目录
七、为什么VGG16网络结构不能构造的太深?ResNet是怎么解决这一问题的。
八、为什么引入非线性激励函数?写出饱和型激活函数、非饱和型激活函数有哪些,并写出各个激活函数的定义和特点。

一、目标检测一步法和两步法
一步法One stage目标检测算法:YOLO、RetinaNet、SSD等。
这种检测方式依赖于特征融合、Focal Loss等优秀的网络经验,可以将待检测物体的类型、大小、形状、可能出现的位置通过算法网络结构一次性检测出来,多用于对检测速度要求较高的情况,例如运动的物体或是流水线上的物件等。该方法将检测问题完全的回归处理,可以满足实时性要求,实用性较高,速度一般比两阶网络更快,但精度相比两步法较差。
两步法Two stage目标检测算法:R-CNN、Fast R-CNN、Faster R-CNN 等。
这种检测方式对物体进行检测时需要两个步骤,首先对待检测物体感兴趣的区域进行框选,得到建议框,保证足够的准召率,然后通过检测算法对建议框进行分类,寻找更精确的位置,这种检测方式常用于对检测速度要求不高的领域,如固定的或静止的成型磨具。其检测精度较一步法高,但实时性较一步法差。
二、锚框(Anchor)
Anchor最早出现在Faster RCNN中,其本质上是一系列大小宽高不等的先验框,均匀地分布在特征图上,利用特征去预测这些Anchors的类别,以及与真实物体边框存在的偏移。Anchor相当于给物体检测提供了一个梯子,使得检测器不至于直接从无到有地预测物体,精度往往较高,常见算法有Faster RCNN和SSD等。
三、深度学习检测器
1.发展历程
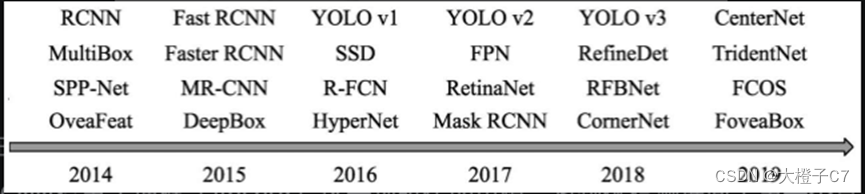
2.评价指标
(1)IoU:
对于具体的某个物体,可以从预测框与真实框的贴合程度来判断检测的质量,通常使用IoU(Intersection of Union)来量化贴合程度。
IoU的计算方式:两个边框的交集与并集的比值。IoU的取值区间是[0,1],IoU值越大,表明两个框重合越好。
(2)mAP:
对于一个检测器,通常使用mAP(mean Average Precision)这一指标来评价一个模型的好坏。AP指的是一个类别的检测精度,mAP则是多个类别的平均精度。评测需要每张图片的预测值与标签值,对于某一个实例,二者包含的内容有:
- 预测值(Dets):物体类别、边框位置的4个预测值、该物体的得分。
- 标签值(GTs):物体类别、边框位置的4个真值。
四、深度学习在计算机图像领域的主要任务:
(1)图像分类: 对出现在某幅图像中的物体做标注。
(2)目标检测: 输入测试图片,输出检测到的物体类别和位置。
(3)目标分割: 对图像中的特定物体按边缘进行分割。
(4)图像生成
五、Bounding Box Regression的原理
目标检测过程中对产生的候选框以标注好的真实框为目标进行逼近的过程。由于一幅图像上的框可以由中心点坐标(Xc,Yc)和宽w、高H唯-确定,所以这种通近的过程可以建模为回归问题。
通过边框回归可以实现一种“微调”的策略,将预测框尽量调整到与真实框近似,以提高模型预测的结果。
边框回归通常的思路是:平移 +尺度收缩。先做平移使得框中心尽可能重合,然后进行尺度缩放,使面积接近。
将上述原理利用数学符号表示如下: 在给定一组候选目标框P=(Px,Py,Pw,Ph),寻找到一个映射f,使得f(Px,Py,Pw,Ph)=(Gx^,Gy^,Gw^,Gh^)并且(Gx^,Gy^,Gw^,Gh^)≈(Gx,Gy,Gw,Gh)。其中G表示真实目标框,G^表示边界回归算法预测目标框。
参考文章:
边框回归(Bounding Box Regression)详解_南有乔木NTU的博客-CSDN博客_bounding box regression
六、卷积和池化操作各自的特点
卷积的特点:“局部感知,参数共享”的特点大大降低了网络参数,保证了网络的稀疏性,防止过拟合。
池化的特点: 降低模型过拟合; 平移不变性,即如果物体在图像中发生一个较小的平移(不超过感受野),那么这样的位移并不会影响池化的效果,从而不会对模型的特征图提取发生影响。
七、为什么VGG16网络结构不能构造的太深?ResNet是怎么解决这一问题的。
(1)AlexNet、VGG等这些比较主流的网络都是简单的堆叠层,比较明显的现象是,网络层数越深,识别效果越好。但事实上,当网络层数达到一定深度时,准确率就会达到饱和,然后迅速下降,出现网络退化问题。由于反向传播算法中的链式法则,如果层层之间的梯度均在(0,1)之间,层层缩小,那么就会出现梯度消失。反之,如果层层传递的梯度大于1,那么经过层层扩大,就会出现梯度爆炸。所以,简单的堆叠层将不可避免的出现网络退化现象。
(2)ResNet引入了残差模块,解决了层次比较深时无法训练的问题。它将输入中的一部分数据不经过神经网络,而直接进入到输出中。这样来保留一部分原始信息,防止反向传播时的梯度弥散问题,从而使得网络深度一举达到152层。ResNet 的初衷就是让网络有恒等映射的能力,能够在加深网络的时候,至少能保证深层网终的表现至少和浅层网络持平。
八、为什么引入非线性激励函数?写出饱和型激活函数、非饱和型激活函数有哪些,并写出各个激活函数的定义和特点。
激活函数(Activation Function),就是在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端,引入激活函数是为了增加神经网络模型的非线性。
(1)非线性变换是深度学习有效的原因之一。原因在于非线性相当于对空间进行变换,变换完后相当于对问题空间进行简化,原来线性不可解的问题现在变得可解了。如果不用激励函数,在这种情况下每一层输出都是上层输入的线性函数,这样无论神经网络有多层,输出都是输入的线性组合,与没有隐藏层相当,即是最原始的感知机,那么网络的逼近能力就相当有限。
(2)激活函数分为两类,饱和激活函数和非饱和激活函数。
饱和激活函数:sigmoid、tanh;
非饱和激活函数:ReLU、PReLU、Leaky ReLU、RReLU、ELU等。
参考文章:
常用激活函数(激励函数)理解与总结_人工智能_tyhj_sf-DevPress官方社区 (csdn.net)
九、防止过拟合的主要方法
(1)加入正则化项,参数范数惩罚: 给需要训练的目标函数加上一些规则限制。
(2)数据增强,增加样本数量: 让模型泛化的能力更好的办法是使用更多的训练数据进行训练。可人为创造一些数据加到训练集中。
(3)提前终止(early stopping):随着模型的能力提升,训练集的误差会先减小再增大,可以提前终止算法,缓减过拟合现象。
(4)dropout:可以作为训练深度神经网络的一种trick供选择。在每次训练批次中,通过忽略一半的特征检测器,可明显地减少过批合现象。
(5)Batch Normailization:BN 进行了归一化,让输出遵从(0,1)正态分布,从而让输入在激活函数中处于线性部分,帮助网络更快拟合。
(6)训练时间: 选择合适的学习率和学习轮次。
(7)参数绑定与参数共享。
参考文章:
深度学习知识点全面总结_GoAI的博客-CSDN博客_深度学习总结
注:
本文是学习所参考文献与资料后的归纳与总结,仅作学习记录,如有错误,欢迎大家指正与交流。