当前,深度学习已经应用到很多领域:无人驾驶汽车,黑科技以及图像分类等等,这些前沿的科技也面临许多挑战,如无人驾驶汽车需要进行物体的检测、行人的检测、标志的识别以及速度识别等等;图像分类已经成为一项重要技术,它是计算机视觉的核心任务,其困难之处在于图像中物体形状的改变、部分遮蔽以及背景的混入等等。让机器学习人类模拟人类大脑的思考过程,需要进行大量的实验研究才能正式投入运行,即将大量的数据分为训练集、验证集以及测试集。
深度学习的过程可以分为前向传播和反向传播两个过程,前向传播。
简单来说,前向传播过程就是数据从输入层传入,经过隐藏层,最终到达输出层的过程。如下图所示,图中包含一个输入层,一个隐藏层和一个输出层。
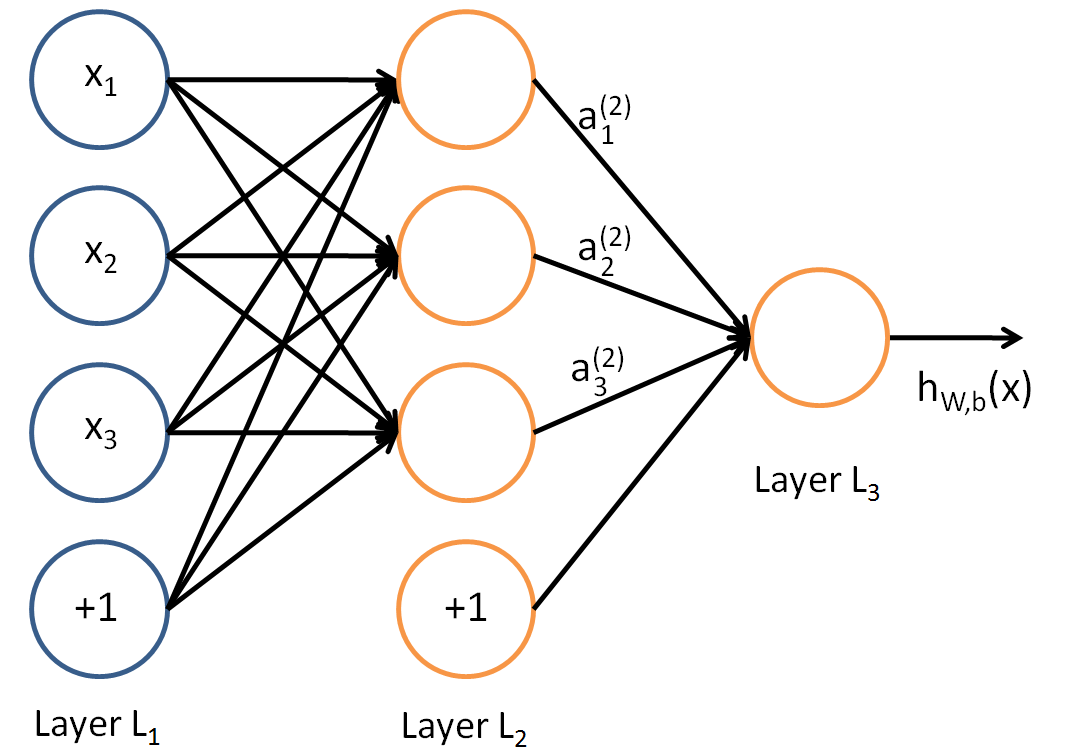
对于第2层第1个节点的输出有:
![]()
对于第3层第1个节点的输出有:

而反向传播的核心在于复合函数的链式求导法则,反向传播的作用在于优化代价函数,这也是训练神经网络的目标。
加法节点
类似于2+3=5,将常数换成变量 x+y=z,如下图所示,就是一个简单的前向传播和反向传播过程(右边的图是对应反向传播过程):

乘法节点
以 z=x*y 为例,如下图所示,就是一个简单的前向传播和反向传播过程(右边的图是对应反向传播过程):

加法的反向传播只是将上游的值传给下游,并不需要正向传播的输入信号。但是乘法的反向传播需要正向传播时的输入信号值。因此,实现乘法节点的反向传播时,要保存正向传播的输入信号。
从左向右进行计算是一种正方向上的传播,简称为正向传播 (forward propagation)。从右向左的传播称为反向传播 (backward propagation)。
计算图的反向传播:沿着与正方向相反的方向,乘上局部导数。
反向传播的计算顺序是:
将信号 E 乘以节点的局部导数 (∂ y/∂ x),然后将结果传递给下一个节点。这里所说的局部导数是指正向传播中y = f (x) 的导数,也就是 y 关于 x 的导数(∂ y/∂ x)。如 y = f ( x ) = x^2 则局部导数为(∂ y/∂ x) = 2x。把这个局部导数乘以 E,然后传递给前面的节点。这就是反向传播的计算顺序。通过这样的计算,可以高效地求出导数的值,这是反向传播的要点。
z=f(x,y) 求偏导数:
1)加法的偏导数
2)乘法的偏导数


举个例子:将乘法和加法组合起来。
物品a的单价是5,数量是8
物品b的单价是6,数量是5
物品的总价是多少?
5×8 + 6×5 = 70
代码如下:
class multiplication_layer:
def __init__(self):
self.x = None
self.y = None
def forward(self, x, y):
self.x = x
self.y = y
out = x * y
return out
def backward(self, d_out):
d_x = d_out * self.y
d_y = d_out * self.x
return d_x, d_y
class addition_layer:
def __init__(self):
pass
def forward(self, x, y):
out = x + y
return out
def backward(self, d_out):
d_x = d_out * 1
d_y = d_out * 1
return d_x, d_y
a_price = 5
a_num = 8
b_price = 6
b_num = 5
# layer
a_layer = multiplication_layer()
b_layer = multiplication_layer()
c_layer = addition_layer()
# forward
a_price = a_layer.forward(a_price, a_num) # (1)
b_price = b_layer.forward(b_price, b_num) # (2)
totoal_price = c_layer.forward(a_price, b_price) # (3)
# backward
d_price = 1
d_a_price, d_b_price = c_layer.backward(d_price) # (3)
d_b, d_b_num = b_layer.backward(d_b_price) # (2)
d_a, d_a_num = a_layer.backward(d_a_price) # (1)
print("totoal_price:", (totoal_price))
print("d_a:", d_a)
print("d_a_num:", (d_a_num))
print("d_b:", d_b)
print("d_b_num:", (d_b_num))
# totoal_price: 70
# d_a: 5
# d_a_num: 8
# d_b: 6
# d_b_num: 5
z=(x+y)^2 由两个式子构成:z = t^2 和 t = x+y
简单实现一个全连接层的前向传播和反向传播
全连接层是fully connected layer,类似的名词是affine或者linear
Y = W X + B
import numpy as np
N=1
X= np.random.random((N,2))
W= np.random.random((2,3))
B= np.random.random((3,))
Y = np.dot(X, W) + B
print(Y)


import numpy as np
class fully_connected_layer:
def __init__(self,W, B):
self.X = None
self.W = W
self.B = B
self.dx = None
self.dw = None
self.db = None
def forward(self, input):
self.X = input
out = np.dot(self.X, self.W) + self.B
return out
def backward(self, d_out):
self.dx = np.dot(d_out, self.W.T)
self.dw = np.dot(self.X.T,d_out)
self.db = np.sum(d_out, axis=0)
return self.dx
np.random.seed(2020)
N=2
input= np.random.random((N,2))
weight= np.random.random((2,3))
bias= np.random.random((3,))
print(input.shape)
print("input=\n",input)
print(weight.shape)
print("weight=\n",weight)
print(bias.shape)
print("bias=\n",bias)
linear = fully_connected_layer(W=weight,B=bias)
out = linear.forward(input)
print("out=\n",out)
d_out= np.random.random(out.shape)
dx = linear.backward(d_out)
dw = linear.dw
db = linear.db
print("dx=\n",dx)
print("dw=\n",dw)
print("db=\n",db)