本文转自:http://blog.csdn.net/Together_CZ/article/details/65945838?locationNum=15&fps=1
1、查找最大的k个元素
1、排序,快速排序。我们知道,快速排序平均所费时间为n*logn,从小到大排序这n个数,然后再遍历序列中后k个元素输出,即可,总的时间复杂度为O(n*logn+k)=O(n*logn)。
2、排序,选择排序。用选择或交换排序,即遍历n个数,先把最先遍历到得k个数存入大小为k的数组之中,对这k个数,利用选择或交换排序,找到k个数中的最小数kmin(kmin设为k个元素的数组中最小元素),用时O(k)(你应该知道,插入或选择排序查找操作需要O(k)的时间),后再继续遍历后n-k个数,x与kmin比较:如果x > kmin,则x代替kmin,并再次重新找出k个元素的数组中最小元素kmin‘(多谢jiyeyuran 提醒修正);如果x < kmin,则不更新数组。也就是,每次把k个元素的数组中最小的元素替换掉。这样,每次更新或不更新数组的所用的时间为O(k)或O(0),整趟下来,总的时间复杂度平均下来为:n*O(k)=O(n*k)。
3、维护k个元素的最小堆,原理与上述第2个方案一致,即用容量为k的最小堆存储最先遍历到的k个数,并假设它们即是最大的k个数,建堆费时O(k),并调整堆(费时O(logk))后,有k1>k2>…kmin(kmin设为小顶堆中最小元素)。继续遍历数列,每次遍历一个元素x,与堆顶元素比较,若x>kmin,则更新堆(用时logk),否则不更新堆。这样下来,总费时O(k*logk+(n-k)*logk)=O(n*logk)。此方法得益于在堆中,查找等各项操作时间复杂度均为logk(不然,就如上述思路2所述:直接用数组也可以找出最大的k个元素,用时O(n*k))。
4、按编程之美第141页上解法二的所述,类似快速排序的划分方法,N个数存储在数组S中,再从数组中随机选取一个数X,把数组划分为Sa和Sb俩部分,Sa>=X>=Sb,如果要查找的k个元素小于Sa的元素个数,则返回Sa中较大的k个元素,否则返回Sa中所有的元素+Sb中最大的k-|Sa|个元素。不断递归下去,把问题分解成更小的问题,平均时间复杂度为O(N)。
2、什么是哈希表?
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表hashtable(key,value) 的做法其实很简单,就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
3、应用实例
1、搜索引擎热门查询统计:Hash表+堆!!!
搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。
假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
问题解析:
要统计最热门查询,首先就是要统计每个Query出现的次数,然后根据统计结果,找出Top 10。所以我们可以基于这个思路分两步来设计该算法。
第一步:Query统计
Query统计有以下俩个方法,可供选择:
1、排序法
题目中有明确要求,那就是内存不能超过1G。一千万条记录,每条记录是255Byte,很显然要占据2.375G内存,这个条件就不满足要求了。
让我们回忆一下数据结构课程上的内容,当数据量比较大而且内存无法装下的时候,我们可以采用外排序的方法来进行排序,这里我们可以采用归并排序,因为归并排序有一个比较好的时间复杂度O(NlgN)。
排完序之后我们再对已经有序的Query文件进行遍历,统计每个Query出现的次数,再次写入文件中。
综合分析一下,排序的时间复杂度是O(NlgN),而遍历的时间复杂度是O(N),因此该算法的总体时间复杂度就是O(N+NlgN)=O(NlgN)。
2、Hash Table法
能不能有更好的方法时间复杂度更低呢?
题目中说明了,虽然有一千万个Query,但是由于重复度比较高,因此事实上只有300万的Query,每个Query255Byte,因此我们可以考虑把他们都放进内存中去,Hash Table绝对是我们优先的选择,因为Hash Table的查询速度非常的快,几乎是O(1)的时间复杂度。
那么,我们的算法就有了:维护一个Key为Query字串,Value为该Query出现次数的HashTable,每次读取一个Query,如果该字串不在Table中,那么加入该字串,并且将Value值设为1;如果该字串在Table中,那么将该字串的计数加一即可。最终我们在O(N)的时间复杂度内完成了对该海量数据的处理。
相比算法1:在时间复杂度上提高了一个数量级,为O(N),但不仅仅是时间复杂度上的优化,该方法只需要IO数据文件一次,而算法1的IO次数较多的。
第二步:找出Top 10
算法一:普通排序
排序算法的时间复杂度是NlgN,在本题目中,三百万条记录,用1G内存是可以存下的。
算法二:部分排序
题目要求是求出Top 10,因此我们没有必要对所有的Query都进行排序,我们只需要维护一个10个大小的数组,初始化放入10个Query,按照每个Query的统计次数由大到小排序,然后遍历这300万条记录,每读一条记录就和数组最后一个Query对比,如果小于这个Query,那么继续遍历,否则,将数组中最后一条数据淘汰,加入当前的Query。最后当所有的数据都遍历完毕之后,那么这个数组中的10个Query便是我们要找的Top10了。
不难分析出,这样,算法的最坏时间复杂度是N*K, 其中K是指top多少。
算法三:堆
在算法二中,我们已经将时间复杂度由NlogN优化到NK,不得不说这是一个比较大的改进了,可是有没有更好的办法呢?
每次查找的时候可以采用二分的方法查找,这样操作的复杂度就降到了logK。能快速查找,又能快速移动元素的数据结构:那就是堆。
借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此到这里,我们的算法可以改进为这样,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比。!!!
具体过程是,堆顶存放的是整个堆中最小的数,现在遍历N个数,把最先遍历到的k个数存放到最小堆中,并假设它们就是我们要找的最大的k个数,X1>X2…Xmin(堆顶),而后遍历后续的N-K个数,一一与堆顶元素进行比较,如果遍历到的Xi大于堆顶元素Xmin,则把Xi放入堆中,而后更新整个堆,更新的时间复杂度为logK,如果Xi < Xmin,则不更新堆,整个过程的复杂度为O(K)+O((N-K)*logK)=O(N*logK)。
总结:
至此,算法就完全结束了,经过上述第一步、先用Hash表统计每个Query出现的次数,O(N);然后第二步、采用堆数据结构找出Top 10,N*O(logK)。所以,我们最终的时间复杂度是:O(N) + N’*O(logK)。!!!!!!!!(N为1000万,N’为300万)。
http://blog.csdn.net/v_JULY_v/article/details/6256463#comments
摊还分析—算法导论第十七章
摊还分析是用来评价程序中的一个操作序列的平均代价,有时可能某个操作的代价特别高,但总体上来看也并非那么糟糕,可以形象的理解为把高代价的操作“分摊”到其他操作上去了,要求的就是均匀分摊后的平均代价。
摊还分析有三种常用的技术:聚合分析,核算法,势能法。
首先看个例子,现在有三种操作,push(s),pop(s),mutlipop(s,k),push(s),统称为栈操作。 push(s)每次只能压一个数据,所以规定操作的代价为1,pop(s)每次只能弹一个数据,所以也规定操作的代价为1,而mutlipop(s,k),内部实现的是一个循环弹出,每执行一次的代价为k(k < n,n为栈的最大容量)。那么现在问题来了,我想分析下执行n次栈操作最坏情况下的时间复杂度是多少?第一反应应该就是这样想的,mutlipop(s,k)的代价最高,最高位k=n;
执行n次的最坏情况当然就是o(n2)啦,但实际上并非如此。
聚合分析要求我们要总体看问题,首先mutlipop(s,k)也是个弹栈的操作,当栈里有数据的时候才执行有效,所以上述提到的o(n2)是不科学的,而push(s),pop(s)的代价是1,可想而知最坏的情况当然是前n-1次操作都是压栈,而最后一次才执行mutlipop(s,n-1),这样的代价也只有2n-2,时间复杂度为o(n),平均下来每个操作的摊还代价就为o(1)了。
核算法比较好理解,进行摊还分析时,摊还的代价有可能多于实际的代价,也有可能少于实际的代价,多于实际代价的差额会存进一个数据结构中,称为信用,而当遇到少于实际代价的时候就可以用这些信用来填充了。注意这些什么算法提供的只是思路,求出一系列操作代价的上界的思路,具体的做法还是要自己思考的。
同样是压栈的例子,我们可以赋给Push(s)操作的摊还代价是2,相当于自己使用了1,而压进去的必定会弹出,剩下的1就作为弹出时的费用,这样pop(s)和mutlipop(s,k)的摊还代价就为0,这样做有什么意义?试着现在思考下题目中的问题(斜体部分),那么可想最糟糕的情况无非就是所有操作都是Push(s),代价为2n,并不像聚合代价那样需要考虑其他两个操作(摊还代价为0),时间复杂度为O(n)。
势能法
势能法其实核算法有点相似,也有预付差额的,但不叫信用,而叫势能,势能法是从整体上看的,不像核算法那样具体到某个操作,而是整体的势能。
势能法定义了一条公式;
Ci(摊还)=Ci(实际)+f(Di)-f(Di-1) (1)
累加可得总摊还代价的公式为;
Ci(总摊还)= Ci(总实际)+ f(Di)-f(D0) (2)
其中Ci 为每步操作的代价,f(Di)表示执行了第i个操作后的势能,那个这个公式就可以理解为 第i步操作的摊还代价等于第i步操作的实际代价加上从第i-1步操作到第i步操作的势能变化,理解这个后,再来看栈操作的例子。
同样Push(s)、pop(s)的代价为1, mutlipop(s,k)的代价为k,我们规定入栈一个元素势能加1,弹出一个元素势能减1,那么f(Di)永远为非负,而f(D0)等于0,再根据上面的公式(2)即可知道这个又这里就可以确定总摊还代价是总实际代价的上界,所以现在要求的就是总摊还代价。
根据公式(1)可以得到Push(s)的摊还代价为2,pop(s)的摊还代价为0,mutlipop(s,k)的摊还代价也为0 (因为弹栈势能要减,刚好和代价抵消,也可以看做势能都用来支付代价了,所以下降了),那么又回到了核算法了,可得时间复杂度为O(n)。
以上转自http://blog.csdn.net/mypongo/article/details/42189001
练习17.1-3
假定我们对一个数据结构执行一个由n个操作组成的操作序列,当i严格为2的幂时,第i个操作的代价为i,否则代价为1。使用聚合分析确定每个操作的摊还代价。

练习17.2-2
用核算法重做练习17.1-3


转自http://blog.csdn.net/xiazdong/article/details/8462393
stable sort:插入排序、冒泡排序、归并排序、计数排序、基数排序、桶排序。
unstable sort:选择排序、快速排序、堆排序。
插入排序,冒泡排序和快速排序的排序趟数与序列的初始状态有关!!!
堆排序和选择排序的排序次数与初始状态无关,即最好情况和最坏情况都一样!!!
一、插入排序
特点:stable sort、In-place sort
最优复杂度:当输入数组就是排好序的时候,复杂度为O(n),而快速排序在这种情况下会产生O(n^2)的复杂度。
最差复杂度:当输入数组为倒序时,复杂度为O(n^2)
插入排序比较适合用于“少量元素的数组”。
其实插入排序的复杂度和逆序对的个数一样,当数组倒序时,逆序对的个数为n(n-1)/2,因此插入排序复杂度为O(n^2)。
在算法导论2-4中有关于逆序对的介绍。
伪代码:

证明算法正确性:
循环不变式:在每次循环开始前,A[1…i-1]包含了原来的A[1…i-1]的元素,并且已排序。
初始:i=2,A[1…1]已排序,成立。
保持:在迭代开始前,A[1…i-1]已排序,而循环体的目的是将A[i]插入A[1…i-1]中,使得A[1…i]排序,因此在下一轮迭代开 始前,i++,因此现在A[1…i-1]排好序了,因此保持循环不变式。
终止:最后i=n+1,并且A[1…n]已排序,而A[1…n]就是整个数组,因此证毕。
而在算法导论2.3-6中还问是否能将伪代码第6-8行用二分法实现?
实际上是不能的。因为第6-8行并不是单纯的线性查找,而是还要移出一个空位让A[i]插入,因此就算二分查找用O(lgn)查到了插入的位置,但是还是要用O(n)的时间移出一个空位。
问:快速排序(不使用随机化)是否一定比插入排序快?
答:不一定,当输入数组已经排好序时,插入排序需要O(n)时间,而快速排序需要O(n^2)时间。
递归版插入排序

二、冒泡排序
特点:stable sort、In-place sort
思想:通过两两交换,像水中的泡泡一样,小的先冒出来,大的后冒出来。
最坏运行时间:O(n^2)
最佳运行时间:O(n^2)(当然,也可以进行改进使得最佳运行时间为O(n))
算法导论思考题2-2中介绍了冒泡排序。
伪代码:
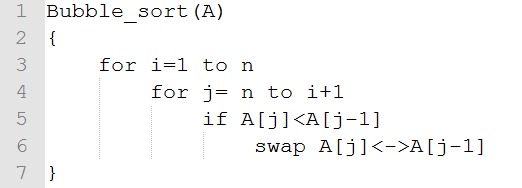
证明算法正确性:
运用两次循环不变式,先证明第4-6行的内循环,再证明外循环。
内循环不变式:在每次循环开始前,A[j]是A[j…n]中最小的元素。
初始:j=n,因此A[n]是A[n…n]的最小元素。
保持:当循环开始时,已知A[j]是A[j…n]的最小元素,将A[j]与A[j-1]比较,并将较小者放在j-1位置,因此能够说明A[j-1]是A[j-1…n]的最小元素,因此循环不变式保持。
终止:j=i,已知A[i]是A[i…n]中最小的元素,证毕。
接下来证明外循环不变式:在每次循环之前,A[1…i-1]包含了A中最小的i-1个元素,且已排序:A[1]<=A[2]<=…<=A[i-1]。
初始:i=1,因此A[1..0]=空,因此成立。
保持:当循环开始时,已知A[1…i-1]是A中最小的i-1个元素,且A[1]<=A[2]<=…<=A[i-1],根据内循环不变式,终止时A[i]是A[i…n]中最小的元素,因此A[1…i]包含了A中最小的i个元素,且A[1]<=A[2]<=…<=A[i-1]<=A[i]
终止:i=n+1,已知A[1…n]是A中最小的n个元素,且A[1]<=A[2]<=…<=A[n],得证。
在算法导论思考题2-2中又问了”冒泡排序和插入排序哪个更快“呢?
一般的人回答:“差不多吧,因为渐近时间都是O(n^2)”。
但是事实上不是这样的,插入排序的速度直接是逆序对的个数,而冒泡排序中执行“交换“的次数是逆序对的个数,因此冒泡排序执行的时间至少是逆序对的个数,因此插入排序的执行时间至少比冒泡排序快。
递归版冒泡排序

改进版冒泡排序
最佳运行时间:O(n)
最坏运行时间:O(n^2)

三、选择排序
特性:In-place sort,unstable sort。
思想:每次找一个最小值。
最好情况时间:O(n^2)。
最坏情况时间:O(n^2)。
定义:首先,选出数组中最小的元素,将它与数组中第一个元素交换。然后找出次小的元素,并将它与数组中第二个元素交换。按照这种方法一直进行下去,直到整个数组排完序。
交换次数:N-1
伪代码:

证明算法正确性:
循环不变式: A[1…i-1]包含了A中最小的i-1个元素,且已排序。
初始: i=1,A[1…0]=空,因此成立。
保持:在某次迭代开始之前,保持循环不变式,即A[1…i-1]包含了A中最小的i-1个元素,且已排序,则进入循环体后,程序从A[i…n]中找出最小值放在A[i]处,因此A[1…i]包含了A中最小的i个元素,且已排序,而i++,因此下一次循环之前,保持循环不变式:A[1..i-1]包含了A中最小的i-1个元素,且已排序。
终止: i=n,已知A[1…n-1]包含了A中最小的i-1个元素,且已排序,因此A[n]中的元素是最大的,因此A[1…n]已排序,证毕。
算法导论2.2-2中问了”为什么伪代码中第3行只有循环n-1次而不是n次”?
在循环不变式证明中也提到了,如果A[1…n-1]已排序,且包含了A中最小的n-1个元素,则A[n]肯定是最大的,因此肯定是已排序的。
递归版选择排序

四、归并排序
特点:stable sort、Out-place sort
思想:运用分治法思想解决排序问题。
最坏情况运行时间:O(nlgn)
最佳运行时间:O(nlgn)
分治法介绍:分治法就是将原问题分解为多个独立的子问题,且这些子问题的形式和原问题相似,只是规模上减少了,求解完子问题后合并结果构成原问题的解。
分治法通常有3步:Divide(分解子问题的步骤) 、 Conquer(递归解决子问题的步骤)、 Combine(子问题解求出来后合并成原问题解的步骤)。
假设Divide需要f(n)时间,Conquer分解为b个子问题,且子问题大小为a,Combine需要g(n)时间,则递归式为:
T(n)=bT(n/a)+f(n)+g(n)
算法导论思考题4-3(参数传递)能够很好的考察对于分治法的理解。
就如归并排序,Divide的步骤为m=(p+q)/2,因此为O(1),Combine步骤为merge()函数,Conquer步骤为分解为2个子问题,子问题大小为n/2,因此:
归并排序的递归式:T(n)=2T(n/2)+O(n)
而求解递归式的三种方法有:
(1)替换法:主要用于验证递归式的复杂度。
(2)递归树:能够大致估算递归式的复杂度,估算完后可以用替换法验证。
(3)主定理:用于解一些常见的递归式。
伪代码:
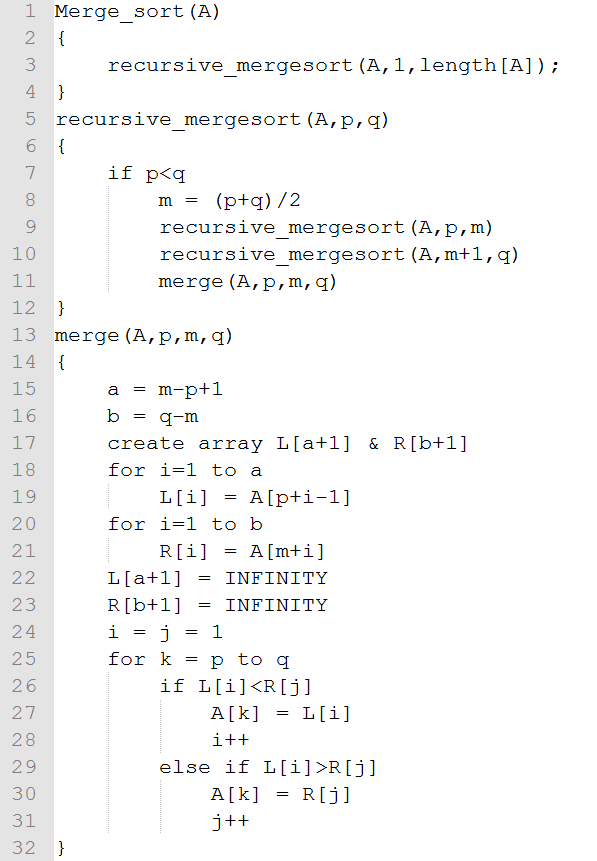
证明算法正确性:
其实我们只要证明merge()函数的正确性即可。
merge函数的主要步骤在第25~31行,可以看出是由一个循环构成。
循环不变式:每次循环之前,A[p…k-1]已排序,且L[i]和R[j]是L和R中剩下的元素中最小的两个元素。
初始:k=p,A[p…p-1]为空,因此已排序,成立。
保持:在第k次迭代之前,A[p…k-1]已经排序,而因为L[i]和R[j]是L和R中剩下的元素中最小的两个元素,因此只需要将L[i]和R[j]中最小的元素放到A[k]即可,在第k+1次迭代之前A[p…k]已排序,且L[i]和R[j]为剩下的最小的两个元素。
终止:k=q+1,且A[p…q]已排序,这就是我们想要的,因此证毕。
归并排序的例子:
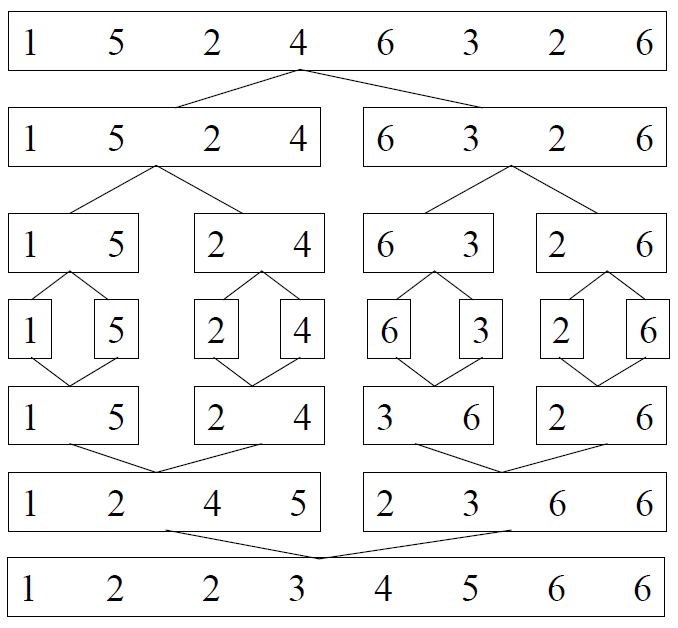
问:归并排序的缺点是什么?
答:他是Out-place sort,因此相比快排,需要很多额外的空间。
问:为什么归并排序比快速排序慢?
答:虽然渐近复杂度一样,但是归并排序的系数比快排大。
问:对于归并排序有什么改进?
答:就是在数组长度为k时,用插入排序,因为插入排序适合对小数组排序。在算法导论思考题2-1中介绍了。复杂度为O(nk+nlg(n/k)) ,当k=O(lgn)时,复杂度为O(nlgn)
五、快速排序
基本思想:在待排序的N个记录中任意取一个记录,把该记录放在最终位置后,数据序列被此记录分成两部分。所有关键字比该记录关键字小的放在前一部分,所有比它大的放置在后一部分,并把该记录排在这两部分的中间,这个过程称作一次快速排序。重复上述过程,直到每一部分内只有一个记录为止。
特性:unstable sort、In-place sort。
最坏运行时间:当输入数组已排序时,时间为O(n^2),当然可以通过随机化来改进(shuffle array 或者 randomized select pivot),使得期望运行时间为O(nlgn)。
最佳运行时间:O(nlgn)
快速排序的思想也是分治法。
当输入数组的所有元素都一样时,不管是快速排序还是随机化快速排序的复杂度都为O(n^2),而在算法导论第三版的思考题7-2中通过改变Partition函数,从而改进复杂度为O(n)。
注意:只要partition的划分比例是常数的,则快排的效率就是O(nlgn),比如当partition的划分比例为10000:1时(足够不平衡了),快排的效率还是O(nlgn)
“A killer adversary for quicksort”这篇文章很有趣的介绍了怎么样设计一个输入数组,使得quicksort运行时间为O(n^2)。
伪代码:

随机化partition的实现:

改进当所有元素相同时的效率的Partition实现:
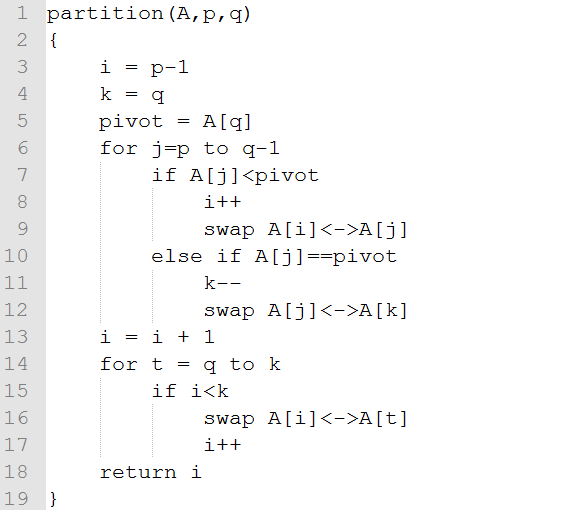
证明算法正确性:
对partition函数证明循环不变式:A[p…i]的所有元素小于等于pivot,A[i+1…j-1]的所有元素大于pivot。
初始:i=p-1,j=p,因此A[p…p-1]=空,A[p…p-1]=空,因此成立。
保持:当循环开始前,已知A[p…i]的所有元素小于等于pivot,A[i+1…j-1]的所有元素大于pivot,在循环体中,
-如果A[j]>pivot,那么不动,j++,此时A[p…i]的所有元素小于等于pivot,A[i+1…j-1]的所有元素大于pivot。
-如果A[j]<=pivot,则i++,A[i+1]>pivot,将A[i+1]和A[j]交换后,A[P…i]保持所有元素小于等于pivot,而A[i+1…j-1]的所有元素大于pivot。
终止:j=r,因此A[p…i]的所有元素小于等于pivot,A[i+1…r-1]的所有元素大于pivot。
六、堆排序
1964年Williams提出。
特性:unstable sort、In-place sort。
最优时间:O(nlgn)
最差时间:O(nlgn)
此篇文章介绍了堆排序的最优时间和最差时间的证明:http://blog.csdn.net/xiazdong/article/details/8193625
思想:运用了最小堆、最大堆这个数据结构,而堆还能用于构建优先队列。
优先队列应用于进程间调度、任务调度等。
堆数据结构应用于Dijkstra、Prim算法。
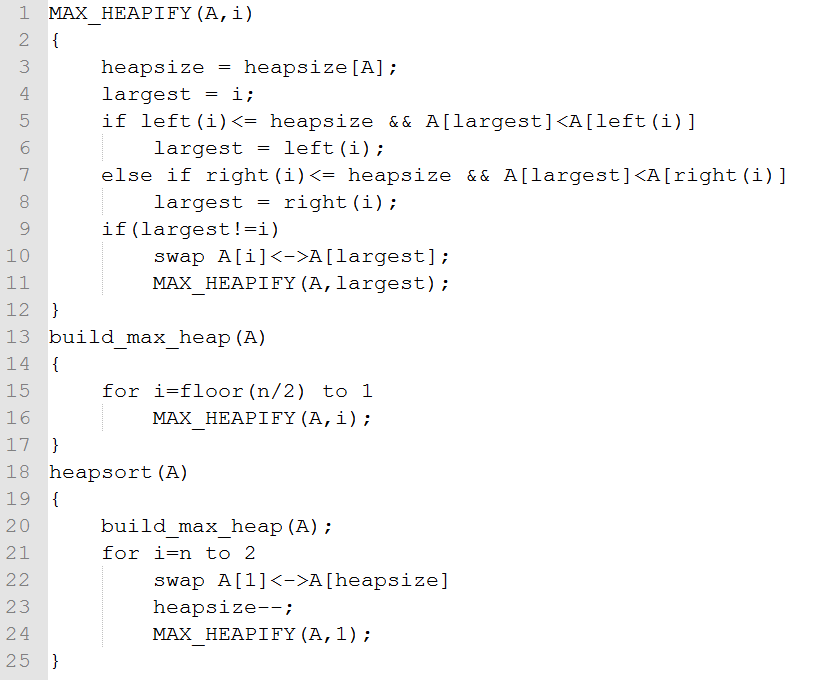
证明算法正确性:
(1)证明build_max_heap的正确性:
循环不变式:每次循环开始前,A[i+1]、A[i+2]、…、A[n]分别为最大堆的根。
初始:i=floor(n/2),则A[i+1]、…、A[n]都是叶子,因此成立。
保持:每次迭代开始前,已知A[i+1]、A[i+2]、…、A[n]分别为最大堆的根,在循环体中,因为A[i]的孩子的子树都是最大堆,因此执行完MAX_HEAPIFY(A,i)后,A[i]也是最大堆的根,因此保持循环不变式。
终止:i=0,已知A[1]、…、A[n]都是最大堆的根,得到了A[1]是最大堆的根,因此证毕。
(2)证明heapsort的正确性:
循环不变式:每次迭代前,A[i+1]、…、A[n]包含了A中最大的n-i个元素,且A[i+1]<=A[i+2]<=…<=A[n],且A[1]是堆中最大的。
初始:i=n,A[n+1]…A[n]为空,成立。
保持:每次迭代开始前,A[i+1]、…、A[n]包含了A中最大的n-i个元素,且A[i+1]<=A[i+2]<=…<=A[n],循环体内将A[1]与A[i]交换,因为A[1]是堆中最大的,因此A[i]、…、A[n]包含了A中最大的n-i+1个元素且A[i]<=A[i+1]<=A[i+2]<=…<=A[n],因此保持循环不变式。
终止:i=1,已知A[2]、…、A[n]包含了A中最大的n-1个元素,且A[2]<=A[3]<=…<=A[n],因此A[1]<=A[2]<=A[3]<=…<=A[n],证毕。
七、计数排序
特性:stable sort、out-place sort。
最坏情况运行时间:O(n+k)
最好情况运行时间:O(n+k)
当k=O(n)时,计数排序时间为O(n)
伪代码:
B[n]存放排序结果;C[k+1]提供临时存储区

算法的步骤如下:
1、找出待排序的数组中最大和最小的元素
2、统计数组中每个值为t的元素出现的次数,存入数组C的第t项
3、对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
4、反向填充目标数组:将每个元素t放在新数组的第C(t)项,每放一个元素就将C(t)减去1
例子:
假设数字范围在 0 到 9.
输入数据: 1, 4, 1, 2, 7, 5, 2
1) 使用一个数组记录每个数组出现的次数
Index: 0 1 2 3 4 5 6 7 8 9
Count: 0 2 2 0 1 1 0 1 0 0
2) 累加所有计数(从C中的第一个元素开始,每一项和前一项相加)
Index: 0 1 2 3 4 5 6 7 8 9
Count: 0 2 4 4 5 6 6 7 7 7
更改过的计数数组就表示 每个元素在输出数组中的位置
3) 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
例如对于: 1, 4, 1, 2, 7, 5, 2. 1 的位置是 2.
把1放在输出数组的第2个位置.并把计数减 1,下一个1出现的时候就放在了第1个位置。(方
向可以保持稳定)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
习题8.2-4
给出一个算法,使之对于给定介于0和k之间的n个整数进行预处理,并能在O(1)时间内,回答出输入的整数中有多少个落在区间[a..b]内。你给出的算法的预处理时间应为Θ(n + k)。
用一个数组C,记录小于或等于其每个下标的值的元素个数。C[b] - C[a-1]为落在区间内的元素个数。
#include <stdio.h>
#include <stdlib.h>
int count(int A[], int length, int k, int a, int b);
int main(){
int num, i, k, a, b, cnt;
printf("Input the k:\n");
scanf("%d", &k);
printf("Input the a and b:\n");
scanf("%d %d", &a, &b);
printf("Input the number of the elements:\n");
scanf("%d", &num);
int *array = malloc((num + 1) * sizeof(int));
printf("Input the element:");
for(i = 1; i <= num; i++){
scanf("%d", &array[i]);
}
cnt = count(array, num, k, a, b);
printf("The number of the elements which are in the [a..b] is %d\n", cnt);
return 0;
}
int count(int A[], int length, int k, int a, int b){
int *C = malloc((k + 1) * sizeof(int));
for(int i = 0; i <= k; i++)
C[i] = 0;
for(int j = 1; j <= length; j++)
C[A[j]]++;
for(int i = 1; i <= k; i++)
C[i] += C[i-1];
return C[b] - C[a-1] ;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
八、基数排序
本文假定每位的排序是计数排序。
特性:stable sort、Out-place sort。
最坏情况运行时间:O((n+k)d)
最好情况运行时间:O((n+k)d)
当d为常数、k=O(n)时,效率为O(n)
我们也不一定要一位一位排序,我们可以多位多位排序,比如一共10位,我们可以先对低5位排序,再对高5位排序。
引理:假设n个b位数,将b位数分为多个单元,且每个单元为r位,那么基数排序的效率为O[(b/r)(n+2^r)]。
当b=O(nlgn),r=lgn时,基数排序效率O(n)
比如算法导论习题8.3-4:说明如何在O(n)时间内,对0~n^3-1之间的n个整数排序?
答案:考虑n个三位数(即d=3)的基数排序,每个数字在0~n-1区间(即k=n)。总共有三次调用计数排序,每次花费O(n+k)=O(n+n)=O(n)时间,因此总时间为O(n)。
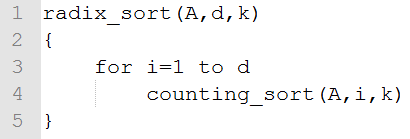
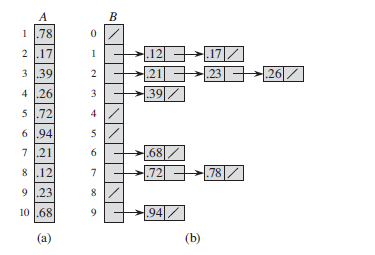
九、桶排序
假设输入数组的元素都在[0,1)之间。
特性:out-place sort、stable sort。
最坏情况运行时间:当分布不均匀时,全部元素都分到一个桶中,则O(n^2),当然[算法导论8.4-2]也可以将插入排序换成堆排序、快速排序等,这样最坏情况就是O(nlgn)。
最好情况运行时间:O(n)
桶排序的例子:
伪代码:

证明算法正确性:
对于任意A[i]<=A[j],且A[i]落在B[a],A[j]落在B[b],我们可以看出a<=b,因此得证。