作者 | MECH
整理 | NewBeeNLP
https://zhuanlan.zhihu.com/p/642351312

Andrej Karpathy(安德烈·卡帕西)是OpenAI的创始人之一,也是OpenAI最早的研究员之一,在斯坦福博士期间完成了大名鼎鼎的CV课程:CS231n(Convolutional Neural Networks for Visual Recognition)。曾任被马斯克亲自下场挖到特斯拉人工智能和自动驾驶部门(Autopilot)做负责人,2023年2月再次加入OpenAI。
Andrej可以说是GPT大模型训练这个领域最有话语权的人之一,在2023年5月23日的微软Build开发者大会上,他做了非常精彩的专题演讲:State of GPT(GPT现状)。
在这里Andrej详细介绍了GPT如何从“初始模型”一直训练成ChatGPT这样的“助手模型”(assistant model,文中简称为“助手”)的方法。要知道OpenAI一直对大模型的训练守口如瓶,还被大家戏称为CloseAI,如果笔者没记错这应该是 OpenAI官方第一次详细阐述其大模型内部原理和RLHF训练细节。
本文是笔者反复观看Andrej演讲后撰写的学习笔记,大佬讲东西一般都比较高屋建瓴,而且语速非常的快,如果没有一些LLM基础或者注解很难跟上。因此本文致力于记录下大佬演讲的精髓,并将大佬一笔带过的点进行注释,方便大家看完这篇文章后就可以对ChatGPT的训练、现状、应用、prompt等有一个比较全面的了解。
读完本文你可以学习到:
ChatGPT类模型的训练细节,训练所需的语料和技术细节点的补充和汇总,让你对大模型训练的过程、参数、语料、资源的情况有个大致了解。
GPT类模型当前的发展现状。
GPT类模型如何高效应用,prompt的本质是什么,如何设计prompt可以让LLMs更高效工作。
演讲视频推荐:
翻译精校中英字幕,哔站地址:BiliBili:【精校中英字幕】State of GPT GPT的现状[1]
演讲视频英文原版,油管地址:YouTube:State Of GPT[2]
1. 如何训练一个GPT(Training)
开篇,Andrej就给出了一张训练流程图,可以说这张图囊括了他想讲的第一部分的全部内容,后述每一小节的内容都可以在这张图中找到其对应的位置。

总的来说,GPT类助手模型训练分为四个训练步骤,这四个训练步骤是有先后依赖关系的,他们分别是:
预训练(Pretraining)
监督微调训练(Supervised Finetuning,SFT)
奖励模型训练(Reward Molel,RM)
强化学习训练(Reinforcement Learning,RL)
每一步都是一个完整的训练流程,既然是完整的训练流程就必定包含数据集、训练模型、优化目标(目标函数)、评估指标、训练资源等等部分,其中细节且随笔者一一道来,当然GPT3.5和GPT4由于没有开源,因此Andrej在演讲中多次提到了LLaMA模型,它是由Meta开源的一款GPT类模型,演讲中Andrej大量引用了LLaMA论文中的训练、实验数据。
1.1 预训练(Pretraining)
模型准备: 随机初始化的GPT。
数据集:
这部分将收集大量的互联网数据,一般都要万亿级别token/word,这部分数据的特点是数据量庞大,但是质量低。
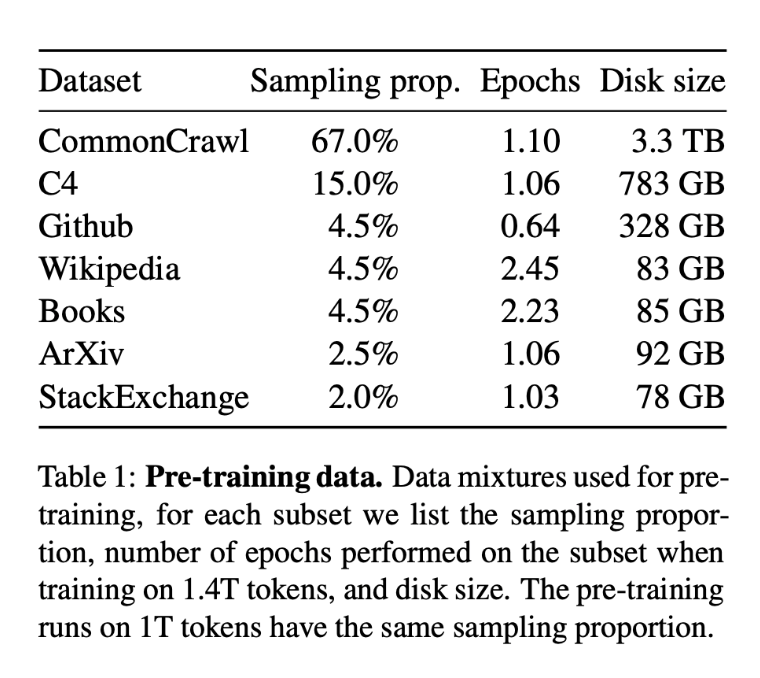
LLM训练的时候有一些公开数据集,比如CommonCrawl[3],C4(Colossal Clean Crawled Corpus)[4]、Github代码数据[5]、维基百科[6]等、书籍[7]、ArXiv论文存档数据[8]、StackExchange网站问答[9]等,中文数据的一些公开数据汇总在这里[10]。
垂直领域的数据需要自己爬取。更多数据集请前往huggingface[11]上搜索,说不定有意外之喜。
以LLaMA的预训练数据集为例, 以上这些数据集按照下图所示的比例采样混合在一起形成最终的预训练数据集。
Tokenization:
利用tokenizor将文本数据转化为整数序列,这些数字每一个都被称为token。GPT类的模型训练一般都是采用sentence piece的tokenizor,据统计平均1个token 0.75个word。
GPT3词表大约是5w个,上下文长度2048(现在可以做到最多长达10w),175B参数。训练数据总token个数为3000亿(300B)。
LLaMA词表大约是3.2w个,上下文长度2048,65B参数。训练数据总token个数为1~1.4万亿(1.4T)。
LLaMA参数两虽然比GPT3小一个数量级,但是其效果却是更好的,这归功于计算的时间更长,见过的数据更多。可见不能直接靠参数量大小来判断两个模型的好坏。
训练数据处理数据组织:
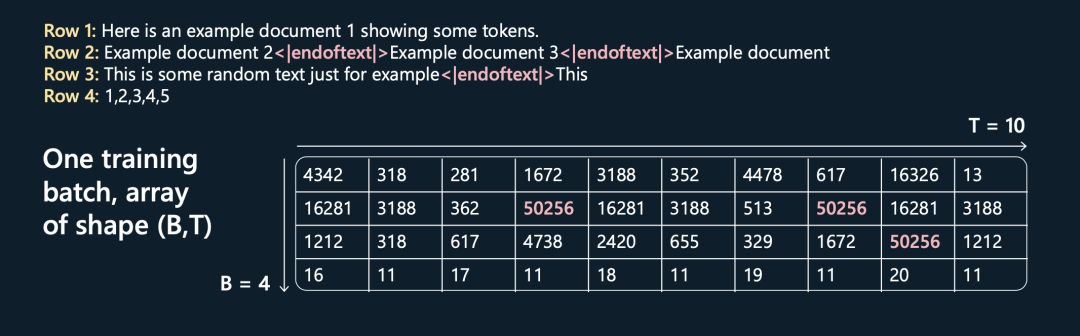
用一个特殊标识<|endoftext|>,将所有文章按行拼接起来,然后将其每隔maxlen长度就切出一条样本,相当于是用多条文本拼接满最大长度组成一条样本,和RoBERTa预训练时的数据组织方式很像。
这样的好处是可以最大化的利用显存,使其尽可能的少出现padding sequence的操作,提升训练效率。
特殊标识<|endoftext|>可以告诉Transformer新文档从哪里开始。
具体流程如下所示,假设B=4,T=10,这4句话和它们最终tokenizor后的结果如下图所示:
训练任务:
经典的预训练任务Next-Token-Prediction。
模型采用单向语言模型架构,即Causal-LM架构,每个token只能看到该token前面的上文信息,利用该token的隐状态向量来预测下一个token是什么。
资源耗费情况:
一般预训练一个大模型:几千张GPU,训练几个月。
GPT3:几千张V100 GPU训练了个位数月份,花费几百万美元。
LLaMA:2048个A100 GPU训练了21天,花费500万美元。
该阶段训练出来的模型有以下特点:
预训练完的模型我们称之为Base Model。但是,Base Model并不是一个可以直接回答你问题的“助手”,如果你向它问问题,它大概率会拒绝回答,或者不理解你的问题,再或者用更多的问题来回答你的问题。具体现象可以看笔者之前的文章中“FastChat加载效果一览”部分[12]。
预训练部分时间比重占了总训练过程的99%以上。
你可以用一些比较trick的prompt来让Base Model输出你想要的回答。
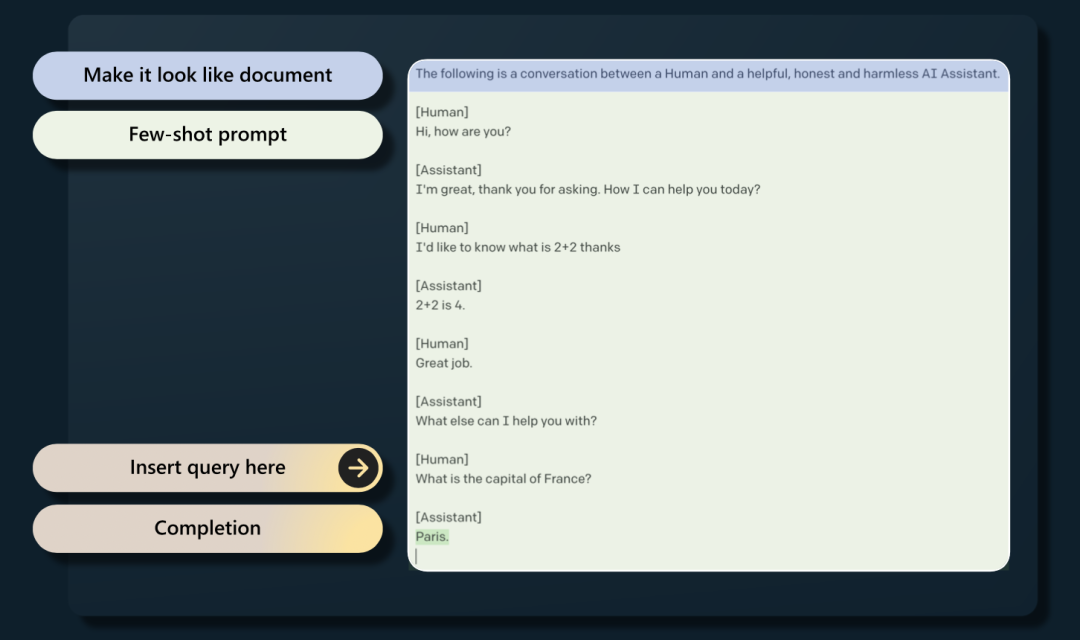
你也可以通过欺骗Base Model让其成为“助手”,你需要实现准备好一个特定的prompt,让Base Model看起来像是人和“助手”之间正在交谈,在最后插入自己的Query,来让Base Model回答,具体流程如下图所示。当然,这样其实一般不可靠,并且实践中也不是很友好, 但仍然可以用这种方法来验证预训练模型train的效果。
1.2 监督微调训练(Supervised Finetuning,SFT)
模型准备 :第一阶段Pretrain好的GPT模型。
数据集:该部分数据集为少量但是高质量的prompt、response数据,数量大约1w~10w条。比如下面这条数据,承包商需要严格按照右边的标注说明书来写这个prompt的response:

资源耗费情况:大约100张GPU训练几天即可完成,比如基于LLaMA训练的Vicuna-13B效果就很不错,感兴趣可以移步笔者的文章:【LLMs学习笔记一】Vicuna部署初体验[13]
SFT其它所有部分都和预训练相同,因为SFT相比于预训练只是换了数据集而已。
不过这里有一些我个人的一些疑问和猜测:
SFT部分的学习率和Pretrain部分一样?个人猜测应该会小一些,否则容易产生灾难性遗忘,目前笔者自己SFT的时候也会设置的比基座模型小一些。
SFT的语料都是对话的形式吗?或者prompt + response的形式?
极有可能大部分是对话形式,chat可以看成是一种下游任务,实际上相当于下游任务数据微调。
不过也可以不使用对话形式,采用高质量的陈述性知识语料,可以用来增加模型的垂域知识。
Vicuna-13B就是在LLaMA的基础上用多轮对话的形式SFT出来的。
多轮对话怎么做?在训练后面几轮对话时,是将模型前几轮模型的response输出当成输入吗,还是将前几轮人工撰写的response当成输入呢?这部分待讨论,等待笔者研究Vicuna-13B的训练细节。
1.3 奖励模型训练(Reward Molel,RM)
这里就开始正式进入传说中的RLHF了(Reinforcement Learning from Human Feedback,基于人类反馈优化的强化学习语言模型)。RLHF分为两部分,一部分是奖励模型RM,一部分是强化学习RL。
模型准备:采用SFT训练好的模型,训练RM模型的时候,SFT模型参数冻结。
数据集:这里数据集开始转变为比较模式,数据还是prompt(问题模板)+response(响应回答)的形式,但是这里的response是由SFT模型生成的,并且会生成多个,人工需要标注的是这些response之间的顺序排名,这个排名的标注有可能会很难且漫长,有的甚至会耗费几个小时来完成一个prompt的responses的排序。
待训练模型:RM模型,即一个打分模型,用来给GPT输出的responses打分排序。
资源消耗情况:大约不到100张GPU训练几天。
训练任务
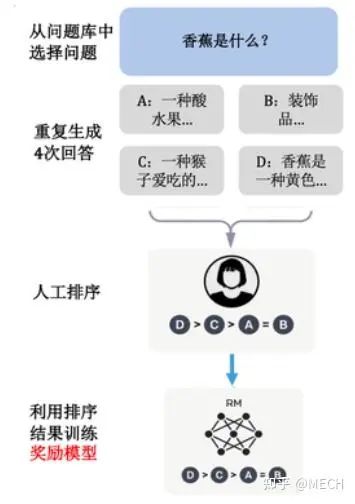
RM的训练过程如下图所示:用同样的prompt和SFT model输出的N个responses分别拼接(图中是3个),然后末尾都拼接一个特殊的奖励标识符<|reward|>,并且将该<|reward|>符的隐状态输出接上一个RM模型,来预测打分,预测打分的顺序和标注的顺序之间会产生一个loss,其实就是LTR排序学习。
为什么采用排序而不是明确打分的标注方式?其实就是将任务难度降低(不论是对标注人员还是对RM模型而言),使RM模型可以更好的被训练,因为计算“比较值”比计算“准确值”容易,减轻模型的打分压力,其实也就是LTR的优点。
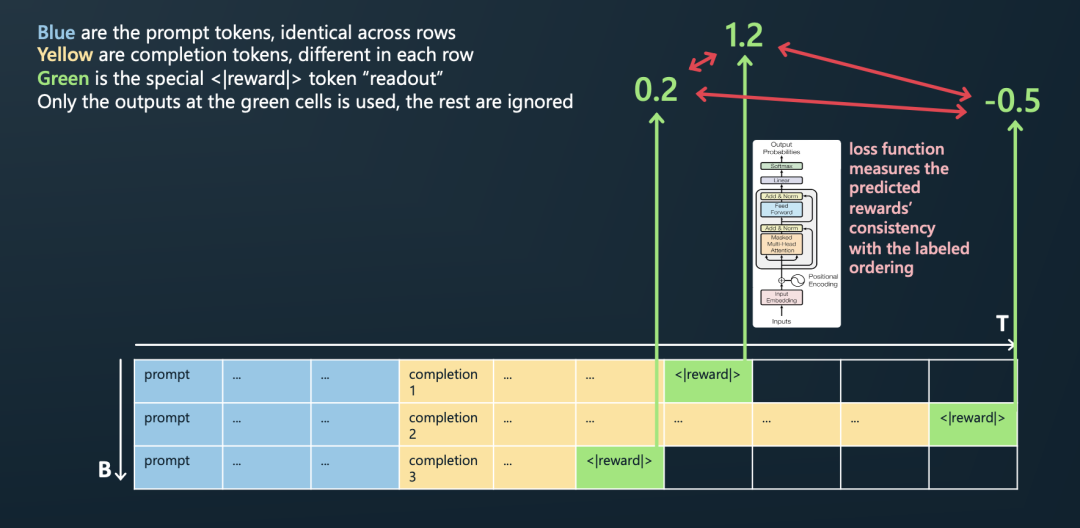
RM模型训练流程图解
1.4 强化学习训练(Reinforcement Learning,RL)
模型准备:采用1.2中SFT训练好的模型+1.3中训练好的RM模型,用RL的方式对SFT进行继续训练。
数据集:这里数据集也和上述RM模型训练时一样为比较模式,数据仍然是prompt+response的形式,response是由SFT模型生成的,并且会生成多个,由奖励模型对其进行打分指导(强化学习)。
待训练模型:STF训练后的GPT模型。
资源消耗情况:大约不到100张GPU训练几天。
训练任务
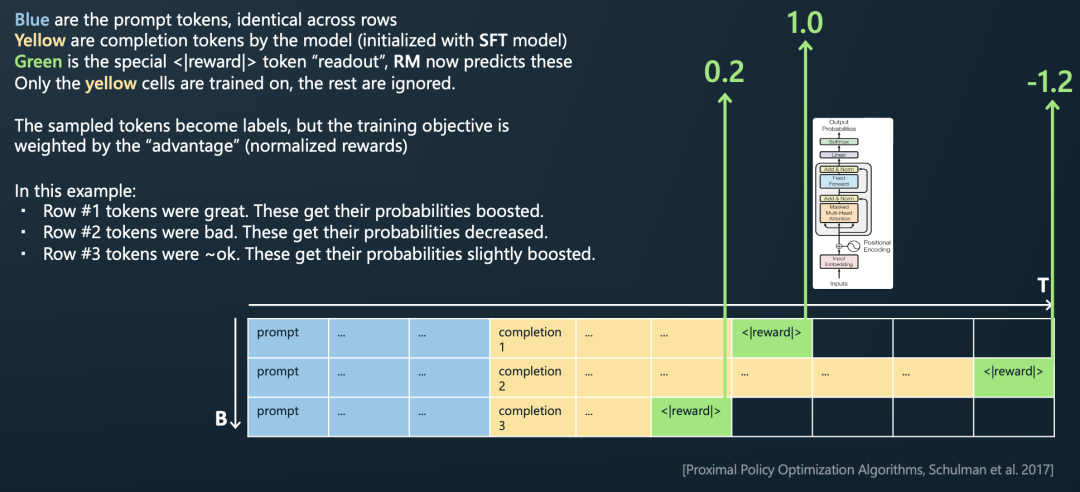
按照上述的方法,用SFT模型对一个prompt生成多个responses。
末尾拼接上奖励标识符<|reward|>。
让训练好的奖励模型RM对<|reward|>的隐状态向量打分。如下图,RM模型对三句话的打分分别是1.0,-1.2,0.2。
例如,对第一行,奖励模型RM打分很高,因此我们将第一行采样的所有token都将得到强化,它们将获得更高的未来被采样的概率。相反,对第二行,奖励模型RM打分-1.2,因此我们对第二行采样的每个token进行惩罚,降低其未来被采样的概率。
仅黄色的response部分tokens才参与到RL模型的训练里面,其余token都将被忽略,即只有黄色部分才参与loss的计算。打分高的语句中的所有token将在之后增加被采样到的概率。
不使用RLHF,仅使用SFT会怎么样?反之呢?RLHF有缺点吗?
实验表明RLHF效果更好。InstructGPT的论文表明PPO(Proximal Policy Optimization,可以理解为一种RL算法)效果最好:
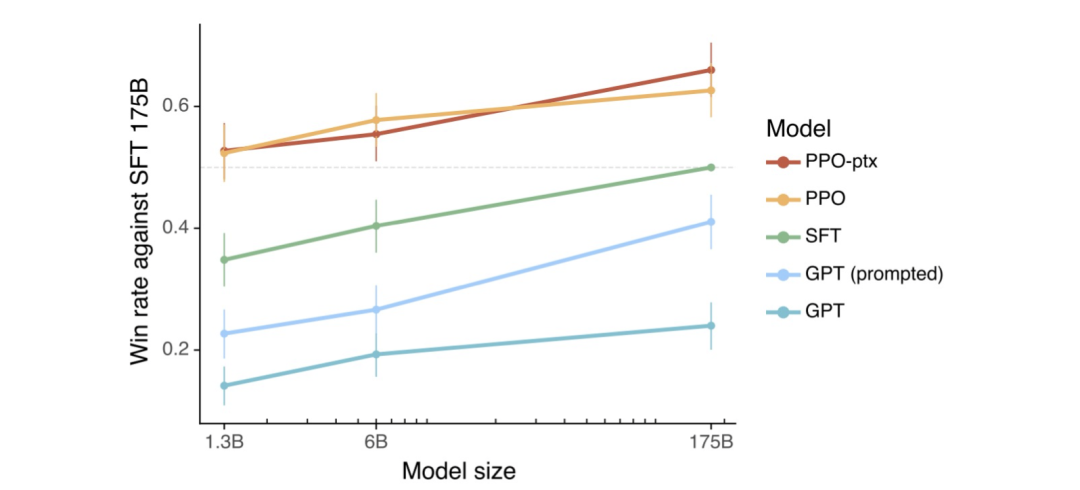
OpenAI做过真实场景下的比较,大部分人更喜欢RLHF的输出结果,而不是SFT的结果。
RLHF也有缺点,RHLF模型相对于SFT Model、Base Model失去了一些熵(即降低了多样性,因为每个位置上都倾向于输出高概率token)。如图可以看到,Base Model会有非常多样化的表达, 因此在一些需要想象力和多样性的任务中,可以尝试下使用Base Model 。

RLHF模型的输出失去了一些熵
2. 大模型排名现状(State)
2.1 大模型排名现状
伯克利有一个团队转门对许多可用的助手模型进行排名,并给出了它们的ELO评级:
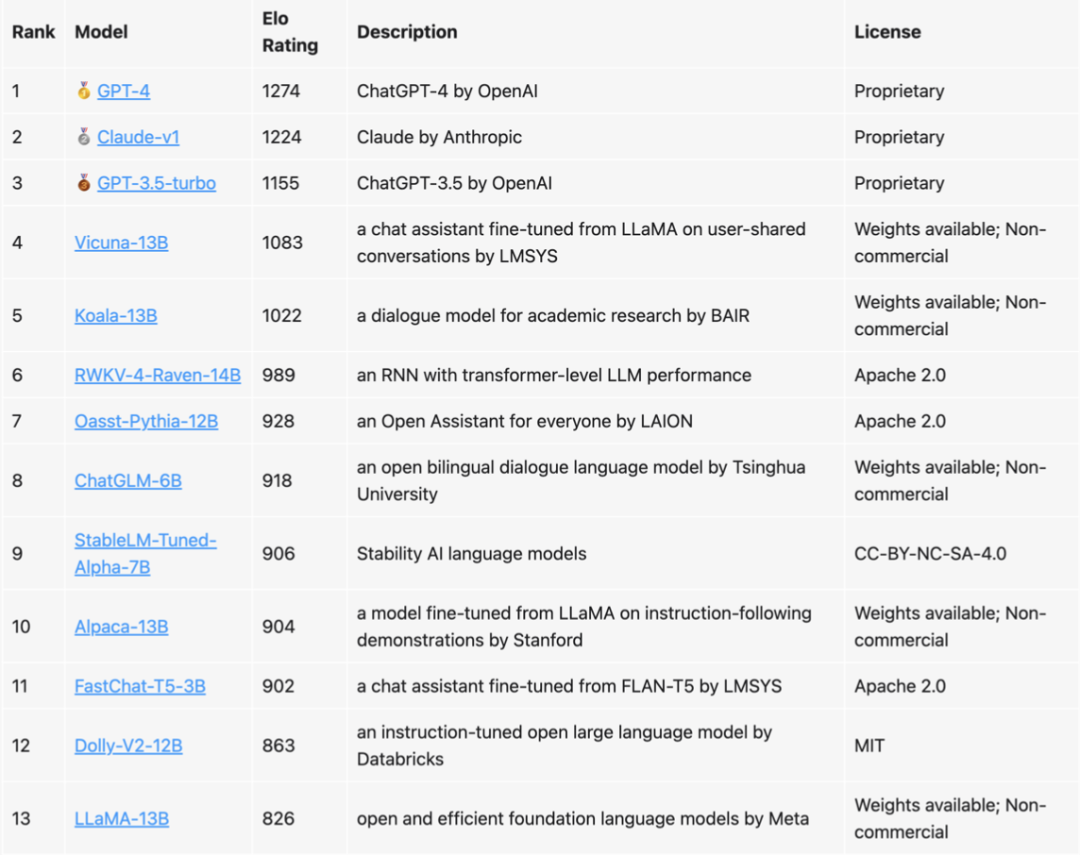
目前排名最高的模型是GPT-4,其次是Claude、GPT-3.5,然后是一些其他开源模型,比如Vicuna-13B。这里排名前三的都是RLHF模型,而其它模型都是SFT模型,也侧面印证了RLHF的效果是优于纯SFT模型的。但是Andrej也提到,RLHF的效果也只是小幅优于纯SFT,SFT的理论性能上线应该还远远没有达到。且RLHF是一个非常棘手的研究,目前应该没有几个团队可以完完全全的玩转这玩意。
2.2 国产占据一席之地
这里让笔者非常惊讶和欣喜的是RWKV模型,排名第六,这个是国产自研自己预训练的模型,作者是 \@PENG Bo[14]大佬。RWKV是当前大模型中唯一一个RNN类架构的模型,兼具RNN和Transformer的优点。
ChatGLM也是非常优秀的国产模型,尤其是最近出来的ChatGLM2更是提升巨大,中文能力确实厉害。
最近一次更新的百度文心一言的提升也是非常巨大,百度在大模型领域不论是商业化产品体验还是模型的理解能力,都在稳步提升。
在此向国内的LLMs研究/开发者们致敬,因为你们的努力才让我们没有在LLMs核心技术上被人甩开太多,请继续加油。
3. 如何高效的应用大模型(Applications)
初看这部分,我本来以为是Andrej拿来水时长凑字数的,没想到这里讲述的非常精彩,收获意外的多,非常建议入门大模型的童鞋看完这一部分,而且墙裂建议大家看看演讲原视频!
3.1 Prompt有效,但是它为什么会有效?
注意,这里并不是简单的告诉你哪些prompt好用,而是站在更高的层次解释了prompt和LLMs的关系。
在这一部分的开头,Andrej先讲了一个案例,让大家理解GPT和人的写作模式有何区别与联系。
假设我们在写一篇文章,现在想在文章的最后写下这句话:“加州人口数量是阿拉斯加人口数量的53倍”,那么一般人的写出这句话的完整思考顺序应该是这样的:
你需要对比加州和阿拉斯加的人口比例,可查阅后发现网上没有现成数据。
你需要知道加州和阿拉斯加分别的人口数量。
你肯定没办法把这两个人口数据记下来,因此你需要上网查询。
你通过维基百科查询到加州39.2M人,通过维基百科查询到阿拉斯加0.74M人。
你需要计算出二者的比例,但是人手算肯定是一时半会出不来的,你需要使用计算器算出3.92/0.74=53。
快速在大脑中检查下这个计算结果是否符合事实,你从自己的印象中知道加州是人口最大的城市,并且阿拉斯加人不是很多,53这个数字看起来很合理。
你开始动笔,写下“加州人口数量53倍于阿拉斯加”这句话。
感觉这个写法很别扭,需要重新组织下语言,你删除掉前面写的这句话,然后重新写下“加州人口数量是阿拉斯加人口数量的53倍”这句话。
OK,重新审查了下这句话,你感觉没问题,很满意,愉快的结束了这篇文章。
当你写作的时候,以上这段丰富的思考过程会在你的大脑中顺序执行,而且你的脑海里总是有一个独立的线程在不断地审查着你写的内容,使你对你写的内容不断修改直到满意为止。简而言之,你在写下文字时总会产生大量的思考流程。但是GPT文字的生成过程中有什么特点呢?如下:
GPT的思考和其写作是分离的,思考这部分在训练的时候已经完成了,模型的训练就是思考,而训练好的GPT模型才负责输出(写作)。
对于你的任何输入,GPT都会产生输出,GPT做的只是计算采样出下一个token,它也不知道他擅长什么、不擅长什么、写的东西好不好。
GPT不会边输出边反思,更不会边输出边纠正错误,它没有像人类那样的一个独立的线程来审查它写的内容。
GPT擅长大规模的记忆工作,可以记忆不同领域大量的基于文本事实的知识。
以上这个例子也是非常的简单易懂,但问题是Andrej为什么要举这样一个例子呢?这里Andrej引入了他在对prompt自己的独到理解, 他认为人类是边思考边写作,而GPT是先“思考”(即训练),使用的时候再写作,其写作的时候是不思考的。“ 提示”(prompt)就是弥补这两种体系结构之间认知差异的一种方式,通过prompt让GPT输出的过程带上人类的思考过程 ,因为GPT拥有非常强大记忆能力,这样就能更好的释放GPT记忆的先验知识 。
因此就有了大家所熟悉的思维链(Chain of Thought,CoT)这样的prompt方法,其核心思想就是: GPT需要更多的token去思考,才能得到较好的结果,因此假如你的期望GPT解决一个非常复杂的包含大量推理过程的问题,你需要将问题拆分成多个步骤,通过prompt让GPT具备思考的过程。
举个例子,假设有一个非常复杂的问题,如下:
Q:A juggler can juggle 16 balls. Half of the balls are golf balls and half of the golf balls are blue. How many blue golf balls are there?
A:(Output) If a juggler can juggle 16 balls and half of them are golf balls, then there are 16/2 = 8 blue golf balls. The answer is 8.(回答错误)
很明显上述问题GPT回答错误了,答案应该是16 / 2 / 2 = 4。这个问题需要一步一步地推理,因此以下两种手段都可以让GPT更好的解答这个问题。
第一种比较好理解,就是few-shot的方法,给GPT一个示例,让GPT按照示例的思考方式来解决问题,比如:
Q:Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?
A:Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5+6=11. The answer is 11.
Q:A juggler can juggle 16 balls. Half of the balls are golf balls, and half of the golf balls are blue. How many blue golf balls are there?
A:(Output) The juggler can juggle 16 balls. Half of the balls are golf balls. So there are 16/2= 8 golf balls. Half of the golf balls are blue. So there are 8/2=4 blue golf balls. The answer is 4.(回答正确)
可以看到,给GPT一个简单的例子和具体思考问题、解答问题的思维链后,GPT回答正确了我们之前问的问题。
那第二种方法就很神奇了,是一种zero-shot的方法,你只需要给GPT在回答前prompt一句话:“Let's think step by step”,然后 GPT居然就可以很神奇的回答正确了,如下:
Q:A juggler can juggle 16 balls. Half of the balls are golf balls, and half of the golf balls are blue. How many blue golf balls are there?
A: Let's think step by step. (Output) There are 16 balls in total. Half of the balls are golf balls. That means that there are 8 golf balls. Half of the golf balls are blue. That means that there are 4 blue golf balls.(回答正确)
为什么只需要加一句“Let's think step by step”就可以让GPT回答正确了呢?Andrej指出这句prompt可以将 Transformer调整成一种展示它工作方式的状态 ,每个token需要进行的计算工作会更少,也更可能得到正确的结果。
这里Andrej演讲时使用的配图也很有意思,深谙prompt的精髓:

狗子坐在火车上边跑边铺轨道
一只狗坐在火车上边跑边铺轨道,火车的下一步走向完全由狗铺的轨道来引导,这也恰当的阐述了prompt和LLMs的关系。
3.2 一些高效的prompt技巧
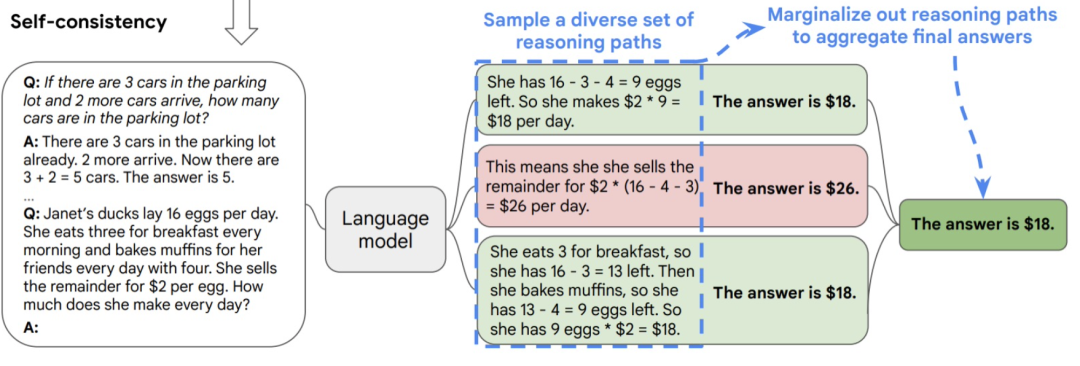
多次输出并且融合结果(Ensemble multi-responses):比如让多次输出然后投票得到的结果,可以更置信。因为GPT不会反思自己的错误,更不会认识到自己正在输出错误的回答。假设非常不幸运,某一个采样到的token恰好发生了事实性错误,GPT也不会暂停输出。因此多次输出然后融合结果可以规避小概率带来的大错误。下图举了个例子:
直接问GPT是否回答正确(Ask for reflection):大量实验证明LLM很清楚的知道自己有没有很好的回答你的问题,因此我们可以通过直接问它是否正确完成了工作,来达到简单check的目的。下图给出了一个例子,让GPT生成一首不押韵的诗,实际上首次给出的这首诗是押韵的,但是如果你问他“你完成这项任务了吗?”,它会告诉你他没有完成任务,因此这种反思重新审视的能力GPT是有的,只是不具备做这个行动的思维,因此你可以通过prompt来帮它完成这种思维。

从更高的层面看prompt技术:prompt实际上是在重构LLM的“第二系统”(Recreate LLM‘s ‘System 2’)。首先什么是“第二系统”?大脑有两套系统,指的是人类思维和决策过程中的两种不同方式。这个观点源自丹尼尔·卡尼曼(Daniel Kahneman)在他的著作《思考,快与慢》中提出的“系统1”和“系统2”理论。系统1是一种快速的、直觉的、自动化反应处理信息的系统,其处理信息和决策时毫不费力。系统2是一种比较慢的、思维谨慎的、规划性的系统,其处理信息需要大量的抽象、思维和推理。Andrej在这里将LLM模型不断采样输出token看成是系统1,而给模型施加辅助思考性质上下文的prompt则更像是系统2,不断修改prompt就像是在不断恢复、重构LLM的系统2。
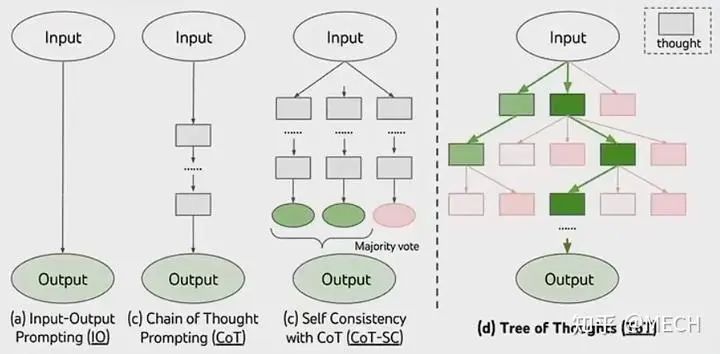
近期发表的一篇论文提出了思维树(Tree of Thought,ToT)的概念,在这篇文章中,作者让LLM回答问题时对一个prompt输出多个responses,每当生成下一个token时不止采样一个,而是采样多个最可能的token,在这些token的基础上再继续采样多个token,就像一个多叉树一样逐层分裂,每一叉都是一个response,在生成过程中的每一步都对所有子树进行打分,保留生成合理的子树,将生成不合理的剪枝。其实有点类似于阿法狗下围棋时模拟出的多步最优选择策略。其过程如下图所示,左边三个分别是直接prompt、CoT prompt、ensemble CoT prompt,右侧为论文提出的ToT(你没看错,名字极其像大哭的表情 )。
给LLMs一个高性能的条件(Condition on good performance),什么意思呢?在LLMs被训练的语料中,对于同样的问题,有一些是小白回答的错误答案,有一些是专家回答的正确答案,但是LLMs在训练和推理的时候都不会去识别他们是好是坏,只会模仿输出。因此你需要给他一个专家的身份,或者给出一个具体的环境条件,来让LLMs尽可能去模仿专家的输出而不是小白的输出,比如说你可以告诉LLMs,“假设你是一个在这个领域的专家”、“假设你是一个智商140的人”等等。这里Andrej特意说了别把智商说的太高否则,GPT会跟你写起科幻小说。有个很有趣的实验如下图所示,在以下多种CoT prompt中,增加了一句“be sure we have the right answer”就可以让任务效果直接飙升!准确率从78.7直接到了82。

LLMs可能不知道自己擅长什么不擅长什么,因此你需要显式地告诉它,让它允许使用插件或者工具,现在有很多的GPT插件或者工具,比如在计算非常复杂的计算时,你可以告诉LLMs:“你不太擅长计算,现在有一台计算器可以辅助你计算”,并且给它使用示例,比如“200 x 12 = 2400”之类的计算方法。
检索增强型LLM(Retrieval-Augumented LLMs),在没有LLMs前,我们大部分的工作都被抽象成纯检索类任务(Retrieval Only,其实就是谷歌百度之类的搜索引擎),但LLM将其变成了另一个极端,即低内存类(Low Memory Only,就是直接根据提问条件直接从token空间采样然后递归生成答案的任务)任务,但是其实检索和低内存之间还有很大一部分空间,可以不用那么极端,我们可以用检索的方式在专家库中检索出专业信息,并将其设计拼接成prompt,喂给LLM,从而可以让LLM的输出效果大大提升,这一点会非常有效!比如ChatGPT+Browse,New Bing等。
强制约束LLM的输出模板(Constrained prompting),用比如json的格式来约束住prompt,甚至可以约束这个json中某模块的输出类型、正则表达式,使这部分的token只在满足条件的部分token中采样等等。
3.3 Andrej对finetuning和RLHF还有话要说
Finetuning相关,资源少可以用用LoRA等技术。
SFT相对成熟,但RLHF仍然属于研究领域,有可能使模型更难工作,不建议自己手写RLHF,相当不稳定,并且很难训练,不适合初学者,变化也会很快。
Andrej给出了自己的推荐的LLMs最佳使用姿势,首先建议你使用GPT4,其次尽可能对你任务的细节作出prompt,可以使用检索的专业知识或者相关上下文来辅助prompt,接着最好给出问题解答的示例,尝试让GPT使用插件或者工具,比如计算器等等,详细可以根据下图了解:

以上就是本次演讲的全部内容了,融汇了笔者对大佬演讲的笔记和自己的相关思考。
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书