
笔记整理:王贵涛,东南大学硕士,研究方向为自然语言处理
链接:https://github.com/UIC-Liu-Lab/CPT
一、动机
克服灾难性遗忘(CF)是持续学习(CL)的一个主要目标。目前有许多方法,例如基于正则化的方法、基于重放的方法以及基于参数隔离的方法。从头开始训练一个大型的语言模型是非常困难且昂贵的。在领域的最终任务微调之前,使用一个大的未标记领域语料库进行后训练(Post Training),即领域自适应预训练或预微调,可以比直接微调预训练模型获得更好的结果。使用语言本身不断变化的发展,社会事件和来自不同领域的知识来逐步更新语言数据变得越来越重要。由于人类在增量学习方面非常有效,如果能够很少或不被遗忘地模仿这种人类能力,将显著推动人工智能研究的发展。
二、贡献
本文提出了利用未标记域语料库序列增量后训练语言模型,在不忘记其现有知识的情况下不断扩展语言模型的问题。其目标是提高这些领域的少镜头最终任务学习。由此产生的系统被称为CPT(持续后训练)。
三、方法
本研究提出方法CPT(Continual Post Training),是一种用于后训练的CL系统。从预训练的多模态模型开始,使用未标记的语料库对域序列的多模态进行后训练。一旦一个任务被训练好了,它的数据就不再可访问了。在任何时候,所产生的持续训练后的多模态模型都可以被训练领域中的最终任务所使用。这是在CL的任务增量学习设置中,当稍后需要使用任务的学习模型时,提供任务ID 。
CPT对多模态模型进行持续的后训练,通过插入到预训练模型的每个transformer层中的两个持续学习插件(称为CL插件)的模块来实现的。CL插件的灵感来自于适配器。虽然适配器可以隔离不同的任务,但需要为每个任务分配一个新的适配器,并且在不同任务的适配器之间不能共享任何知识。然而,CL插件是一个持续学习系统,它可以通过所有领域共享的适配器来学习一系列任务。图1给出了添加到预训练模型中的两个CL插件的CPT架构。
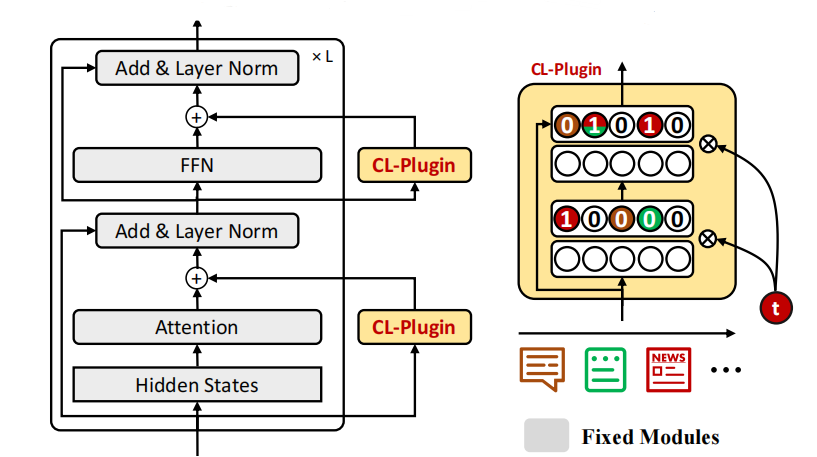

图1 加入CL插件的CPT结构
在后训练任务中,只训练两个CL插件。原始预训练过的多模态模型的组成部分是固定的。而在最终任务的微调中,所有组件都是可训练的。CL插件是一个带有任务掩码机制的双层全连接网络。它需要两个输入:来自transformer层的前馈层的隐藏状态和任务增量学习所需的任务ID 。在一个CL插件中,任务掩码表示特定于任务的神经元,用于处理CF。由于任务掩码是可微的,所以整个CPT可以进行端到端训练。
学习新领域包括两个主要步骤:(1)学习领域 及其掩码,以供将来使用。(2)在每个旧任务的每一层应用掩码,阻止梯度流,保护旧任务的模型。
(1)学习任务掩码以克服CF。在学习每个任务 时,在CL插件中的每一层上训练一个伪二进制掩码 ,表明对该任务很重要的神经元,借用硬注意的想法,并利用任务ID嵌入来训练掩码。对于任务ID ,其嵌入 由可微的确定性参数组成,可以与网络的其他部分一起学习。为了从 中生成任务掩码 ,使用Sigmoid作为一个伪门(掩码)函数。 的计算方法如下:
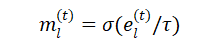
其中 τ 是一个温度变量,从1线性退回到 τ 。
在正向传递中,给定每个层的输出 ,按对应元素乘以掩码 :
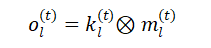
CL插件中最后一层的掩蔽输出 通过跳跃连接输入到多模态预训练模型的下一层。在学习任务 之后,保存最终的 并添加到集合{ }中。
(2)应用任务掩码。在学习新任务 之前,首先在所有旧任务iprev的每一层神经元上积累并设置掩码 ,这样在反向传播中,任务 的梯度 就不会流向这些神经元。由于 是伪二进制,使用最大池化来实现积累和条件梯度:
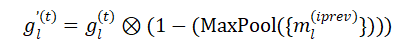
与MaxPool({ })中的1项对应的梯度被设置为0以阻止梯度流,而其他梯度保持不变。这样,旧任务中的神经元就受到了保护。
四、实验
本文使用四个未标注的领域数据集:Yelp Restaurant (Xu et al., 2019), AI Papers (Loet al., 2020), ACL Papers (Lo et al., 2020), AGNews (Zhang et al., 2015) 及其4个相应的最终任务分类数据集。
本文使用6个非持续学习方法和7个自适应的持续学习方法作为基线。
非持续学习基线包括:(1) RoBERTa;(2)Adapter,直接微调预训练模型或适配器;(3) RoBERTa-ONE;(4)Adapter-ONE;(5)Prompt-ONE,使用单独的网络为每个任务建立一个模型,没有知识转移或灾难性遗忘。(6)DEMIX,为每个任务训练一个单独的适配器,并从其之前最相似的先前任务适配器初始化适配器。
7个适应的持续学习基线包括(7) RoBERTa-NCL和(8)Adapter-NCL,一个接一个对领域进行后训练,没有处理灾难性遗忘和转移的机制。其他的是最先进的持续学习基线,调整以适应持续的后训练。
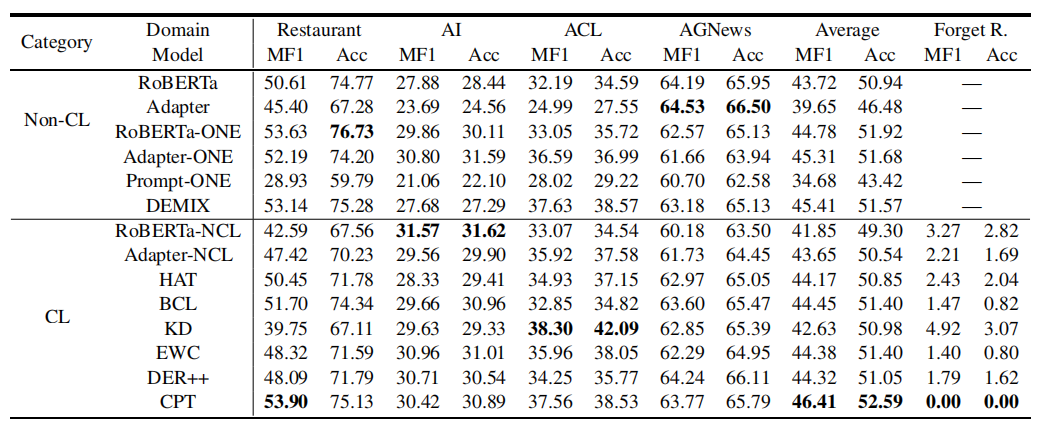
实验结果如1表所示:
表1 实验结果
五、总结
本文提出了利用未标记域语料库连续对具有域序列的语言模型进行后训练。并提出了一种有效的计算方法(CPT)。来自任何领域后训练的最终任务都可以微调生成的语言模型。实验结果证明了CPT的有效性。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。