
笔记整理:徐欣,浙江大学硕士
链接:https://arxiv.org/pdf/2303.08559.pdf
简介
本文探究了大型语言模型 (LLMs)和微调的小型预训练语言模型(SLMs)在少样本信息抽取(IE)任务上的表现。本文发现LLMs在IE任务上表现不佳,同时存在高延迟和高开销的缺点,但是LLMs擅长处理对SLMs困难的样本。由此,本文提出了适应性的filter-then-rerank范式,SLMs作为过滤器,LLMs作为重排工具。
构建少样本数据集
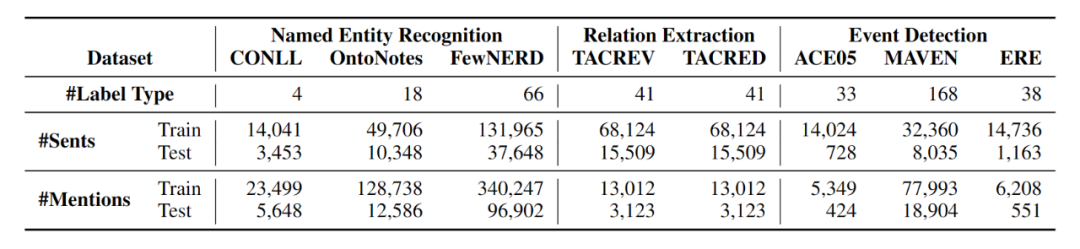
本文在命名实体识别(NER)、关系抽取(RE)和事件检测(ED)三个任务的8个数据集上进行了实验,原数据集统计如上表所示。本文采用K-shot采样,对于NER和ED,K=1,5,10,20;对于RE,K=1,5,10,20,50,100。如果K-shot数据集包含大于300个句子,按1:9分出验证集和训练集;如果小于300个句子,则使用5折交叉验证,避免过拟合。对于NER和ED随机采样250个句子作为测试集,对于RE,随机采样500个句子作为测试集。本文采用Micro F1作为评价指标,所有试验5次随机尝试取平均结果。
微调小模型
本文采用的小模型为RoBERTa-large(基于抽取的方法)和T5-large(生成式),使用以下4种有监督方法:
(1)微调 (FT):在SLMs添加一个分类头用于预测每个句子/词的标签
(2)FSLS [1]:少样本NER和ED
(3)KnowPrompt [2]:少样本RE
(4)UIE [3]:生成式的少样本信息抽取
大型语言模型:
本文通过预实验发现CODEX(code-davinci-002)比GPT3.5(text-davinci-003)在少样本IE上表现更好,因此本文实验全部使用CODEX完成。本文使用以下4种方法利用LLMs:
(1)In-context learning (ICL)
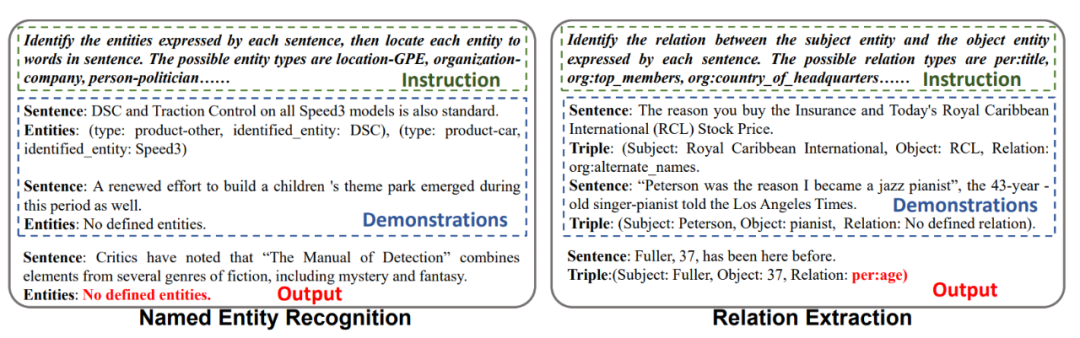
Prompt实例如下图,由instruction,demonstrations和question组成,实验中随机选择少样本训练集中的样本作为demos。
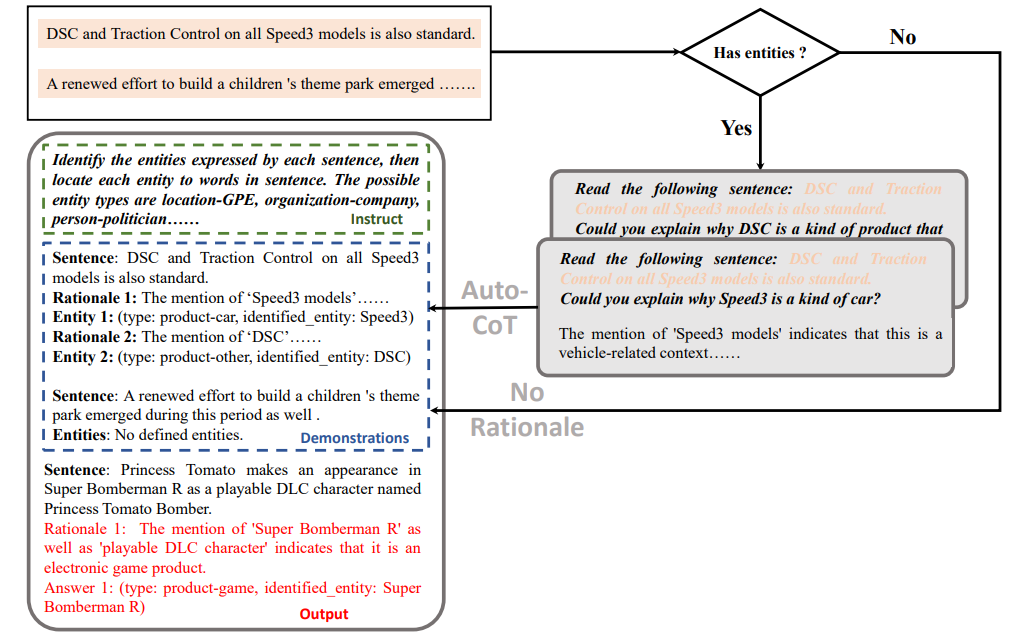
(2)ICL + Auto CoT
将大模型产生的Rationale插入demonstrations,如下图所示:
(3)ICL + demo筛选 (DS)
从训练集中选取和测试样本embedding相似的训练样本作为demonstrations。
(4)ICL + Self-ensemble (SE)
对每个测试样本预测多次,取出现次数最多的预测结果作为最终答案。
实验
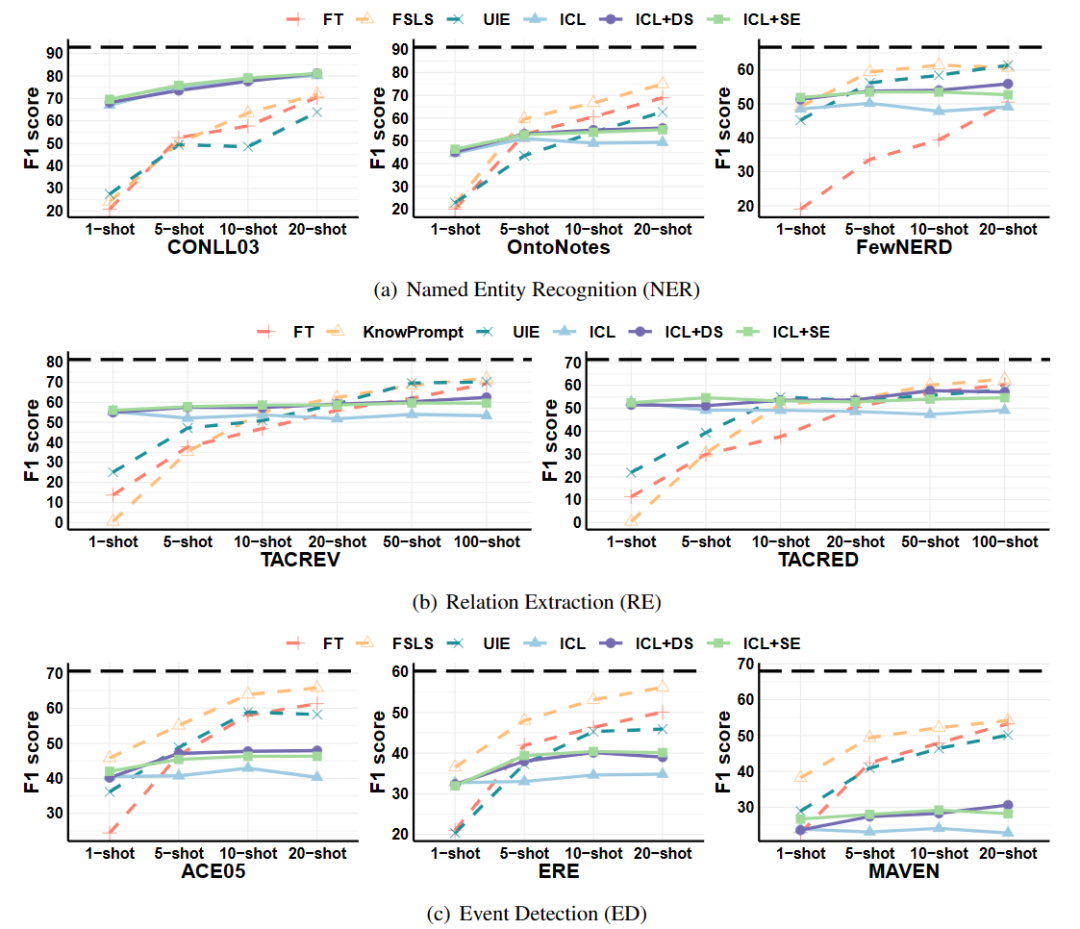
从上图可以看出,ICL中普通ICL最差,因为demonstrations的长度受到LLMs最大输入长度的限制,同时增加demonstrations中的样本数并没有更好的效果,超过一个阈值后performance会处于停滞状态。总体而言,LLMs不是一个好的少样本信息抽取工具。1-shot下LLMs比SLMs表现好,5-10 shot下LLMs和SLMs差不多,使用更多的训练数据后,SLMs比LLMs好,因为SLMs可以基于训练数据微调。对于复杂的ED任务,SLMs总是比LLMs好。
Filter-then-rerank 范式
基于上述实验,本文提出了Filter-then-rerank范式。小模型用作过滤器,删除预测结果中probability极低的labels,保留top-N个候选labels,大模型对这N个labels进行重新预测。作者修改了原任务的prompt形式为多项选择问题,将这N个labels作为选项输入到LLMs中,如下图所示:

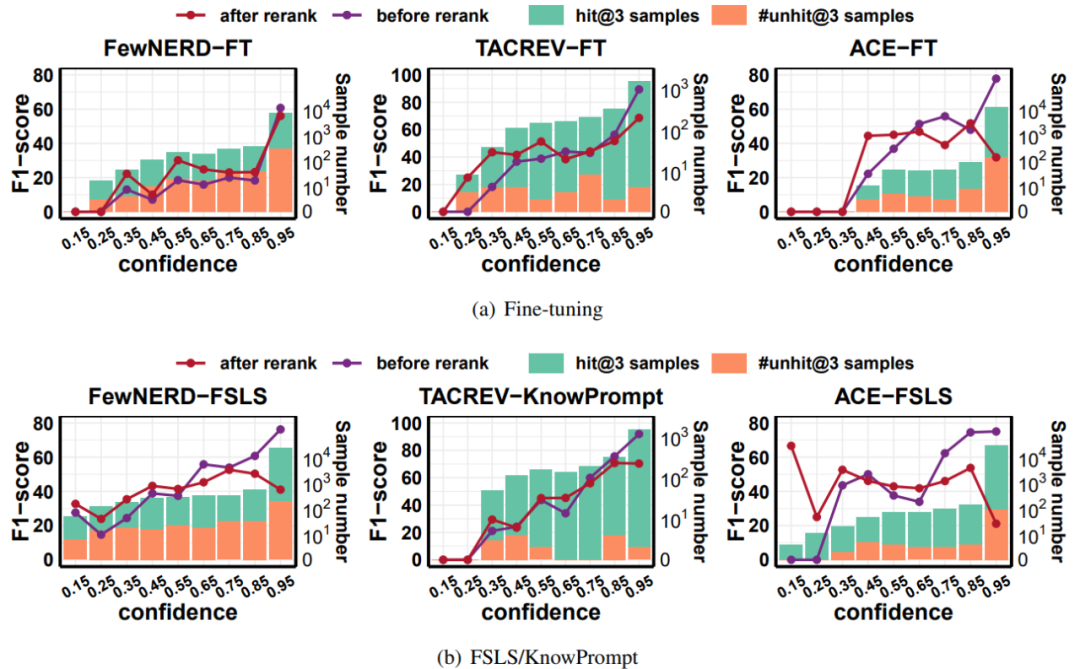
上图实验结果表明,rerank之后,对于SLMs来说置信度低的样本,LLMs表现更好。因此,LLMs比SLMs更擅长处理需要外部知识或者复杂推理的困难样本。于是作者提出仅仅让LLMs rerank那些对于SLMs困难的样本,设计了适应性的filter-then-rerank范式,如下图所示,首先利用有监督训练SLMs并预测测试样本。设定一个confidence score阈值,高于阈值的用SLMs的预测作为最终结果。低于阈值的选top-N个predictions作为多项选择输入给LLMs重排,这里的threshold通过最大化验证集的F1适应性地决定。

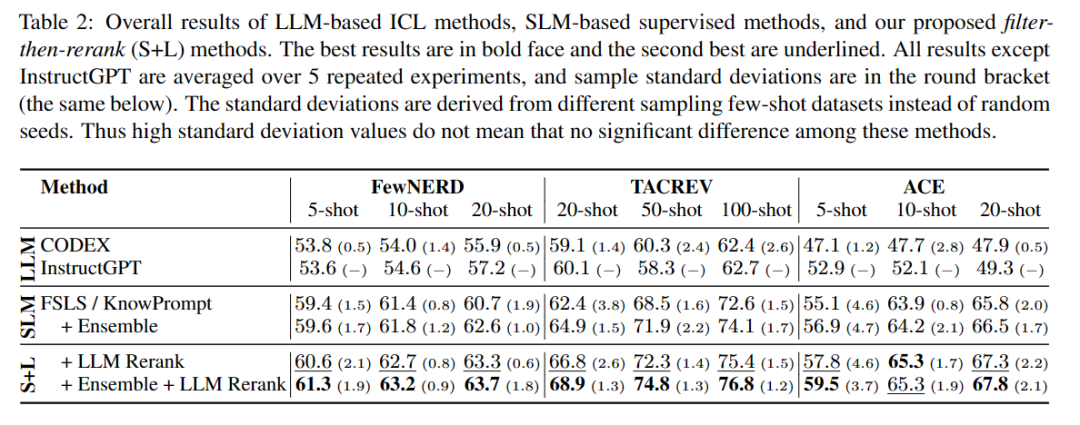
适应性的过滤再重排范式的实验结果如下表,可以看出此范式是非常高效的。
总结
1. 因为任务形式和受限的demo数量,LLMs并不擅长少样本信息抽取;
2. 与SLMs相比,LLMs有较高时间和金钱开销;
3. LLMs可以通过filter-then-rerank范式帮助SLMs处理困难样本
参考文献
[1] Jie Ma, Miguel Ballesteros, Srikanth Doss, Rishita Anubhai, Sunil Mallya, Yaser Al-Onaizan, and Dan Roth. 2022. Label semantics for few shot named entity recognition. In Findings of the Association for Computational Linguistics: ACL 2022, pages 1956–1971, Dublin, Ireland. Association for Computational Linguistics.
[2] Xiang Chen, Ningyu Zhang, Xin Xie, Shumin Deng, Yunzhi Yao, Chuanqi Tan, Fei Huang, Luo Si, and Huajun Chen. 2022. Knowprompt: Knowledge aware prompt-tuning with synergistic optimization for relation extraction. In WWW ’22: The ACM Web Conference 2022, Virtual Event, Lyon, France, April 25 - 29, 2022, pages 2778–2788. ACM.
[3] Yaojie Lu, Qing Liu, Dai Dai, Xinyan Xiao, Hongyu Lin, Xianpei Han, Le Sun, and Hua Wu. 2022b. Unified structure generation for universal information extraction. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5755–5772, Dublin, Ireland. Association for Computational Linguistics.
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。