PReLU简介
PReLU(Parametric Rectified Linear Unit), 顾名思义:带参数的ReLU。二者的定义和区别如下图:
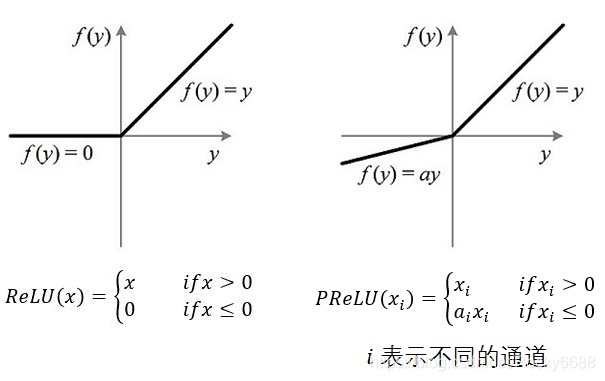
如果ai=0,那么PReLU退化为ReLU;如果ai是一个很小的固定值(如ai=0.01),则PReLU退化为Leaky ReLU(LReLU)。 有实验证明,与ReLU相比,LReLU对最终的结果几乎没什么影响。
PReLU的几点说明
(1) PReLU只增加了极少量的参数,也就意味着网络的计算量以及过拟合的危险性都只增加了一点点。特别的,当不同channels使用相同的ai时,参数就更少了。
(2) BP更新ai时,采用的是带动量的更新方式,如下图:

上式的两个系数分别是动量和学习率。
需要特别注意的是:更新ai时不施加权重衰减(L2正则化),因为这会把ai很大程度上push到0。事实上,即使不加正则化,试验中ai也很少有超过1的。
(3)常初始化为0.25。
