系列文章主要目的快速厘清不同方法的原理差异和应用场景,
对于理论的细节请参考文末的Reference,
Reference中会筛选较为正确,细节的说明
Andrej Karpthy 离开Tesla之后加入OpenAI 首次的公开演讲,也是OpenAI首次对外公布chatGPT详细的技术细节(之前网路流传的版本多半是根据InstructionGPT而来)
以下我们直接按照完整的训练流程顺序介绍
Petraining
-
训练成本:预训练占用整体流程的99%的时间,也是成本最昂贵,门槛最高的阶段。下面展示了GPT3和LLaMA的训练时间和成本。2020年的GPT3就用了1000以上的V100,一个月以上的训练时间,花费将近100~1000万美元。非常惊人的一个数字

-
Tokenization:预训练还有一个重要任务,就是让大模型学会认字,俗称标记化(Tokenization), GPT和Bert系列不同,采用Byte Pair Encodeing(BPE) ,可以更弹性且有效的对单词或稀有词汇进行encoding,下图可以看到一个token平均对应0.75个单字

-
预训练方法:采用生成式预训练方法,给定上下文预测下一个token,与Bert的训练方式比较可以参考连结,
监督微调(Supervised Fintuning)
- 相比于预训练阶段(PLM)需要大量数据输入,SFT的阶段更多需要低数量高质量的人工打标数据,主要的目的是让PLM能够更精确理解用户的指令,更好的完成任务,以下是一个简单的示例:

Instruction的部分是表示人类希望模型遵从的指令,prompt是实际任务的请求,而Response是根据指令应该要生成的结果
- 这一阶段的训练成本开始大幅降低,大约一天左右的时间就可以完成训练,在很多场景下,这部份训练产生的模型已经可以在业务上使用
- 更多SFT细节的介绍请参考这篇:总结大模型微调方式
RLHF
在演讲中,RLHF的部分被拆成两个阶段:Reward Modeling以及Reinforcement Learning
Reward Modeling
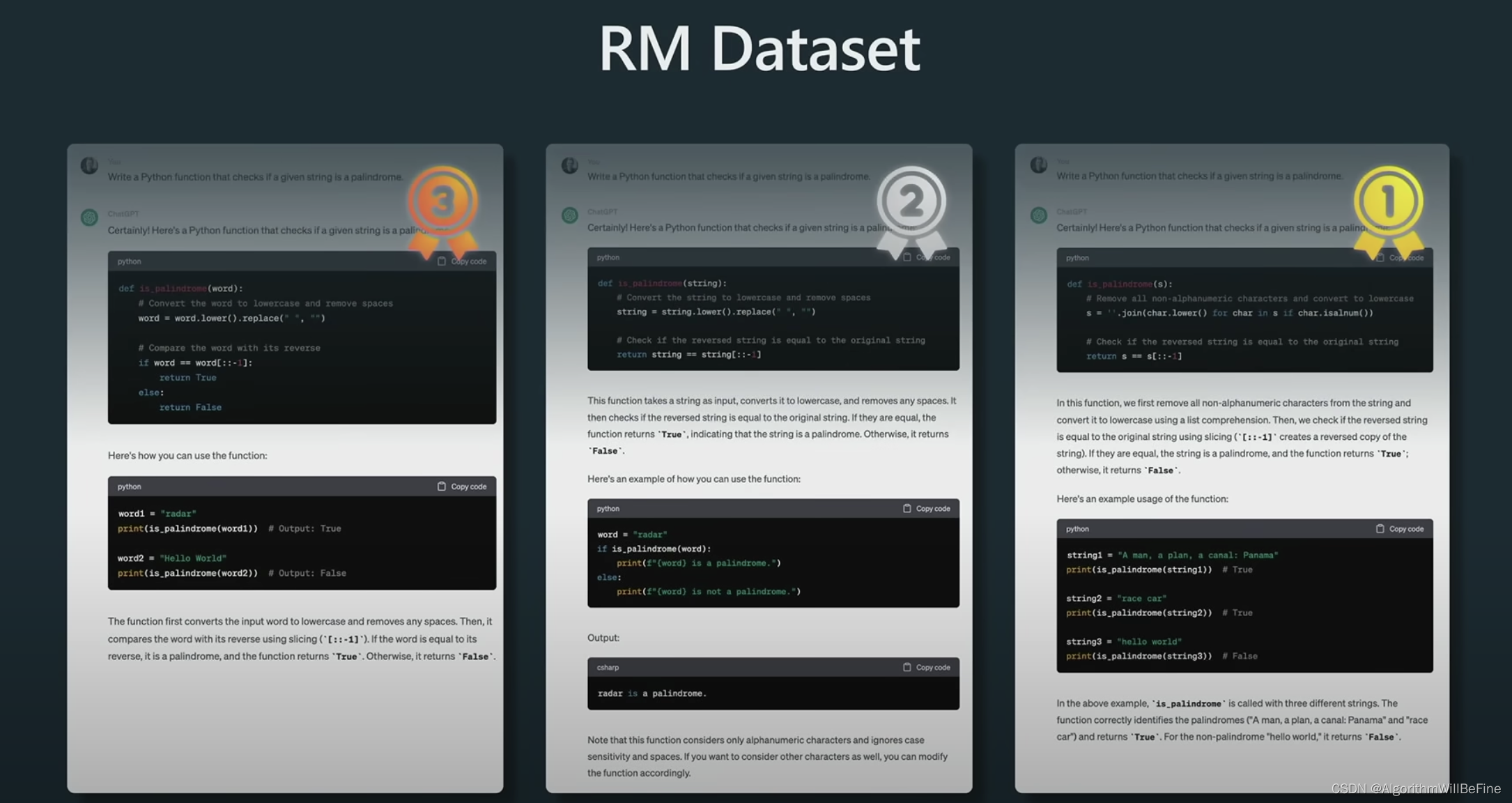
- Reward Modling的目标是要训练一个模型更接近人类的打分标准
- 这一阶段的训练模式也很简单,主要就是让模型生成多种可能的回答,让人类对于回答进行排序(类似图像生成领域MOS的评分方式),接著训练一个打分模型(Reward Modling)能够模仿人类进行两两比较,并产出尽可能接近人类的排序,以下是个简单的示例
- 为什么需要RLHF:Andrej Karpthy给出了一个比较通俗的解释:
It's eaiser to discriminate than to generate
对于任务难度越低,模型更容易训练出更好的效果
- 更多RLHF细节的介绍请参考这篇:总结大模型微调方式
对于RLHF和SFT结果的重要结论

Andrej Karpthy在演讲中给出了一个重要的比较,RLHF的过程会大幅降低模型生成结果的Entropy,也就是说对于同一个prompt,RLHF模型生成结果的多样性小于Base Model (PLM),但确定性更高,因此对于生成类的任务,比如创作,文章续写等任务,使用PLM可以获得多样的结果。
关于微调的一些Tips
- 基于SFT的微调,可以尝试使用类似LORA的PERF类方法进行微调,这样可以在大部分模型权重不变得情况,有效的对指定任务进行微调,但是对于数据集的收集和处理流程相对于prompt engingeer需要更多的专业知识以及更复杂的流程。
- RLHF目前来说还属于快速发展的阶段,整体的流程还属于非常不稳定的阶段,训练上也还存在非常多坑。
- 以下是Andrej Karpthy给出的应用开发流程具体建议

总结与未来发展
- 总体来说GPT系列根据上面的流程已经获得跨时代的成果,其中关键除了模型本身,还涉及非常多细节:包含:数据采集,训练参数...等。在这次演讲并未有进一步披露。
- 对于未来的发展,目前GPT4展现出来了思维链(Chain of Thought)的能力,也已经广泛应用到AutoGPT, LangChain中。以下是个CoT的示例
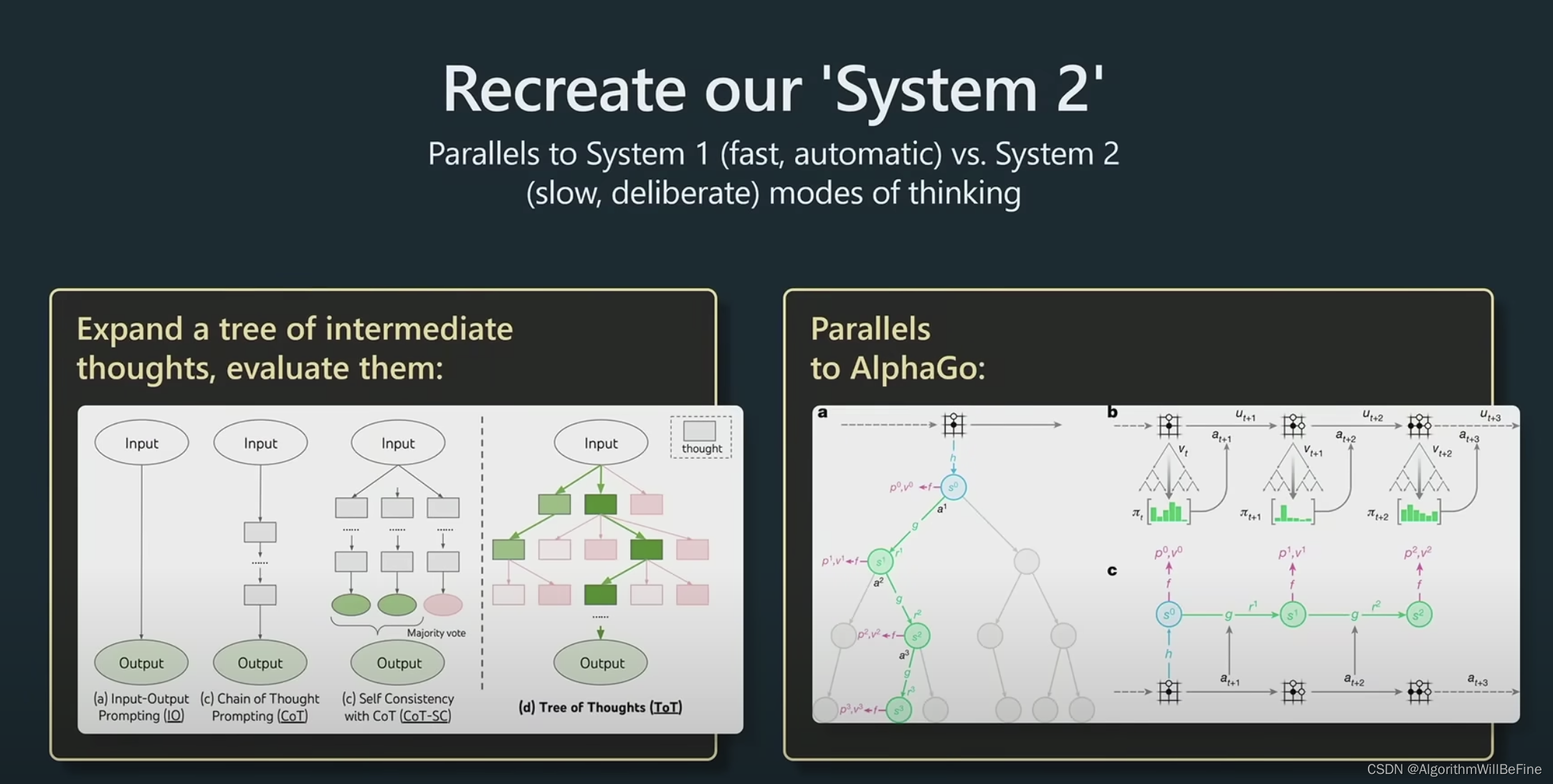
 基于GPT4 CoT的能力, Andrej Karpthy认为认知模型的未来会开始往System2发展,System 1类似人类的反射系统,快速,自动化反馈,而System2则速度更慢,结果更可靠。这也是目前新兴的研究领域:Tree of Thought,演講中举了一个简单的例子就是AlpahaGo下棋的时候是从千万种可能结果中,挑选最合适的行动。所以未来的智能系统可能就不只是输出概率最高的结果,而是会在内部根据不同的情况和策略综合判断。
基于GPT4 CoT的能力, Andrej Karpthy认为认知模型的未来会开始往System2发展,System 1类似人类的反射系统,快速,自动化反馈,而System2则速度更慢,结果更可靠。这也是目前新兴的研究领域:Tree of Thought,演講中举了一个简单的例子就是AlpahaGo下棋的时候是从千万种可能结果中,挑选最合适的行动。所以未来的智能系统可能就不只是输出概率最高的结果,而是会在内部根据不同的情况和策略综合判断。