:
kind: ClusterRole
name: prometheus
apiGroup: rbac.authorization.k8s.io
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: prometheus
namespace: example-nfs
labels:
app.kubernetes.io/name: prometheus
spec:
serviceName: prometheus-headless
podManagementPolicy: Parallel
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: prometheus
template:
metadata:
labels:
app.kubernetes.io/name: prometheus
spec:
serviceAccountName: prometheus
securityContext:
fsGroup: 1000
runAsUser: 0
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: In
values:
- prometheus
topologyKey: kubernetes.io/hostname
containers:
- name: prometheus
image: docker-registry.xxx.virtual/hubble/prometheus:v2.34.0
args:
- --config.file=/etc/prometheus/config_out/prometheus.yaml
- --storage.tsdb.path=/prometheus
- --storage.tsdb.retention.time=30d
- --web.external-url=/example-nfs/prometheus
- --web.enable-lifecycle
- --storage.tsdb.no-lockfile
- --storage.tsdb.min-block-duration=2h
- --storage.tsdb.max-block-duration=1d
ports:
- containerPort: 9090
name: web
protocol: TCP
livenessProbe:
failureThreshold: 6
httpGet:
path: /example-nfs/prometheus/-/healthy
port: web
scheme: HTTP
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 3
readinessProbe:
failureThreshold: 120
httpGet:
path: /example-nfs/prometheus/-/ready
port: web
scheme: HTTP
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 3
resources:
requests:
memory: 1Gi
limits:
memory: 30Gi
volumeMounts:
- mountPath: /etc/prometheus/config_out
name: prometheus-config-out
readOnly: true
- mountPath: /prometheus
name: prometheus-storage
- mountPath: /etc/prometheus/rules
name: prometheus-rules
- name: thanos
image: docker-registry.xxx.virtual/hubble/thanos:v0.25.1
args:
- sidecar
- --tsdb.path=/prometheus
- --prometheus.url=http://127.0.0.1:9090/example-nfs/prometheus
- --reloader.config-file=/etc/prometheus/config/prometheus.yaml.tmpl
- --reloader.config-envsubst-file=/etc/prometheus/config_out/prometheus.yaml
- --reloader.rule-dir=/etc/prometheus/rules/
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
ports:
- name: http-sidecar
containerPort: 10902
- name: grpc
containerPort: 10901
livenessProbe:
httpGet:
port: 10902
path: /-/healthy
readinessProbe:
httpGet:
port: 10902
path: /-/ready
volumeMounts:
- name: prometheus-config-tmpl
mountPath: /etc/prometheus/config
- name: prometheus-config-out
mountPath: /etc/prometheus/config_out
- name: prometheus-rules
mountPath: /etc/prometheus/rules
- name: prometheus-storage
mountPath: /prometheus
volumes:
- name: prometheus-config-tmpl
configMap:
defaultMode: 420
name: prometheus-config-tmpl
- name: prometheus-config-out
emptyDir: {}
- name: prometheus-rules
configMap:
name: prometheus-rules
volumeClaimTemplates:
- metadata:
name: prometheus-storage
labels:
app.kubernetes.io/name: prometheus
spec:
storageClassName: prometheus-data-03
accessModes:
- ReadWriteOnce
volumeMode: Filesystem
resources:
requests:
storage: 100Gi
limits:
storage: 300Gi
--storage.tsdb.min-block-duration:控制数据落盘的时间,即最小落盘时间是2小时
--storage.tsdb.min-block-duration:控制数据落盘的时间,即最大落盘时间是1天
--storage.tsdb.retention.time配置本地保留30天数据,减少空间占用;
如上,volumeClaimTemplates即是定义一个PVC,如何创建PV呢?使用StorageClass定义的模板去创建PV。
那么prometheus查询数据的时候是怎么查的呢?
其实对于prometheus来说,就是从prometheus这个实例提供的接口查询数据而已,和普通的容器一样,不管是云存储还是node存储或是其他存储,对于容器来说是透明的,都是从挂载到的目录去查询,所以远端对于prometheus来说就是查本地的目录文件。
七、存储原理
prometheus将采集到的样本以时间序列的方式保存在内存(TSDB 时序数据库)中,并定时保存到硬盘中。
与zabbix不同,zabbix会保存所有的数据,而prometheus本地存储会保存15天,超过15天以上的数据将会被删除,若要永久存储数据,有两种方式:
- 方式一:修改prometheus的配置参数“storage.tsdb.retention.time=10000d”;
- 方式二:将数据远程存储到Influcdb、VictoriaMetrics等
- 方式三:降采样
prometheus按照block块的方式来存储数据,每2小时为一个时间单位,首先会存储到内存中,当到达2小时后,会自动写入磁盘中。
为防止程序异常而导致数据丢失,采用了WAL机制,即2小时内记录的数据存储在内存中的同时,还会记录一份日志,存储在block下的wal目录中。当程序再次启动时,会将wal目录中的数据写入对应的block中,从而达到恢复数据的效果。
当删除数据时,删除条目会记录在tombstones 中,而不是立刻删除。
prometheus采用的存储方式称为“时间分片”,每个block都是一个独立的数据库。优势是可以提高查询效率,查哪个时间段的数据,只需要打开对应的block即可,无需打开多余数据。
八、数据备份
1、完全备份
备份prometheus的data目录可以达到完全备份的目的,但效率较低。
2、快照备份
prometheus提供了一个功能,是通过API的方式,快速备份数据。实现方式:
- 首先,修改prometheus的启动参数,新增以下两个参数:
--storage.tsdb.path=/usr/local/share/prometheus/data \
--web.enable-admin-api- 然后,重启prometheus
- 最后,调用接口备份:
# 不跳过内存中的数据,即同时备份内存中的数据
curl -XPOST http://127.0.0.1:9090/api/v2/admin/tsdb/snapshot?skip_head=false
# 跳过内存中的数据
curl -XPOST http://127.0.0.1:9090/api/v2/admin/tsdb/snapshot?skip_head=trueskip_head作用:是否跳过存留在内存中还未写入磁盘中的数据,仍在block块中的数据, 默认是false
3、数据还原
利用api方式制作成snapshot后,还原时将snapshot中的文件覆盖到data目录下,重启prometheus即可!
添加定时备份任务(每周日3点备份)
crontable -e #注意时区,修改完时区后,需要重启 crontab systemctl restart cron
0 3 * * 7 sudo /usr/bin/curl -XPOST -I http://127.0.0.1:9090/api/v1/admin/tsdb/snapshot >> /home/bill/prometheusbackup.log